Overview
Metadata comes in many forms, covers a wide range of information, and supports innumerable use cases. Here I examine a particular journey with metadata: some of the kinds of information captured and why, where things broke down, and how those issues were addressed. The specific use case is admittedly idiosyncratic. Nevertheless, some of the specific lessons and techniques should be more generally applicable.
The data here are works of art: SVG generated from algorithms that almost always include some measure of randomization. Metadata serves four distinct purposes here:
-
Provenance: statements of copyright, components, editions
-
Retrieval: finding works with a certain characteristic
-
Comparison: understanding differences between works
-
Replication: providing enough information to replicate or produce a similar a work
Metadata is embedded into the work itself, using the SVG metadata element. The specific mechanics of how this happens is part of the overall story,
and has developed over time.
Background: The Problem Context
I write programs that make art. The programs bring together subcomponents of varying degrees of complexity plus new algorithms to explore various effects. The point of the work may be to explore or replicate patterns of growth and change, interesting mathematics, space filling curves or tilings, or patterns of colour and shape. Anything really. The algorithms almost always have some kind of random element and a range of tuning parameters. Sometimes bugs in the algorithm produce interesting or beautiful results, which means that even bug fixes may lead to additional parameterization.
The basic process of developing these programs is one of experimentation and tweaking.
The main workflow looks like this:
Figure 1: Basic Workflow Output from a process box labelled 
Image description
Main algorithm (XQuery)
consists of several tree shapes with the same colour. A selected tree is put through
a process box labelled Rendering (XSLT)
. The output of that consists of several variations of the same tree shape in different
colours and stylings. A selected tree is put through a process box labelled Publish
.
The main algorithm is implemented in XQuery. An experiment is run, producing randomized variations. These are emitted as domain-specific XML. A particular variation can be processed with XSLT with different stylesheet parameters to produce a variety of variations in SVG. In the course of a day there may be hundreds of these experiments, at both levels. Over the course of work on a particular project there may be thousands. Particular works are chosen for publication, which usually involves conversion to a binary image format with some tagging and descriptive contextualization. Some time later some of these works will be revisited, either to reuse some aspect in a new project or in a desire to put a new spin on an old project.
There are several problems that metadata helps solve for me:
-
How did certain randomized values and parameter settings contribute to a particular outcome?
-
What components and settings went into a particular work?
-
What works used a particular component or technique?
-
How can I sign this work?
-
How can I explain this work to others?
The goal may be an immediate one: tune the parameters to produce better outcomes. The goal may be part of an ongoing evolution: reproduce a similar effect in a new work. The goal may be retrospective and analytical: provide context for a published work, or find examples of a particular technique for in-depth discussion and explanation.
What is Metadata, Anyway?
An intrinsic definition of "metadata" is always going to be problematic. It is hard to find some inherent quality that we can point to that distinguishes data from metadata. An extrinsic definition fares no better. It is just as hard to create well-partitioned buckets: this kind of information is "metadata", that kind is "data". As the old saw goes, one man's metadata is another man's data. Data about data is metadata, right up to the point that you start wanting to analyze it. Publication date and the author name are "metadata", right up to the point where you create the chart of publication history by author.
Generally folks work with an operational definition: metadata defines a set of information to be used to find and organize some other set of information. The "metaness" is in the use of the metadata in relation to some other information. The question to ask, then, is not "what is metadata?" but "what is metadata for?"
NISO tells a basic story about metadata that is widely replicated. (See, for example,
the more elaborated description in Getty.) Metadata comes in three main types [1], with one of them (administrative) being an umbrella catch-all for "information needed
to manage a resource or that relates to its creation":
Figure 2: NISO's Taxonomy of Metadata Descriptive Information about the content of a resource that aids in finding or understanding
it, for discovery, display, or interoperability. Example properties:
Title Author Subject Genre Publication date Administrative: Technical Information about digital files necessary to decode and render them, for interoperability,
digital object management, and preservation. Example properties:
File type File size Creation date/time Compression schema Administrative: Preservation Information about digital files supporting the long-term
management and future migration or emulation of digital files for interoperability,
digital object management, and preservation. Example properties:
Checksum Preservation event Administrative: Rights Information about digital files detailing the intellectual property rights attached
to the content, for interoperability and digital object management. Example properties:
Copyright status License terms Rights holder Structural Information about digital files describing the relationship of parts of resources
to one another, for navigation. Example properties:
Sequence Place in hierarchy
This taxonomy slants towards a third-party metadata creator: someone standing between creation and use, between creation and distribution. This mirrors much of the discussion of metadata. It is from the perspective of either the archivist or the user of an archive: someone who comes along well after the process of creation is finished, to label and classify for others. There is much focus on standardized metadata properties (DublinCore) and archival formats, or best practices for interoperability and preservation (OAIS). To the extent that there is an account of metadata by, of, and for the creator themselves, it is lost in this mix.
Let's take a different slant on this and focus on the interests of the creator of a work. How does metadata fit into the creative process? What kind of statement is it making? Who is the audience? What is the point?
There are three kinds of tasks that metadata serves for the creator:
-
Signing the work
-
Organizing a collection of works
-
Creating new works based on old ones
Some metadata is about signing the work: declaring one's relationship to it as the
creator, along with key aspects of that relationship (when? how many editions? with
what rights?). More broadly, it is about the creator communicating with their audience.
A lot of the descriptive
metadata falls in this category, but so does much of the administrative: rights
metadata.
Some metadata is about organizing a collection of works: an aid in finding works with
particular characteristics. It labels and classifies. It asserts relationships between
works. It supports workflows such as creating a curated collection for publication
or explanation. This kind of metadata straddles the line: sometimes about the creator
in communication with themselves, sometimes with their audience or third party aggregators.
Some descriptive
and structural
metadata falls here, but so does some of the various administrative
metadata.
Some metadata captures details of the creation process so that similar creations can
be made, or as a baseline of information for creating derivative works. This kind
of metadata is about the creator communicating with themselves, as part of the overall
creative process. It isn't clear where this falls. Descriptive
? Administrative: technical
? Administrative: preservation
? Structural
? A little of each?
This is not to say that signature metadata might not be useful and used by the creator as part of the creative process, nor that process metadata might not be interesting to the audience. Far from it!
Figure 3: Creator-oriented Taxonomy of Metadata
|
Signature |
Assertions of authorship: either assertions of a relationship between the work and other entities, or assertions about the identity of the work itself, in context. Typically assertions by the author about the work or themselves in relation to it. The point: authorship, money, prestige, communication with the audience. Examples:
|
||||
|
Organizational |
Assertions about the work and its properties and classifications. The point: enable retrieval or analysis of the work based on those properties.
|
||||
|
Process |
Statements about the production of the work. The point: enable new creations based on this work or recreations of it or similar works.
|
The vast bulk of metadata I embed is process metadata, along with a little bit of signature and organizational metadata. Let's look at a concrete example.
Metadata, annotated
Here is some actual embedded metadata from one of my experiments, slightly redacted. Let's examine it in detail.
First up is the colophon
, a longer bit of descriptive text along with a copyright statement, all embedded
as the title of an SVG path that draws a signature. This is all signature metadata.
The signature is directly visible, while the rest pops up when the mouse hovers over
it.
<svg:path id="signature" style="fill:white;stroke-width:0.26"
d="m 7.58 181.6 c 0.51 -0.49 3.84 ..."
transform="scale(0.5,0.5)">
<svg:title>Copyright© ... 2022...
A #genuary work
Randomized flow field based on Perlin noise...
