Flynn, Peter. “Why writers don't use XML: The usability of editing software for structured documents.” Presented at Balisage: The Markup Conference 2009, Montréal, Canada, August 11 - 14, 2009. In Proceedings of Balisage: The Markup Conference 2009. Balisage Series on Markup Technologies, vol. 3 (2009). https://doi.org/10.4242/BalisageVol3.Flynn01.
Balisage: The Markup Conference 2009 August 11 - 14, 2009
Peter manages the academic advisory and electronic
publishing unit at University College Cork, Ireland, and
also runs text management consultancy, Silmaril. He was a
member of the W3C's XML Special Interest Group and a member
of the IETF's Working Group on HTML. He is maintainer of the
XML FAQ and author of The World-Wide Web
Handbook (ITCP, 1995) and
Understanding SGML and XML Tools
(Kluwer, 1998). He is completing a belated PhD in software
usability, and in his copious spare time he surfs, cooks,
and listens to early music.
XML, LaTeX, and other structured-document systems are used
daily by those experienced in computing, and by technical
authors in many fields. Outside these areas, however, there is
a widespread lack of adoption, or resistance to these systems.
This forms a barrier to the creation and use of reliable,
persistent, unencumbered, and reusable documents, which in
turn adds a hidden burden to the use of corporate,
institutional, and personal information.
This paper reports on a study of the usability of editing
software for structured documents. It extends the research
outlined in earlier work [Flynn2006], where it
was found that there was no essential difference in markup
operations between any of the editing software tested, and
that any distinction was possibly more attributable to the
interaction design of the interfaces.
The objective is to see if changes to the interface to
make it user-centered rather than technology-centered could
result in greater acceptability to authors and editors both
inside and outside the IT and markup fields, and thereby lead
to an improved adoption rate of structure-guided writing and
editing software.
The earlier analyses of software and features sought by
users were extended to cover more recent data, and a survey of
existing users was conducted to determine how the interfaces
were being used. The results are being applied to construct a
model of the interface which can be tested for usability
compared with existing systems.
This paper describes research being submitted as
part of a PhD in the Department of Applied Psychology, UCC
(Human Factors Research Group).
Background
Writers and editors have until recently used a wide range of
editing software. In the Humanities, document-based
collaboration is relatively uncommon [Lariviere2006],
so authors were less constrained by compatibility issues;
whereas within the IT and scientific communities, the range has
been smaller, partly because of the need to use specialist
notations, and partly because of the need to remain compatible
with co-authors [Anghelache2004]. In the wider world
of writing outside research and academic institutions the
difference was wider, because writers do not typically form
homogeneous categories. Not all such software was necessarily
ideal for the purpose, and much of it has fallen by the wayside
in the path of technological advance; particularly in the face
of the predominance of a single operating system and a single
wordprocessor.
The onus of interpretation, customization, and rendering of
publishable material has customarily been the responsibility of
the publisher or other intermediary, who expends large sums on
specialist labor for this purpose. However, in some fields,
publishers have been asking authors for camera-ready copy for
over 20 years to minimize costs, and the effort involved and the quality
of these submitted documents has been a cause for complaint on
both sides [Luey2007]. Businesses, database publishers,
libraries, search-engine optimizers, and printers have similar
concerns: the quality of the documents (in source or
camera-ready form) is often insufficient for meaningful capture,
re-use, or formatting [Williams1995]. The causes are
many, and have been well-established for many years, but among
them is a lack of suitable software and lack of author education
[Denning1986, Heck1993].
As we showed in [Flynn2006], there is no lack
of software as such, only a lack of
suitable software — for some value of
suitable described by the respondents. In that
report, we discussed three principal findings:
In a study of editing software, we found that all XML
editors are basically the same XML editor: the facilities
provided are virtually identical, and the differences are in
the interface to these facilities, such as the depth of menu
traversal and the naming of actions, rather than in the
facilities themselves. The same is nearly as true of editors
for LaTeX, but as the markup can be changed arbitrarily by
the author, the manipulations required of the editing
software are not mandated or implied by the system as they
are with XML. Some specific deficiencies were noted which
inform the adaptations made in section “The interface is the product”.