</svg:title>
</svg:path>
Here is a bit of variable process metadata: a couple of time stamps, the initial creation time and the time of stylesheet rendering.
<svg:metadata xmlns:svg="http://www.w3.org/2000/svg">
<metadata xmlns="http://mathling.com/art">
<created>2022-01-21T09:05:07.868096-08:00</created>
<processed>2022-01-21T09:23:01.901638-08:00</processed>
There follows a bit identifying text containing the project and variant tags, and a brief description from a subcomponent. These are organizational.
<description>genuary j21combine</description>
<description>genuary: Flow fields</description>
Parameters (name/value pairs) are named using poor man's namespaces: tags associated
with various components to avoid name collisions. Here we have j7 and knot, which reference the main subproject and a component for making modulated torus knots.
Using simple strings helps ease-of-use at the point where parameters are referenced
in projects or used in searches. This is all fixed process metadata: the point is
to capture aspects of the algorithm that generated this work. For example, the knots
used in this algorithm are all symmetric between the x and y coordinates (knot.p-same=100) and 15 percent of then are involuted (knot.p-involuted=15).
<component name="j7">
<parameter name="j7.field">adhoc</parameter>
<parameter name="j7.gradient">oxygen oxygen-reverse plasma</parameter>
<parameter name="j7.grid.size">200</parameter>
<parameter name="j7.obstruction.gradient">oxygen</parameter>
<parameter name="j7.obstruction.type">ellipse</parameter>
<parameter name="j7.obstruction.visibility">0</parameter>
</component>
<component name="knot">
<parameter name="knot.garden.fade">true</parameter>
<parameter name="knot.max-factors">3</parameter>
<parameter name="knot.openness">1</parameter>
<parameter name="knot.p-involuted">15</parameter>
<parameter name="knot.p-same">100</parameter>
<parameter name="knot.p-skewed">10</parameter>
<parameter name="knot.precision">1</parameter>
</component>
There are various standard canvas sizes and scalings, identified by name. The resolution "medium" is for 1600x1600 images. This is a bit of intrinsic metadata, because the actual canvas size is manifest in the image.
<parameter name="resolution">medium</parameter>
An "algorithm" is a randomization algorithm. Because we have an explicit descriptor for these rather than pure code, it is possible to report on the randomizers being used in a structured fashion. Again, we're using the poor man's namespace technique to keep randomizers from different components separated. This is all fixed process metadata.
<component name="j7">
<algorithm name="j7.density" distribution="normal"
min="0.1" max="0.9"
mean="0.6" std="0.1"/>
<algorithm name="j7.drop.percent" distribution="constant"
min="5"
cast="integer"/>
<algorithm name="j7.obstruction.n" distribution="constant"
min="0"
cast="integer"/>
<algorithm name="j7.line.length" distribution="uniform"
min="16" max="32"/>
<algorithm name="j7.line.width" distribution="zipf"
alpha="1.01"
max="16"
post-multiplier="1"
cast="integer">
<sums>0.294431920541423 0.440198890360574 0.5371753519488989 ...</sums>
</algorithm>
</component>
<component name="knot">
<algorithm name="knot.p" distribution="uniform"
min="3" max="11"
cast="integer"/>
<algorithm name="knot.q" distribution="uniform"
min="2" max="5"
cast="integer"/>
<algorithm name="knot.r" distribution="uniform"
min="-1" max="1"
cast="decimal"/>
<algorithm name="knot.x-y-same" distribution="flip" p="100"/>
<algorithm name="knot.skewed" distribution="flip" p="10"/>
<algorithm name="knot.involution" distribution="flip" p="15"/>
<algorithm name="knot.stretch" distribution="normal"
mean="1" std="0.5"
min="0.5" max="2"
cast="decimal"/>
<algorithm name="knot.n-factors" distribution="uniform"
min="2" max="3"
cast="integer"/>
</component>
<component name="flowfield">
<algorithm name="flowfield.blend.fraction" distribution="uniform"
min="0" max="1"/>
<algorithm name="flowfield.obstruction.angle" distribution="uniform"
min="0" max="90"
cast="integer"/>
<algorithm name="flowfield.obstruction.size" distribution="zipf"
alpha="0.5"
max="7"
cast="integer">
<sums>0.2287577393348463 0.5225872304516045 0.6369661001190277 ...</sums>
</algorithm>
<algorithm name="flowfield.noise.scale" distribution="multimodal"
min="0.0001" max="0.1">
<algorithm name="1" distribution="normal" mean="0.001" std="0.0005"/>
<algorithm name="2" distribution="normal" mean="0.01" std="0.005"/>
</algorithm>
<algorithm name="flowfield.obstruction.ratio" distribution="normal"
mean="3" std="0.5"
min="0.1" max="10"/>
</component>
Stylesheets have their own set of parameters. There are stylesheet-level components as well, which are identified through introspection. The XML representation passed to the stylesheet made use of three identified stylesheet components: polygons, paths, and graphs. The relevant parameters will only be reported here if the XML contains constructs relevant to those components.
<stylesheet-parameters>
<component name="polygon">
<parameter name="polygon.fill"/>
<parameter name="polygon.opacity"/>
<parameter name="polygon.filter"/>
<parameter name="polygon.gradient"/>
</component>
<component name="path">
<parameter name="path.filter"/>
<parameter name="path.fill">none</parameter>
<parameter name="path.opacity"/>
</component>
<component name="graph">
<parameter name="graph.fill"/>
<parameter name="graph.opacity">1</parameter>
<parameter name="graph.filter"/>
<parameter name="graph.edge-mode">graph</parameter>
<parameter name="graph.gradient"/>
<parameter name="sand.grains">10</parameter>
<parameter name="sand.size">2</parameter>
</component>
These parameters were selected via the randomization algorithms at run time. Here
the specific values selected are reported, so this is variable process metadata. For
example, j7.density was generated from the j7.density randomizer reported previously. Multiple values for j7.flow.swirliness were selected, and we get a report on each. They aren't really "stylesheet" parameters:
it is an artifact of the generation that causes them to be reported here.
<component name="j7">
<dynamic-parameter name="j7.density">0.67</dynamic-parameter>
<dynamic-parameter name="j7.points.n">1075</dynamic-parameter>
<dynamic-parameter name="j7.steps.n">70</dynamic-parameter>
<dynamic-parameter name="j7.line.length">32</dynamic-parameter>
<dynamic-parameter name="j7.line.width">1</dynamic-parameter>
<dynamic-parameter name="j7.drop.percent">5</dynamic-parameter>
<dynamic-parameter name="j7.flow.center.1">1321,657</dynamic-parameter>
<dynamic-parameter name="j7.flow.swirliness.1">360</dynamic-parameter>
<dynamic-parameter name="j7.flow.center.2">435,524</dynamic-parameter>
<dynamic-parameter name="j7.flow.swirliness.2">720</dynamic-parameter>
<dynamic-parameter name="j7.flow.center.3">1574,618</dynamic-parameter>
<dynamic-parameter name="j7.flow.swirliness.3">180</dynamic-parameter>
</component>
Not all the stylesheet properties have been componentized. This is an ongoing bit
of refactoring work. The dividing line between process metadata and intrinsic organizational
metadata gets a little murky at this point. These parameters generally control details
of the final appearance, and as such they end up being manifest in the result. For
example, background-fill controls the background colour, which is certainly manifest in the result, so the
report of it explicitly makes it intrinsic metadata.