A survey of expert practitioners in the field of
markup-directed authoring and editing (taken to obtain a
baseline of recognized problems), we found that the
principal criterion for the recommendation of software was
familiarity or acceptability to the user, rather than
applicability to the tasks, largely because of the
difficulties in [re-]training users to an interface seen as
less suitable for non-experts.
An analysis of requests to the principal discussion
forums on XML and LaTeX asking for recommendations,
suggestions, or advice on the selection of editing software
was used to estimate the requirements of users. The four
most frequently-cited criteria were Cost (free or Open
Source software), a WYSIWYG interface, Ease
of Use, and Simplicity — over and above any
structure-related or markup-related facilities.
The investigations into software and user requirements
(items 1 and 3
above) were updated to 2008, measuring more recent applications
and requests, but this showed that the original findings still
hold. An additional inquiry was then undertaken to resolve the
software facilities and the user requirements with actual
current practice (section “How authors and editors use their software”) and to build a
model of a user interface to test the findings (section “The interface is the product”).
How authors and editors use their software
The survey of users was constructed to find out what
software the authors and editors used and how they used it. The
survey was piloted for a week in April 2006 and the revised
version made available online between February and April 2008.
It used the phpESP web survey package, and was publicized via
the online forums to which it was addressed (the comp.text.tex,
comp.text.xml, and comp.text.sgml Usenet newsgroups, and the
XML-L, TeXhax, and LaTeX (Google) mailing lists).
There were 62 valid responses. All respondents were
guaranteed anonymity. An estimate of the population (those who
might have seen the announcements of the survey) is difficult to
make: the membership of the mailing lists was approximately 700;
but the readership of the Usenet newsgroups is not knowable, and
may extend to many thousands. The responses therefore represent
a small interested sample, and there will have been many readers
whose interests in XML were in its use for data representation,
not structured documents.
Several attempts were made to widen the scope and seek the
interest of publishers and writers' organisations in
participating, but all were unsuccessful. The survey does not
therefore represent the interests of the generality of writers
but concentrates on identifying how users of structured editing
software use their interfaces. Further work would be required to
extend the reach of this enquiry into other fields.
The questions asked the respondents to describe their way of
performing a set of actions, which were obtained from the
requirements expressed in the updated analysis of user requests.
The available responses in each case were presented as a
multiple-choice list which was constructed from the updated
survey of editing software to represent the known
affordances (ways of doing things which are more
or less obvious to the user: [Gibson1979]). An
Other category was also provided, but rarely
used.
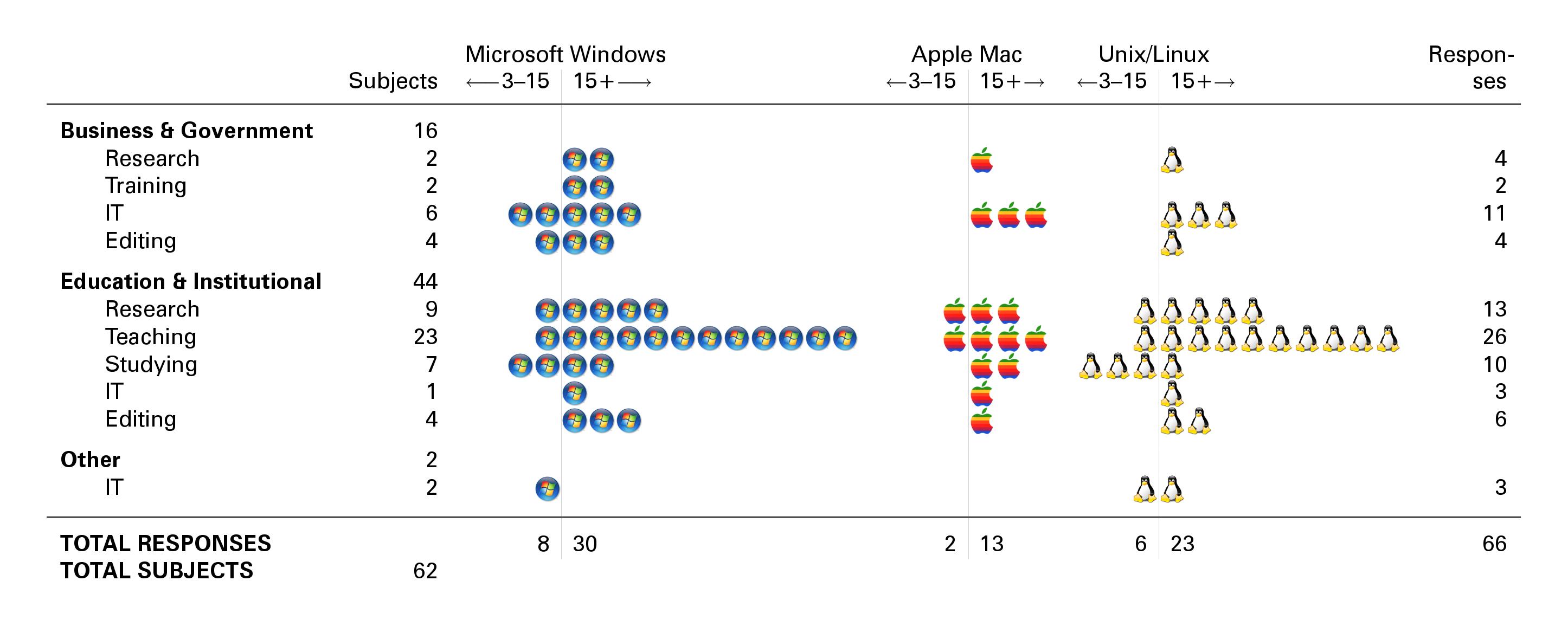