<parameter name="debug">false</parameter>
<parameter name="palettes">oxygen oxygen-reverse plasma</parameter>
<parameter name="effects"/>
<parameter name="signed">true</parameter>
<parameter name="signature.colour">white</parameter>
<parameter name="stroke-class"/>
<parameter name="stroke-cap">round</parameter>
<parameter name="stroke-join">round</parameter>
<parameter name="stroke-opacity">1</parameter>
<parameter name="stroke-fill"/>
<parameter name="stroke-filter"/>
<parameter name="default-stroke-width">2</parameter>
<parameter name="max-stroke-width">500</parameter>
<parameter name="background-fill">black</parameter>
<parameter name="background-opacity">1</parameter>
<parameter name="background-filter"/>
<parameter name="body-fill"/>
<parameter name="body-opacity"/>
<parameter name="body-filter"/>
<parameter name="body-reach"/>
<parameter name="dot-shape">circle</parameter>
<parameter name="dot-fill">black</parameter>
<parameter name="dot-opacity">1</parameter>
<parameter name="dot-size">3</parameter>
<parameter name="dot-filter"/>
<parameter name="box-fill"/>
<parameter name="box-opacity">1</parameter>
<parameter name="box-filter"/>
<parameter name="shape-fill"/>
<parameter name="shape-opacity">1</parameter>
<parameter name="shape-filter"/>
<parameter name="text-size">20</parameter>
<parameter name="colours.1.gradient">plasma</parameter>
<parameter name="colours.2.gradient"/>
<parameter name="colours.3.gradient"/>
<parameter name="colours.4.gradient"/>
<parameter name="colours.5.gradient"/>
<parameter name="colours.6.gradient"/>
<parameter name="colours.7.gradient"/>
<parameter name="colours.8.gradient"/>
<parameter name="colours.9.gradient"/>
<parameter name="colours.10.gradient"/>
</stylesheet-parameters>
</metadata>
</svg:metadata>
Process metadata that captures details of the generation and styling allows me to go back to an experiment later (perhaps months later) and answer the basic question of how the image was made and what settings I can use to create a similar image. Organizational metadata allows me to search for works of particular kinds, and helps with writing up contextual information when I publish particular works. And signature metadata allows me to assert authorship and copyright for published works, give them titles, and so forth.
The notion of capturing process metadata is not new. Lubell, for example, talks extensively about the importance of capturing metadata around the process of creation, although the focus of that work is more about the long-term preservation and archiving of such information.
Embedded metadata works better for me than external metadata because it can't get disassociated from the work. It enables workflows that amount to "look at image, examine information about how image was made, make new image using the same components based on those settings". The mechanics of capturing and embedding metadata can get complicated, particularly for certain more elaborate creation workflows. Let's look at what some of the issues are that I encountered on this journey, and lessons learned in addressing them.
Lessons Learned
Lesson: Embed Metadata as Part of Creation Process
The first lesson is to embed metadata into the works as part of the process of creation. By making metadata part of the process up front, it is more likely to happen reliably. When metadata is embedded rather than created separately, it is less likely to become separated from the work, and is ready to hand for use.
Without concrete action, a digital artwork is unsigned. I find this unsatisfactory. I want it to be signed. I want it to have a copyright statement embedded within it. It is really very important that signature metadata not be lost, no matter where the work travels. For digital artwork, screen-scraping robots putting other people's work up for sale as NFTs is a significant problem. They can certainly strip embedded metadata too, but at least it gives them another hurdle to cross.
First I constructed an SVG path representing my signature with the help of a drawing
tool (InkScape). Then I added some templates and stylesheet parameters to control where the signature
appears as well as its scaling and colouring. I attach a copyright statement plus
a free-form textual description of the work as the SVG title of the signature, so that hovering over the signature brings it up. The main template
for the root element calls the appropriate templates to define the define and place
the signature so that it appears on top of the rendering. A standard colophon function
provides this free-form text.
Embedding the rest of the metadata is more straightforward. The output of the XQuery phase is a domain specific XML vocabulary. Embedding metadata into that output is trivial: just add metadata to the output, wrapped in a new element in the vocabulary.
Figure 4: Example: Manually Adding Metadata (XQuery)
declare variable $N as xs:integer external;
...
declare function this:make-some-art()
{
let $scale := 3.2
let $kind := "tree"
let $result := this:something-cool($N, $scale, $kind)
return (
<art:canvas>
<art:metadata>
<art:parameter name="n">{$N}</art:parameter>
<art:parameter name="scale">{$scale}</art:parameter>
<art:parameter name="kind">{$kind}</art:parameter>
</art:metadata>
{$result}
</art:canvas>
)
};
The output of the XSLT phase is SVG, also an XML vocabulary, so embedding metadata
in that output is also trivial: adding a template for the metadata element that copies it into the svg:metadata element along with whatever else needs embedding at the stylesheet level.
Figure 5: Example: Manually Adding Metadata (XSLT)
<xsl:template match="art:metadata">
<svg:metadata>
<art:metadata style="display:none">
<xsl:copy-of select="node()"/>
<art:stylesheet-parameters>
<art:parameter name="fish.brush">
<xsl:value-of select="fish.brush"/>
</art:parameter>
<art:parameter name="default-stroke-width">
<xsl:value-of select="default-stroke-width"/>?
</art:parameter>
<art:parameter name="background-fill">
<xsl:value-of select="background-fill"/>?
</art:parameter>
</art:stylesheet-parameters>
</art:metadata>
</svg:metadata>
</xsl:template>
Lesson: Names for Everything
Names come into play in two ways: the names for the metadata fields and the use of names as the contents of metadata fields. Both are important.
It is easy to focus on the content of a metadata field, but the field name is important too. Field names are how we relate metadata to the source data. When it comes to process metadata, we need to relate those names to things happening in the process that produced the works. When it comes to process metadata, so much is idiosyncratic. Having a naming system so that it is easy to figure out where to look and spot similarities and differences between different processes and their generated works becomes crucial.
Using names for the contents of the metadata fields is helpful as well. Naming conventions can be used to identify standard ways of modifying or combining behaviours, which helps with metadata linkage, ease of implementation, and ease of experimentation. The more things in the process have readily identifiable names, the easier the association between metadata and the source process gets.
For example, SVG allows for complex filter effects. Rather than just create explicit
SVG code when I use them, I have names for some basic effects and a naming scheme
for combining or modifying them. Thus the name softbloom·khaki-filigree names an SVG filter that combines the filter named filigree, modified to use khaki coloured lighting, with the SVG filter named softbloom, which is the bloom filter modified for a prespecified narrower range.
Notice how a system that makes capturing process metadata easier also has the effect of making the implementation of the process itself easier. To both enable and document complex behaviour, it need only be named.
Figure 6: Abstract Trees

Image description
Abstract trees. Circles filled with intricate filigrees act as leaves. The leaves
are rendered with the softbloom·khaki-filigree filter.
A similar scheme is in play for colour gradients. I have a library of base (named)
gradients, and a naming system for creating variations of them. Thus oasis names a particular colour palette, oasis-slant orients that gradient on a diagonal, and oasis-outflow creates a circular gradient from it, and so on. Reporting the colour scheme of an
image in the metadata reduces to reporting such names. On the field name side, a consistent
naming convention help keep things clear: xxx.gradient identifies the gradient used for the component xxx.

Image description
Rectangles filled with colour gradients: straight, slanted, and in a bullseye pattern.
Providing names for everything helps with accessibility also: during the publication
phase alternative text can be written based on the named components and visual elements.
For example, Figure 6 uses a branching component, the aforementioned softbloom·khaki-filigree effect for the leaf components which have the shape kind circle. There is a turbidity-outflow gradient for the background. This information can be readily translated into a useful
textual description.