Figure 1: User Survey: background variables
Number of subjects by industry and occupation by years
of experience and multiple responses to operating
system
A preliminary set of background questions was included to
see if the responses varied by experience (years), operating
system, occupation, or document types most commonly used.
Unfortunately there was insufficient variability among the
background data for any such effects to be detected, possibly
due to the nature of an unavoidably self-selected sample (Figure 1).
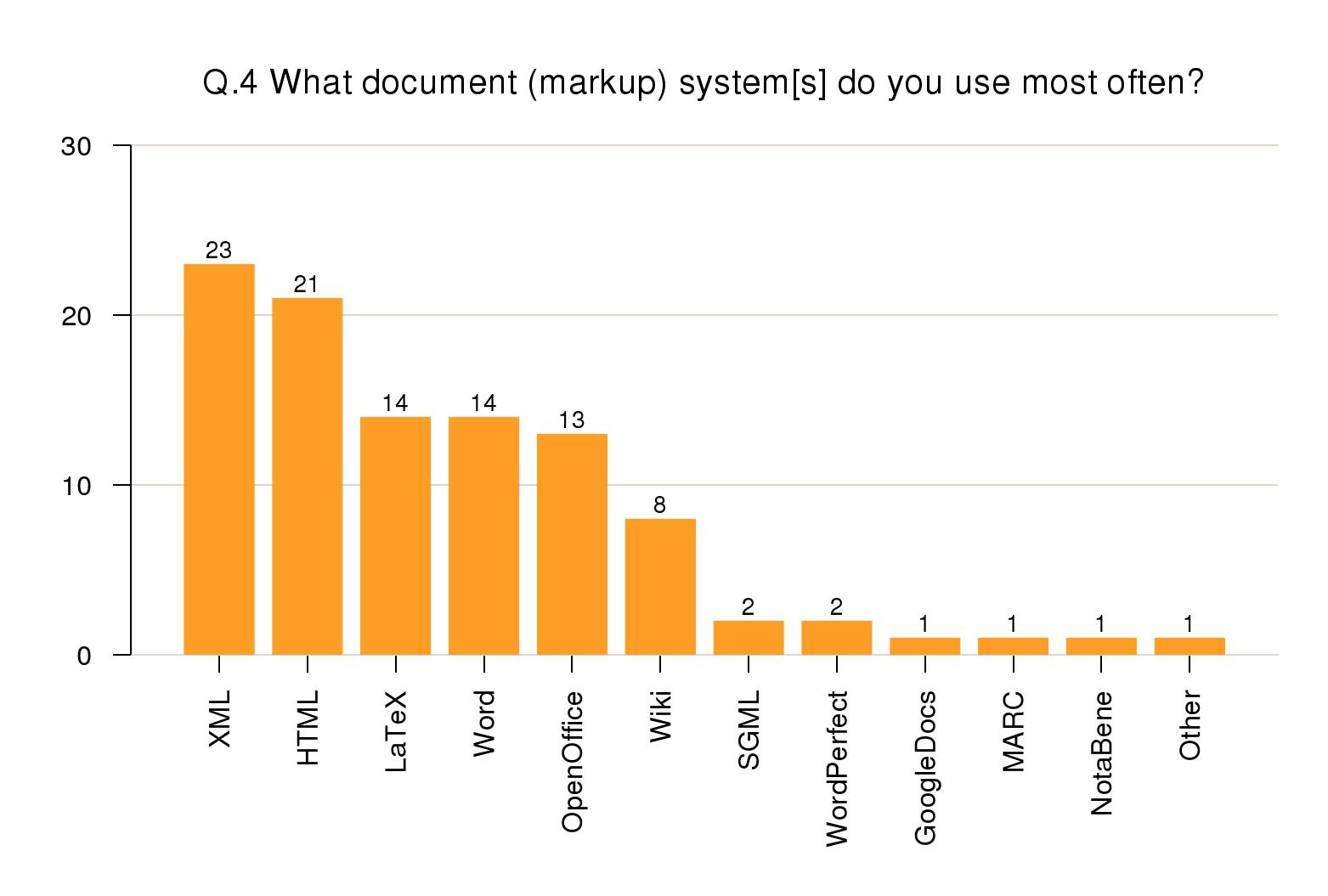
Most respondents worked principally
with text documents (77%); other document classes were in the
single digit percentages. XML and HTML accounted for 44% of
usage of markup systems; LaTeX, Word, and OpenOffice were
roughly equal at 13–14% each. Wiki experience was surprisingly
high at 8% but all others (including SGML) were at 2% or below
(see Figure 2).
Figure 2: User Survey: Markup types used
Percentages of all multiple responses
The editors most respondents had experience of were oXygen (24%)
followed by Word (13%), Emacs (11%), and vi (7%) [both used for
both XML and LaTeX]. Other LaTeX editors accounted for another
12%. The Arbortext editor rated 6% along with OpenOffice, but
there was a long tail of other products.
Results
The questions used a multiple-choice answer format because
respondents were expected to use (or have used) many different
systems. This enabled the survey to reflect a much wider range
of behavior than would otherwise have been the case. In the
following list, percentages are therefore of all responses to
the question, not of the number of individuals.