Lesson: Use Descriptors for Coherent Pieces of Behaviour
An important aspect of these generative art pieces is randomness, and different random distributions are used for different effects. For example, a normal distribution might be nice for how close one visual element is to another; a Zipf distribution for how large the components should be. Tweaking these distributions is a large part of the experimental process. What should the mean be? Should there be a maximum value? To understand how to replicate a piece, or what the difference is between a good outcome and a bad one, it is important to have a report on the random distributions used in their production.
The solution to this problem, which has the double benefit of making tweaking the distributions easier, is to use descriptors of the distributions and one generic function that knows how to interpret them and another than knows how to dump out a structured description suitable for inclusion in the metadata.
Figure 7: Example: Random Distribution Descriptor
map {
"distribution": "normal",
"mean": 0.25,
"std": 0.1,
"min": 0
}
A descriptor for a truncated normal distribution with a mean of 0.25.
Descriptors can play a more general role in process metadata generation. For simple components, a descriptor can define the key aspects of that component and how it is to be produced, which one function can interpret and another can emit as metadata. As with the naming schemes, this simplifies both metadata linkage and implementation and experimental tweaking. One can, of course, go one step further, and gives names to particularly fine descriptors.
Figure 8: Example: A Knot: Descriptor, Description, and Rendering
map {
"kind": "modulated-knot",
"p": 3,
"x-factors": (
map {"q": 7, "r": 0.52, "skew": true()},
map {"q": 4, "r": 0.11, "skew": false()}
),
"y-factors": (
map {"q": 5, "r": -0.9, "skew": false()},
map {"q": 4, "r": 0.7, "skew": false()}
),
"stretch": 1.25,
"openness": 1
}
x=1.25*cos(3θ) * (0.7*sin(7θ) + 0.11*cos(4θ))
y=cos(3θ) * (-0.9*cos(5θ) + 0.7*cos(4θ))
z=0.2*sin(7θ)

Image description
Perspective rendering of modulated torus knot as a series of blocks.
Descriptors may carry a rich information set. The metadata description of descriptors is therefore frequently not just a simple name/value pair. Recall, for example, the structured information about randomizers we saw in the annotated metadata example:
<algorithm name="j7.density" distribution="normal"
min="0.1" max="0.9"
mean="0.6" std="0.1"/>
Lesson: Automate
The problem with having to manually add code to emit metadata is that it is too easy to be lazy or forget to update the metadata. This is especially likely to happen early in the creation process when there is the most variability and having good process metadata is most important. The work of manually updating code to emit the metadata is even more pressing on the XSLT side, because the XSLT tends to be relatively static, and updating it every time to dump the right stylesheet parameters gets annoying.
Anything that can be done to reduce the distance between implementation and instrumentation increases the reliability of the metadata produced. To the extent that things can be automated, they should be automated. An intermediate step is to use programming conventions and templates to reduce the amount of effort required to instrument a particular work.
I use a combination of automation and programming convention. Every project uses a common execution driver function and uses a map of parameters to hold important tuning values and a map of randomizer descriptors to hold the important randomization algorithms. A standard parameter initialization function handles the overriding of values with external parameters. The driver gets a callback to a content generation function and to a metadata generation function as well as the parameter and randomizer bundles. It is the driver's job to assemble the content and the metadata. Some metadata is still manual (whatever is in the metadata callback), but mostly the driver just dumps out the parameter and randomizer bundles plus standard timestamp values.
Figure 9: XQuery Driver Automatically Embeds Metadata
declare function this:generate(
$n-tries as xs:integer,
$tag as xs:string,
$metadata as function(*),
$content as function(*),
$canvas as map(*),
$randomizers as map(*),
$parameters as map(*)
)
{
for $i in 1 to $n-tries return (
document {
<art:canvas width='{$canvas("width")}'
height='{$canvas("height")}'
>{
<art:metadata>
<art:description>
{$tag}: {$parameters("description")}
</art:description>
{this:created-at()}
{this:dump-parameters($parameters)}
{this:dump-randomizers($randomizers)}
{$metadata($i, $canvas, $parameters)}
</art:metadata>,
$content($i, $canvas, $parameters)
}</art:canvas>
}
)
};
Things are a little more primitive on the XSLT side. Each stylesheet parameter is declared separately and the metadata templates just enumerate them all. There is a named template that can be overridden in a project-specific stylesheet to dump out project-specific stylesheet parameters.
Figure 10: XSLT Stylesheet Automatically Embeds Metadata
<xsl:template match="art:metadata">
<svg:metadata>
<art:metadata style="display:none">
<art:processed>
<xsl:value-of select="current-dateTime()"/>
</art:processed>
<art:description>
<xsl:value-of select="$meta-description"/>
</art:description>
<xsl:copy-of select="node()"/>
<art:stylesheet-parameters>
<xsl:call-template name="dump-project-parameters"/>
<xsl:call-template name="dump-parameters"/>
</art:stylesheet-parameters>
</art:metadata>
</svg:metadata>
</xsl:template>
Lesson: Merge Information from Components
More complex artworks rely on the integration of multiple components, each with their own set of parameters. I expanded programming conventions a little bit to cover these components: each of them has its own metadata function, parameter bundles, randomizers, and colophons. The framework combines component parameter and randomizer bundles with the local bundles to provide a complete sets of values. Similarly, the framework merges information from metadata callbacks for the appropriate set of components to get the full set of relevant metadata, and merges information from colophon callback to produce a full colophon.
To avoid name collisions I use poor man's namespaces[2]: every name is prefixed with a unique tag associated with a particular component.
For example, in Figure 11, the prefix astro names a component that produces astronomical objects, and the prefix mountain names a component that produces mountain ranges. The component map ($COMPONENTS) defines which components are in play, so that their information is merged automatically.
Components may have subcomponents, which are merged in the same way within their parent
component.
Originally I had the main project explicitly perform the appropriate merges, but as more components came into play, automation has become more important, another reminder of that lesson.
Figure 11: Automatically Combining Component Metadata
(: Framework functions to merge component parameters :)
declare function this:component-algorithm-parameters(
$components as map(*),
$resolution as xs:string,
$canvas as map(*)
) as map(*)
{
fold-left(
$components=>map:keys(), map {},
function($map, $key) {
let $component := $components($key)
let $fn :=
function-lookup(QName($component("namespace"), "algorithm-parameters"), 2)
return (
if (empty($fn)) then $map
else (
map:merge((
$map,
$fn($resolution, $canvas)
), map { "duplicates" : "use-last" })
)
)
}
)
};
declare function this:component-metadata(
$components as map(*),
$canvas as map(*),
$randomizers as map(*),
$parameters as map(*)
)
{
for $key in $components=>map:keys()
let $component := $components($key)
let $fn :=
function-lookup(QName($component("namespace"), "metadata"), 3)
return (
if (empty($fn)) then ()
else $fn($canvas, $randomizers, $parameters)
)
};
(:
: Main project
:)
(:
: Component declaration: passed into framework
:)
declare variable $COMPONENTS as map(*) :=
map {
"astro": map {
"namespace": "http://mathling.com/art/astronomy"
},
"mountain": map {
"namespace": "http://mathling.com/art/mountain"
}
};
(:
: Local properties: component properties
: already included automatically
:)
declare function this:algorithm-parameters(
$resolution as xs:string
) as map(*)
{
map {
(: Overrides :)
"astro.star.density": 20
"mountain.crowding": 5,
"mountain.spikiness": 10,
"mountain.smoothing": 0.5,
(: Local parameters :)
"j25.slant": true()
}
};
(:
: Local metadata function:
: Since all component metadata has already been included,
: as well as all local parameters and randomizers, only
: exceptions need to be handled here.