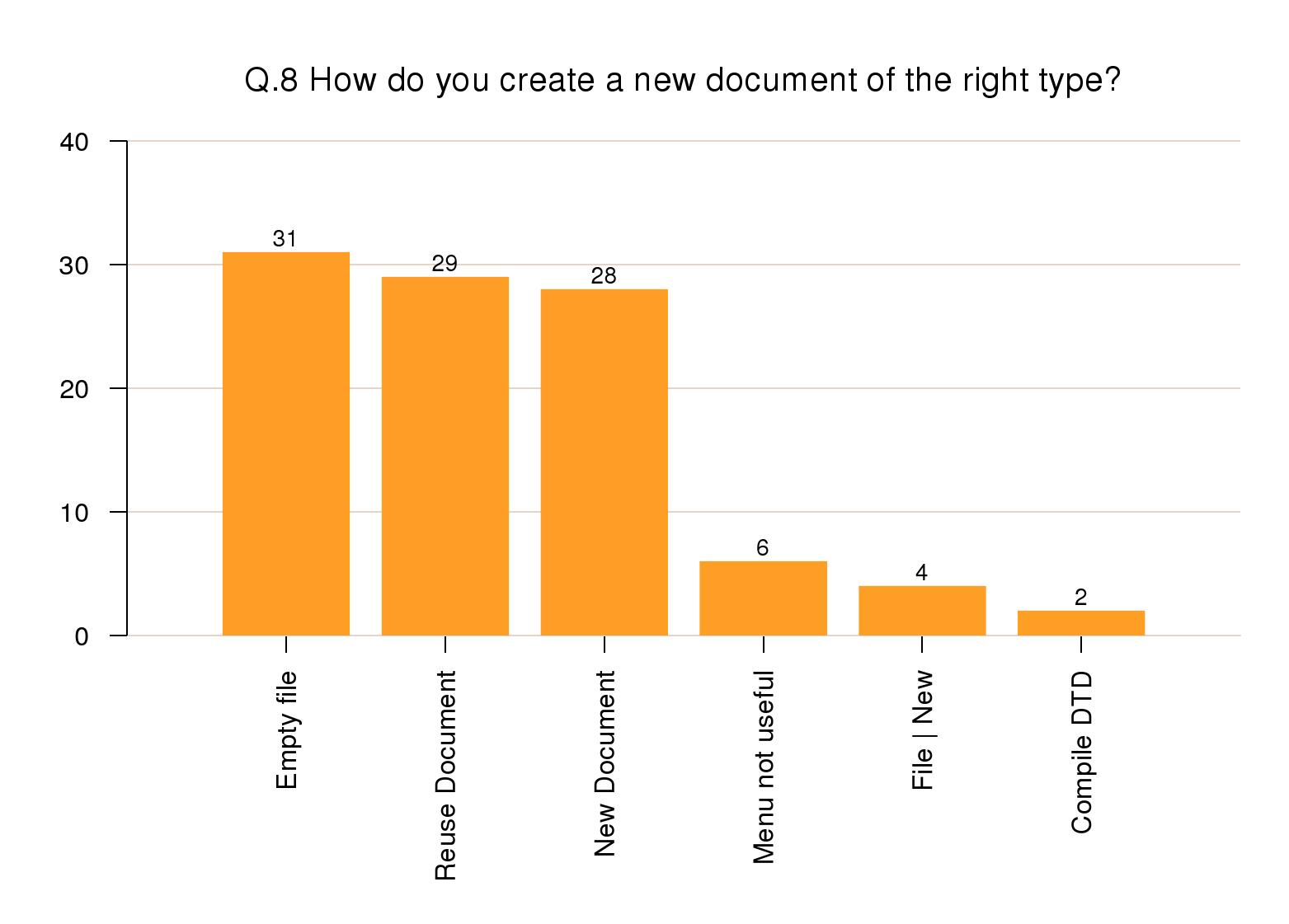
Creating a new document
The method of creating a new document was divided
approximately equally between creating an empty file
(31%), emptying an existing document (29%) and using the
New Document menu item (28%). Most of the remainder did
not find the menu system useful for creating new
documents as it was faster to do it by hand.