:)
declare function this:metadata(
$canvas as map(*),
$parameters as map(*)
)
{
()
};
Functions combine parameter maps and metadata from multiple components with those from the main project.
Lesson: Be Selective
The mechanism for embedding stylesheet parameters I described before is relatively
simple: just dump out all the stylesheet parameters. The problem with this is that
as time has gone by I have developed more and more components with more and more parameters.
It is hard to pick out important values from one big long undifferentiated list of
parameters, most of which are irrelevant to a particular work. This list just gets
longer and longer. I'd also like to partition the implementation, so that the parameter
dumping doesn't have to have knowledge of all the components. My solution to this
problem is introspection: I use a metadata
stylesheet mode to calculate which stylesheet components are actually in play, and
only dump out the parameters specific to that component if it is in evidence. Shared
parameters always get dumped out.
Figure 12 shows a snippet from a stylesheet component. There are a number of different parameters
that control how the elements art:ghost and art:circle-ghost will be rendered. In the metadata mode, the first of these seen in the document will
trigger the dumping of this component's stylesheet parameters into the metadata output.
Figure 12: A Stylesheet Component
<xsl:param name="ghost.x">1</xsl:param>
<xsl:param name="ghost.y">1</xsl:param>
<xsl:param name="ghost.n">100</xsl:param>
<xsl:param name="ghost.opacity">0.01</xsl:param>
<xsl:param name="ghost.fade">1</xsl:param>
<xsl:param name="ghost.shrink">1</xsl:param>
<xsl:param name="ghost.scale">1.01</xsl:param>
<xsl:param name="ghost.rotate">30</xsl:param>
<xsl:template match="(//(art:ghost|art:circle-ghost))[1]" mode="metadata">
<art:component name="ghost">
<art:parameter name="ghost.x">
<xsl:value-of select="$ghost.x"/>
</art:parameter>
<art:parameter name="ghost.y">
<xsl:value-of select="$ghost.y"/>
</art:parameter>
<art:parameter name="ghost.n">
<xsl:value-of select="$ghost.n"/>
</art:parameter>
<art:parameter name="ghost.opacity">
<xsl:value-of select="$ghost.opacity"/>
</art:parameter>
<art:parameter name="ghost.fade">
<xsl:value-of select="$ghost.fade"/>
</art:parameter>
<art:parameter name="ghost.scale">
<xsl:value-of select="$ghost.scale"/>
</art:parameter>
<art:parameter name="ghost.rotate">
<xsl:value-of select="$ghost.rotate"/>
</art:parameter>
<xsl:apply-templates select="*" mode="metadata"/>
</art:component>
</xsl:template>
Lesson: Add Hooks for Dynamic Values
Fixed parameter values are great, but they are not enough. An important aspect of these generative art pieces is randomness. We saw how we can use descriptors to capture the random distribution used. A more vexing problem remains: what about the actual value that was picked? That is not going to be a fixed value in the parameter bundle. How can we handle variable process metadata?
The basic solution to this problem is to provide a new element in the XML vocabulary
that represents dynamic values of this kind. Stylesheet templates gather up all the
art:dynamic-parameter elements and copy them into the metadata element. The metadata
mode gathers up all the metadata. The metadata element is constructed by running
through the document in that mode.
Figure 13: Dynamic Parameters
<xsl:template match="art:canvas" mode="metadata">
<svg:metadata>
<art:metadata style="display:none">
<art:processed>
<xsl:value-of select="current-dateTime()"/>
</art:processed>
<art:description>
<xsl:value-of select="$meta-description"/>
</art:description>
<xsl:apply-templates select="art:metadata"
mode="metadata"/>
<art:stylesheet-parameters>
<xsl:apply-templates select="* except art:metadata"
mode="metadata"/>
<xsl:call-template name="dump-project-parameters"/>
<xsl:call-template name="dump-parameters"/>
</art:stylesheet-parameters>
</art:metadata>
</svg:metadata>
</xsl:template>
<xsl:template match="art:dynamic-parameter"/>
<xsl:template match="art:dynamic-parameter" mode="metadata">
<xsl:copy-of select="."/>
</xsl:template>
<xsl:template match="art:component"/>
<xsl:template match="art:component" mode="metadata">
<xsl:copy-of select="."/>
</xsl:template>
When it comes to components and subroutines, we need a little more here so that we
can return the values we care about as well as the captured variable process metadata.
My solution here is to use wrappers: maps that have a content entry that holds the main data and a dynamics entry that holds the variable metadata. Making this consistent across APIs so that
it is more automated is still a work in progress. Designing for this in the first
place would have been easier in the long run.
Figure 14: Example: Wrapper
(:
: Create a wrapper for an astronomical object
:)
declare function this:object(
$content as item()*,
$dynamics as element()*
) as map(*)
{
map {
"kind": "astronomical",
"content": $content,
"dynamics": $dynamics
}
};
...
(: A particular astronomical object, wrapped :)
let $dynamics := (
<art:dynamic-parameter name="moon.base.gradient">{
$background
}</art:dynamic-parameter>,
<art:dynamic-parameter name="moon.texture.gradient">{
$moon-gradients[$gradient-ix]
}</art:dynamic-parameter>,
<art:dynamic-parameter name="moon.texture.scale">{
$texture-scale
}</art:dynamic-parameter>
)
return (
this:object(
($moon, $rings),
$dynamics
)
)
Lesson: Use Annotations and Introspection to Document Complex Functions
Random distributions are constrained enough that simple descriptors can be passed to a single driver function and interpreted. There are other more complex functions where that approach doesn't work so well. For example, consider noise functions. These consist of base functions combined with each other and various modifiers to create programmatic textures. They are implemented as functions that return anonymous functions to perform the combinations. Defining them in this way allows them be bound to parameters, and referenced by name, allowing for more variation and tweaking.
Figure 15: Example: Complex Noise Function
map {
"planet.topography":
noise:min(
fbm:noise2(
fbm:context()=>
fbm:octaves(14)=>
fbm:frequency(1.0)=>
fbm:lacunarity(2.208)
)=>noise:scale-bias(0.375,0.62)
,
fbm:noise2(
fbm:context()=>
fbm:octaves(7)=>
fbm:frequency(0.5)
)=>noise:curve($shoreline)
)=>noise:clamp(-1.0, 1.0)
...
}
The planet.topography parameter is bound to a function that takes a point in x-y space and produces a double
value. The component functions, such as noise:scale-bias are functions that return functions of that same type. Here they are combined to
produce the overall function that produces the texture we want.
In Figure 15, noise:min, noise:scale-bias, noise:curve, noise:clamp, and fbm:noise2 all return functions. The overall function is a chain of calls to produce the final
value for a given input point. There are dozens of modifier functions like this and
they can be nested and combined to an arbitrary degree. It is certainly possible to
imagine them producing descriptors instead that then are interpreted to call the appropriate
function, but this amounts to double the work every time a new modifier function is
created. There is another downside: noise functions tend to be called a great deal
in inner loops, potentially once for each point in a canvas. For a high resolution
image that is millions of times. One of the advantages of using function values is
that complicated algorithms can pre-compute some values and tables based on the specific
parameters as part of the closure rather than as part of the body of the function,
speeding them up.
There is another approach to reporting these functions in metadata: using function
annotations. This approach depends on the availability of certain extension functions
to evaluate ad hoc XQuery strings and to access the function annotations so they can
be reported on. I have only worked out how to do this in Saxon and MarkLogic. For Saxon, Saxon-PE or Saxon-EE is required; for MarkLogic, the http://marklogic.com/xdmp/privileges/xdmp-eval execute privilege is required.
The first step is to annotate the functions being returned by the function library. Each (anonymous) function gets annotated with its name, which can then be accessed via the appropriate extension function.
Here is the Saxon version of a function to access a function name, either for a named function or an annotated anonymous function.
Figure 16: Saxon function-name Function
declare function this:function-name($f as function(*)) as xs:string
{
if (empty(fn:function-name($f))) then (
let $fn :=
saxon:function-annotations($f)[
map:get(.,"name")=xs:QName("art:name")
]!map:get(.,"params")
return (
if (empty($fn)) then "[anon]" else string($fn)
)
) else (
string(function-name($f))
)
};
The MarkLogic version is similar.
Figure 17: MarkLogic function-name Function
declare function this:function-name($f as function(*)) as xs:string
{
if (empty(function-name($f))) then (
if (empty(xdmp:annotation($f, xs:QName("art:name"))))
then "[anon]"
else xdmp:annotation($f, xs:QName("art:name"))
) else (
string(function-name($f))
)
};
However, we want to get a view into the nesting of calls of these anonymous functions, and to do this we need to do more. The idea is to call an annotator that constructs the more elaborate annotation we want. We end up with a library of functions that return functions, all wrapped inside a call to an annotator function to construct the dynamic annotations. Figure 18 shows one of the noise modifier functions: it computes the minimum of the output of two other noise functions. We annotate it with a base function name, and then call the annotator to add more information.
Figure 18: Example: Annotating a Function
declare function this:min(
$f1 as function(map(*)) as xs:double,
$f2 as function(map(*)) as xs:double
) as function(map(*)) as xs:double
{
this:annotate(
%art:name("mod:min")
function ($point as map(*) as xs:double {
fn:min(($f1($point), $f2($point)))
},
($f1, $f2)
)
};
Since function annotations cannot be dynamic, here is where we rely on an extension
function to evaluate the dynamic string in the proper context. The trick is to wrap
the function we care about in another anonymous function with the appropriate annotation.
This is done inside an evaluation string. The tricky part is that the function variable
is not part of the closure for the evaluated function (in Saxon, at least) so we have
to add it as an argument and use partial evaluation. Figure 19 shows the Saxon 11 version, where we pass the function in the map of external variables
to the saxon:xquery extension function.
Figure 19: Saxon 11 Annotation Function
declare function this:annotate(
$f as function(map(*)) as xs:double,
$parms as function(*)*
) as function(map(*)) as xs:double
{
if (empty($parms)) then $f
else (
let $name :=
this:function-name($f)||
"("||string-join($parms!(this:function-name(.)),",")||")"
return (
saxon:xquery("
declare namespace art='http://mathling.com/art';
declare variable $f as function(map(*)) as xs:double external;
%art:name('"||$name||"') function (
$point as map(*),
$f as function(map(*)) as xs:double
) as xs:double
{
$f($point)
}"
)((), map {xs:QName("f"): $f})(?, $f)
)
)
};
The Saxon 10[3] version is slightly different, using the pair of extension functions saxon:compile-query and saxon:query. Since saxon:query only takes nodes as external parameters and a function isn't a node, we have to pass
it via the context item instead. Figure 20 shows what that looks like.
Figure 20: Saxon 10 Annotation Function
declare function this:annotate(
$f as function(map(*)) as xs:double,
$parms as function(*)*
) as function(map(*)) as xs:double
{
if (empty($parms)) then $f
else (
let $name :=
this:function-name($f)||
"("||string-join($parms!(this:function-name(.)),",")||")"
return (
saxon:query(
saxon:compile-query("
declare namespace art='http://mathling.com/art';
declare variable $f as function(map(*)) as xs:double := .('f');
%art:name('"||$name||"') function (
$point as map(*),
$f as function(map(*)) as xs:double
) as xs:double
{
$f($point)
}"
),
map {"f": $f}, ()
)(?, $f)
)
)
};
In MarkLogic things are a little more straightforward, because parameters are passed
as a map[4] to the xdmp:eval function and the function variable is part of the closure, so no partial evaluation is required.
Figure 21: MarkLogic Annotation Function
declare function this:annotate(
$f as function(map:map) as xs:double,
$parms as function(*)*
) as function(map:map) as xs:double
{
if (empty($parms)) then $f
else (
let $name :=
this:function-name($f)||
"("||string-join($parms!this:function-name(.),",")||")"
return (
xdmp:eval("
declare namespace art='http://mathling.com/art';
declare variable $f external;
%art:name('"||$name||"') function ($point as map:map) as xs:double {
$f($point)
}",
map:entry("{}f", $f)
)
)
)
};
Putting it all together, we can now emit the annotation from the noise function in
Figure 15 as part of our metadata through a call to function-name, and get something like this:
noise:clamp(noise:min(noise:scale-bias(fbm:noise2),noise:curve(fbm:noise2)))
Here I have just shown the dynamic annotation including the chain of functions, but clearly the scheme could be extended to include information about constant parameters as well.[5]
A low-tech alternative when these extension functions are not available is, of course, to manually emit the appropriate metadata. The risk is that since the metadata is separated from the actual function value, it may be wrong. It is too easy to allow metadata and data to drift apart when a manual act is required to keep them in sync: automated metadata is more reliable as long as it can be made accurate.
Lesson: Pay Attention to the Whole Publication Chain
The publication part of the standard workflow creates a new wrinkle: the problem of maintaining the rich metadata across conversion to a new format. Public sites where images may be shared generally do not permit the posting of SVG images (alas!). Converting the image itself is not usually a problem. There are plenty of conversion tools. I generally use InkScape to convert to JPEG or PNG files. The key problem is how to preserve the rich metadata.
Fortunately both JPEG and PNG have slots for metadata of various kinds. Unfortunately, the image tool support for metadata is weak. InkScape does a great job of conversion, but just drops all metadata on the floor. ImageMagick is less reliable for conversion of SVG, but it does at least have hooks for copying metadata. My solution is a bit of a Rube Goldberg device:
-
Use XQuery to extract the metadata from the SVG to a temporary file
-
Use InkScape to convert the SVG to some binary image format
-
Use ImageMagick to slam the metadata back into the binary image
Figure 22: Pushing Metadata into Converted Image
bin/saxon bin/getmeta.xqy +FILE=$fn > ${fn/.svg/.meta}
inkscape --batch-process --export-type=png --export-filename=- $fn | \
convert -comment @${fn/.svg/.meta} - ${fn/.svg/.png}
When publishing the converted work I have to manually (alas!) copy some of the signature metadata out of the extracted metadata file to accompany the work, since it is not readily visible in the same way it is in SVG. A similar manual process is required to produce alternative text descriptions for the images.