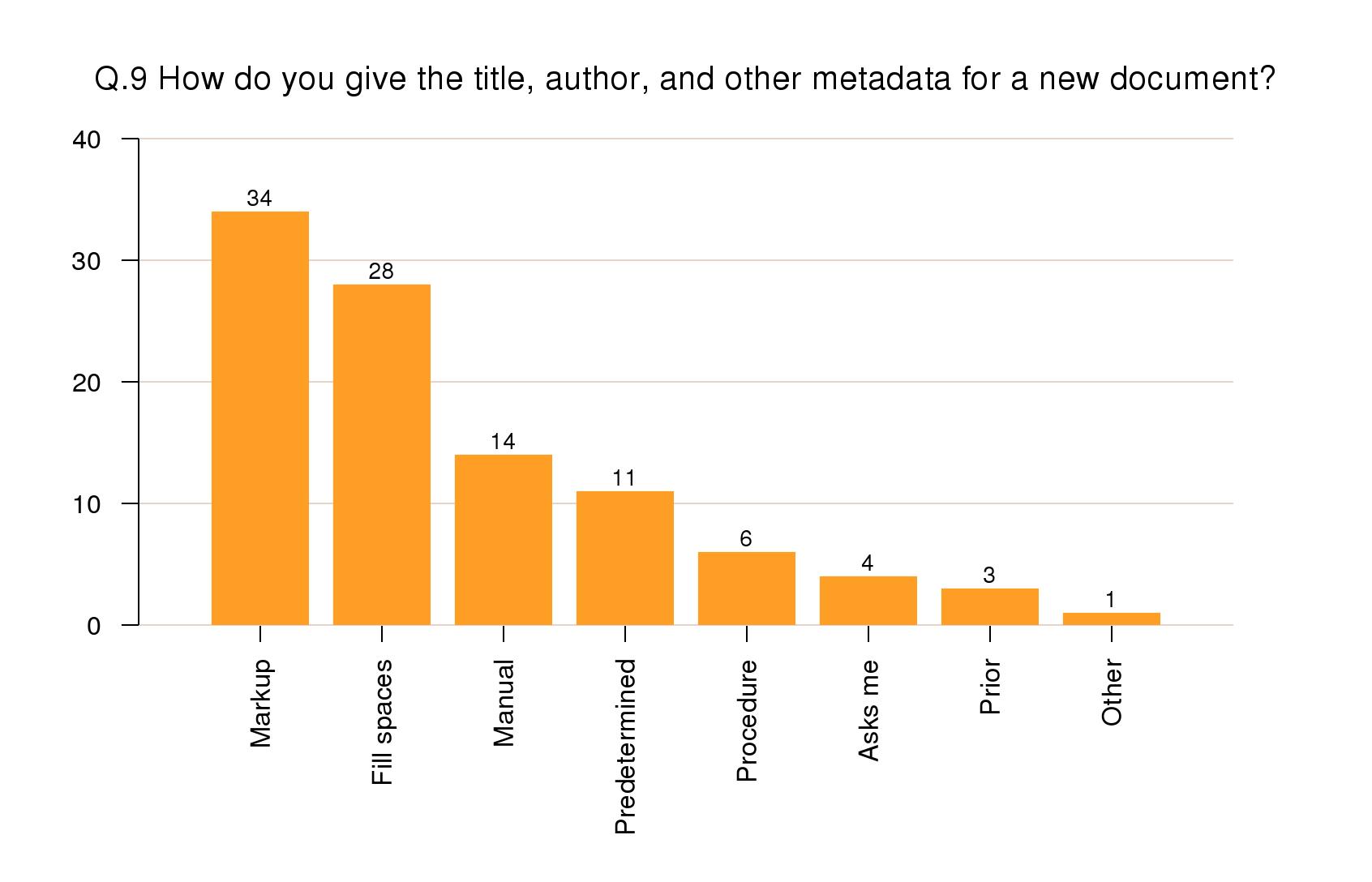
Adding standard metadata
To add metadata, 34% of responses used markup
insertion menus; 28% used fill-in-the-blanks
customizations; and 14% typed the markup manually. Most
of the rest used preset values or the metadata was
determined elsewhere.
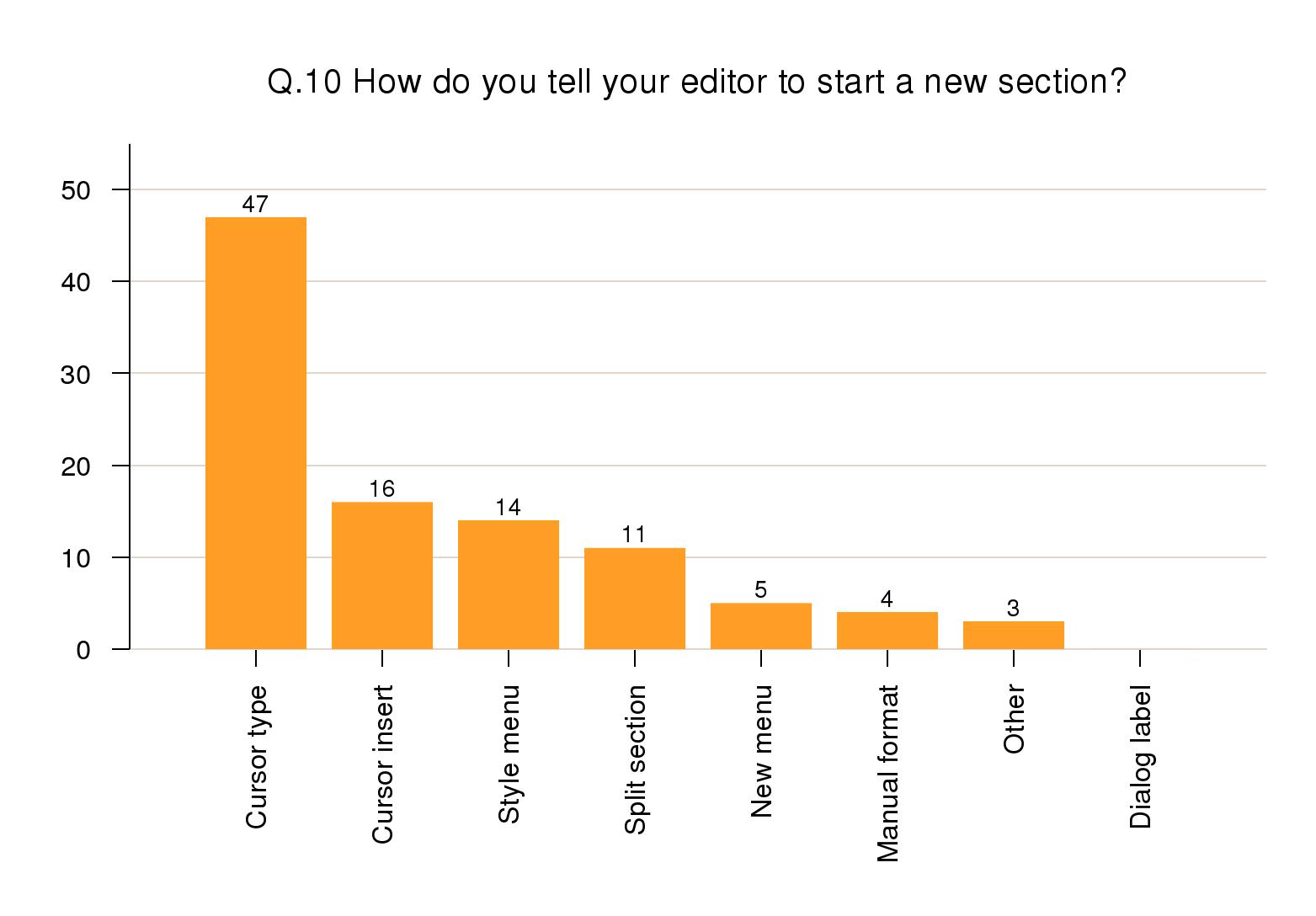
Starting a new sectional division
Nearly two-thirds of new sections were started by
positioning the cursor manually and typing or otherwise
inserting the markup (63%). Style menus were used in 14%
of responses and splitting an existing section in 11%.
Only 5% of responses used a New section
menu item.