Figure 23: Various Workflows
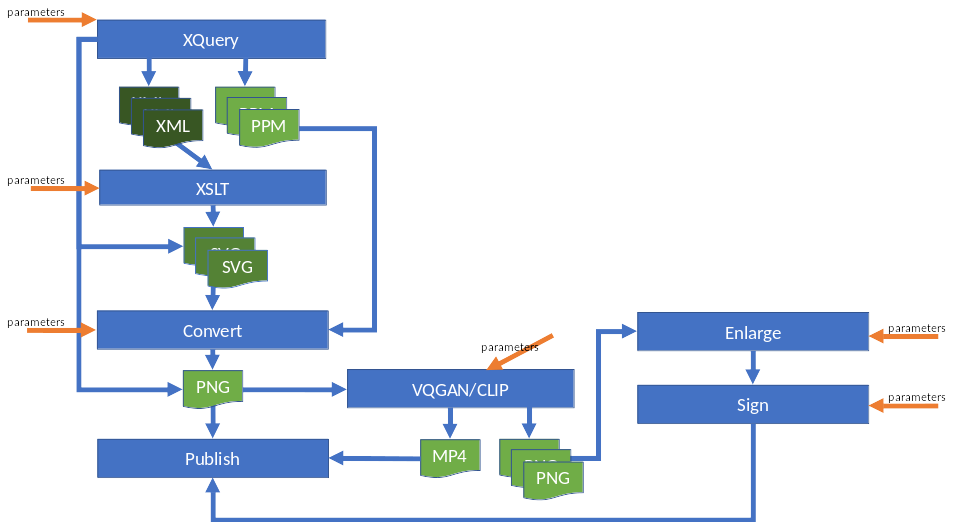
Image description
The diagram shows seven boxes with flows between them. The main flow is from the box
labelled XQuery
(producing XML files) to XSLT
(producing SVG files) then to Convert
(producing PNG files) and finally to Publish
. There are alternative outputs and flows. XQuery
may produce raw image files (PPM) or SVG files which then flow directly into Convert
, or it may produce PNG files which flow directly into Publish
. A side flow takes PNG files and flows into VQGAN/CLIP
which either produces an MP4 file, flowing directly into Publish
, or PNG files, which flow through Enlarge
and Sign
before reaching Publish
. Parameters are shown as being provided at each step in all the flows.
While most of my art runs through SVG, there are additional workflows that don't follow that path. Some workflows produce raw images (PPM format) directly or PNG (PNG) files directly. Other workflows involve taking a generated image and running it through some machine learning models with additional parameters. Let's look at some of the metadata capture issues of these two workflows.
When PPM files are generated directly, metadata can be embedded in comment fields directly. The API is a little different from the API for the standard workflow, but conceptually there is not much difference. Conversion also works slightly differently, because InkScape cannot convert PPM images. I use ImageMagick here instead. However, PPM images are bitmaps: arrays of pixel values. I still want to sign them, visually. The solution here is to take a conversion of the SVG signature path, scaled and coloured appropriately, and compose it with the converted image as the final step, again using ImageMagick.
When PNG files are generated directly, I use the Saxon Java reflexive mechanism to call the Java PNG APIs. These have hooks for embedding metadata, but they aren't actually implemented: metadata just vanishes, so more machinations are required.
What about the machine learning workflow? The actual steps are quite complex, and additional metadata is actually being produced at each step:
-
Run main workflow through conversion to a binary image format
-
Provide image with additional parameters to machine learning model to produce new binary images. For performance reasons, these images are smaller scale.
-
Run selected output images through a different machine learning model that expands them to full resolution
-
Capture combined metadata
-
Compose image with signature
Let's focus on step four. We have metadata from the original SVG, metadata in the images produced from step two (which includes information about the machine learning process, but not from the original image), and metadata from the expansion phase (which includes information about parameters for that process). For that matter, we also have metadata about the images at each step of the process which the various tools also add (e.g. height and width). Capturing and combining all of this is another Rube Goldberg device, using exiftool to extract information from the various intermediate images, a little massaging with XQuery and shell scripts, and ImageMagick to slam it all into the final output.
While all this image conversion and hackery may seem like a niche concern, similar issues occur with other kinds of digital artifacts. For example, what metadata gets carried across when you convert a word processing document to a published PDF? What controls do you have over that process? What metadata can you add to convey information about that specific step in the process? Any process step that crosses tool or format boundaries is a place of danger for metadata preservation.
Lesson: Everything Starts as a Special Case
Processes are as varied as the human imagination. Just when you think you have everything captured in the framework, along comes another special case. It can take some time to figure out how to organize some new set of cases into an expanded framework for capturing them. That's OK. Sometimes the best you can do is cobble something together that works for today's problem. Things evolve over time. It is important to keep a manual escape hatch and be prepared to refactor later.
We've seen cases of this already. Originally every bit of metadata was captured manually. Then some of the fixed process metadata was captured automatically. Then the component metadata was captured automatically. What started as ad hoc functions with a set of parameters became a system of descriptors, captured automatically. What started with a set of named gradients and filters became a naming system allowing for more flexible combinations.
Lesson: Standardization Gets in the Way, Mostly
I should probably offer a word or two about a common thrust of a lot of discussion of metadata: standardization. All the properties mentioned here are ad hoc and idiosyncratic with their own naming scheme. Is there no place for reference to standards here?
The short answer: not really. As Laplace probably didn't say: I had no need of that hypothesis. The bulk of the information being captured here is for an audience of one: to the extent there is standardization, it is a standardization of a peculiar kind. Yes, "standardization" of naming conventions is helpful, but it doesn't have to reference any external set of properties and it isn't fixed. Refactoring and reimagining of the conventions happens all the time. Further, process metadata is wildly variable: trying to shoehorn it into someone's idea about how to represent such information (to the extent such a thing exists at all) would be an exercise in frustration. Using external standards increases the distance between implementation and instrumentation and, as I said before, that reduces the reliability of the metadata produced. It would be a net loss. It would, in fact, reduce the reusability of the information for the creator.
It is ever thus. Sticking to standards slows the creative process. Not sticking to standards reduces the global usability of the information. Sticking to standards increases the reusability of the information provided. Not sticking to standards decreases the amount of information provided.
Is there a place for using external standards for certain information? Perhaps at least the information that is targeted to external audiences, such as the signature metadata? Yes. It would be useful to capture at least signature metadata and possibly some organizational metadata in some more (globally) standard way. On the other hand, the specifics of the publication process drive which standards would be most useful. This is metadata from the third-party perspective, added after the process of creation to interface with the world, to stand between the creator and the consumer. As with everything in the publication phase of the process, there are external constraints and translations necessary. It isn't clear that picking which standard to use up front actually helps.
Summary: Key Lessons
Metadata has a role in the act of creation itself, not just as a later addition. While the particular use case discussed in this paper may seem far away from conventional concerns, I hope the lessons learned in embedding metadata are not.
As we have seen several times, making it easier to capture metadata about the process also makes it easier to implement the process. Automation begets automation. Using a naming system enables both the simple deployment of complex behaviours and the simple reporting of the behaviour that was deployed. Similarly, use of named parameters and descriptors makes for easier tweaking of the behaviour that they control. Componentization and a framework for combining the results of the component metadata lends itself to simpler development of complex processes through the use of configuration rather than coding. None of these observations is specific to the generation of art. They apply with equal force to generation of any digital artifact through some non-trivial process. A metadata-first approach to developing these processes simplifies both the capturing of the metadata and the development and tuning of the processes themselves.
Likewise, the lesson that most tools are, at best, suspect when it comes to preserving metadata applies to other kinds of digital artifacts also. If the last chain in your process is to render your XML to PDF, for example, don't expect metadata to come along for the ride without some effort.
|
Embed metadata as part of the creation process |
Creating embedded metadata as part of the creation process makes metadata more convenient to create and use, compared to adding metadata as a separate act or in a separate place. |
|
Names for everything |
A key part of making the process self-describing is having human labels for various aspects of the process. Metadata fields can then be mapped back and forth directly between the captured metadata fields and the code driving the process. Names can evolve into naming systems that simplify the linkage between behaviour and metadata even further. |
|
Use descriptors for coherent pieces of behaviour |
Descriptors can bundle together a set of related parameters into one unit which can then be used both to drive the process itself and provide a convenient structured description. Descriptors may eventually evolve into names. |
|
Automate |
Reliability of metadata is enhanced if it is captured as part of the process of creation automatically. This is especially true for process metadata: making the process itself self-describing creates a positive feedback loop for adjusting the process and comparing the results of different experiments. |
|
Merge information from components |
Software is often written in a divide-and-conquer fashion: the framework for capturing process metadata needs to be written allow for the same separation. |
|
Be selective |
The richer the metadata being captured, the more it threatens to become overwhelming. Partitioning metadata into logical groupings and pruning irrelevant metadata becomes important. Any sufficiently large difference in scale becomes a difference in kind. New strategies are required. |
|
Add hooks for dynamic values |
If you need to capture variable process data, be prepared for it to be captured at various levels in the stack. It may be tricky to design APIs with this in mind and it is easy to end up being inconsistent. |
|
Use annotations and introspection to document complex functions |
Making a process self-describing is easier when introspection can be used to interrogate key aspects of the process so they can be reported on. |
|
Pay attention to the whole publication chain |
A full publication process entails interfacing with a variety of tools and sites, each with their own restrictions and limitations. It is not enough to capture metadata within your own process: you need to work to preserve it across these boundaries too. |
|
Everything starts as a special case |
Process metadata is as varied and complex as the processes themselves. There are always special wrinkles that need special handling. Sometimes just having a manual escape hatch is the best you can do. Sometimes you need to cobble together something that works well enough for a particular case, in the full expectation that it will fail in some other case. |
|
Standardization gets in the way, mostly |
Process metadata is as intrinsically idiosyncratic as the processes themselves. To the extent that standard properties or vocabularies exist for these things at all, they mostly create impedance mismatches and therefore act as barriers to effective capture. They are counterproductive. Standardization finds a use after the creative process is done, when we reenter the realm of the third-party perspective. |
Appendix A. Tools
| Tool | Use | Notes |
|---|---|---|
| ImageMagick | Conversion from SVG | Slow, fails on images with a lot of components, doesn't handle some features correctly |
| Conversion to/from PPM | InkScape cannot do this | |
| Composition of images, especially signature | Requires detailed specification of placement and sizing | |
| Extraction of image metadata | Use -verbose flag | |
| Insertion of image metadata | Limited to comment field; simple interface | |
| InkScape | Conversion from SVG | Best conversion, but loses metadata |
| Extraction of SVG features/objects | Can use actual height/width to resize canvas | |
| Drawing | What it is really for, not what I use it for much | |
| exiftool | Extraction of image metadata | Can extract as XML |
| Insertion of image metadata | More complex interface, more capabilities | |
| Saxon | XQuery: Implementation of main algorithm | XQuery 3.1 compliant, good performance |
| XQuery Java extensions | Useful extensions; complex implementation; requires PE or EE | |
| XSLT: Render art XML to SVG | Good performance; requires PE or EE to import supporting XQuery libraries (EE to do it the standard way) | |
| MarkLogic | XQuery: Implementation of main algorithm | Very rich set of useful built-in functions; control of multithreaded processing, non-standard maps |
| XSLT: Render art XML to SVG | Importing XQuery modules much easier, but non-standard | |
| Searchable database | Rich fast search | |
| Java PNG API | Read/write PNG files directly | Avoids conversion to/from PPM but metadata APIs just don't work |
References
[Getty] Murtha Baca, editor. Introduction to Metadata, Version 3. Getty Information Institute, 2008. http://www.getty.edu/research/conducting_research/standards/intrometadata/index.html
[OAIS] CCSDS (The Consultative Committee for Space Data Systems). Reference Model for an Open Archival Information System (OAIS). Recommended Practice. CCSDS 650.0-M-2. June, 2012. https://public.ccsds.org/pubs/650x0m2.pdf
[SVG] W3C: Erik Dahlström, Patrick Dengler, Anthony Grasso, Chris Lilley, Cameron McCormack, Doug Schepers, Jonathan Watt, Jon Ferraiolo, 藤沢 淳 (FUJISAWA Jun), Dean Jackson, editors. Scalable Vector Graphics (SVG) 1.1 (Second Edition) Recommendation. W3C, 16 August 2011. http://www.w3.org/TR/SVG11/
[DublinCore] Dublin Core Metadata Initiative. https://www.dublincore.org/
[PNG] W3C: David Duce, editor. Portable Network Graphics (PNG) Specification (Second Edition); Information technology — Computer graphics and image processing — Portable Network Graphics (PNG): Functional specification. ISO/IEC 15948:2003 (E) Recommendation. W3C, 10 November 2003. http://www.w3.org/TR/PNG
[exiftool] Phil Harvey, ExifTool. https://exiftool.org/
[ImageMagick] ImageMagick Studio LLC, Image Magick. https://imagemagick.org/index.php
[InkScape] The Inkscape Project, InkScape. http://inkscape.org/
[XSLT] W3C: Michael Kay, editor. XSL Transformations (XSLT) Version 2.0 Recommendation. W3C, 23 January 2007. http://www.w3.org/TR/xslt20/
[Lubell]
Joshua Lubell. Metadata for Long Term Preservation of Product Data.
Presented at International Symposium on XML for the Long Haul: Issues in the Long-term
Preservation of XML, Montréal, Canada, August 2, 2010. In Proceedings of the International Symposium on XML for the Long Haul: Issues in the
Long-term Preservation of XML. Balisage Series on Markup Technologies, vol. 6 (2010). doi:https://doi.org/10.4242/BalisageVol6.Lubell01.
[MarkLogic] MarkLogic Server, MarkLogic Corporation. https://www.marklogic.com/product/marklogic-database-overview/
[PPM] Jef Poskanzer, NetPBM. http://netpbm.sourceforge.net/doc/ppm.html
[NISO] Jenn Riley, McGill University. Understanding Metadata: What is Metadata, and What is if For?: A Primer. NISO Press, 2017. ISBN: 978-1-937522-72-8. https://groups.niso.org/apps/group_public/download.php/17446/Understanding%20Metadata.pdf. Updated from 2004.
[XQuery] W3C: Jonathan Robie, Michael Dyck, Josh Spiegel, editors. XQuery 3.1: An XML Query Language Recommendation. W3C, 21 March 2017. http://www.w3.org/TR/xquery-31/
[Saxon] Saxon, Saxonica. https://www.saxonica.com/products/products.xml
[1] Four, sort of. Weirdly, "markup languages" is also listed with other kinds of metadata in the original. I think the idea is that identifying, say, a piece of text as a "paragraph" is providing some kind of metadata information. Perhaps. Nevertheless, this strikes me as a fairly egregious category error, in that a markup language is an implementation mechanism for defining metadata, not a class of metadata in its own right. Declaring that a piece of text is a paragraph is partly descriptive and partly structural.
[2] Actual namespaces and QNames could be used. I have no principled objection, but do I have some ease-of-use issues with QNames as keys, both on the generation side and in the final output in the metadata. Simple strings work better for me at the moment.
[3] Preservation of function annotations on anonymous functions like this depends on a bug fix in Saxon 10.6 (Thanks, folks!) so this trick doesn't work in older versions of Saxon.
[4] The maps here are the MarkLogic extension type map:map, which predates XQuery 3.1 maps and has a slightly different API.
[5] A little caution is warranted here. Depending on how the optimizer sees this code, you may end up calling an ad hoc evaluation for every call of the noise function. Doing that millions of times adds up too.