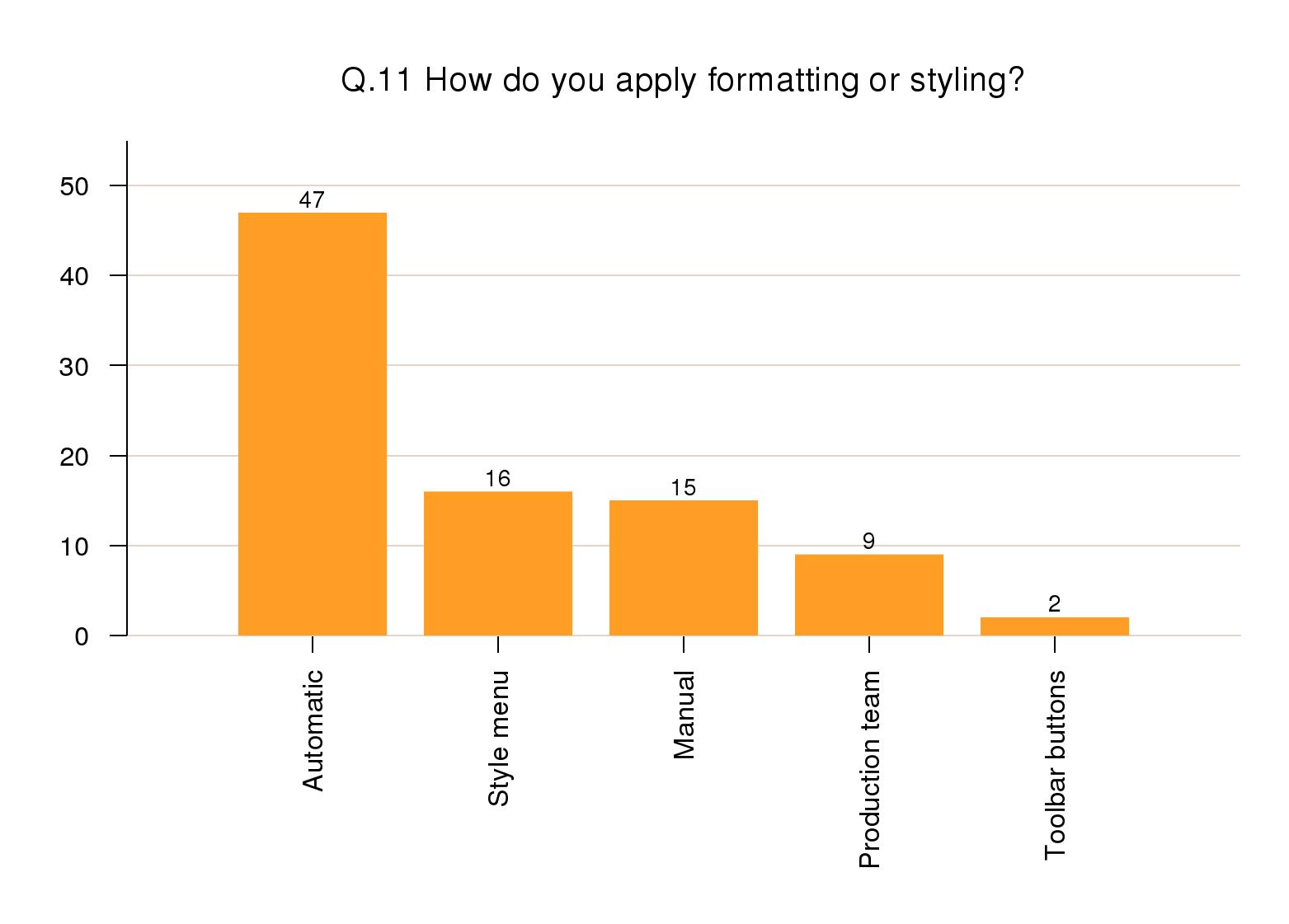
Styling a document
Nearly half the responses said styling was automated
via a stylesheet (47%). The use of a style menu and
manual styling were about equal at 15–16%, and for most
of the others it was done by a production team. Only 2%
of responses mentioned using manual methods like toolbar
buttons.
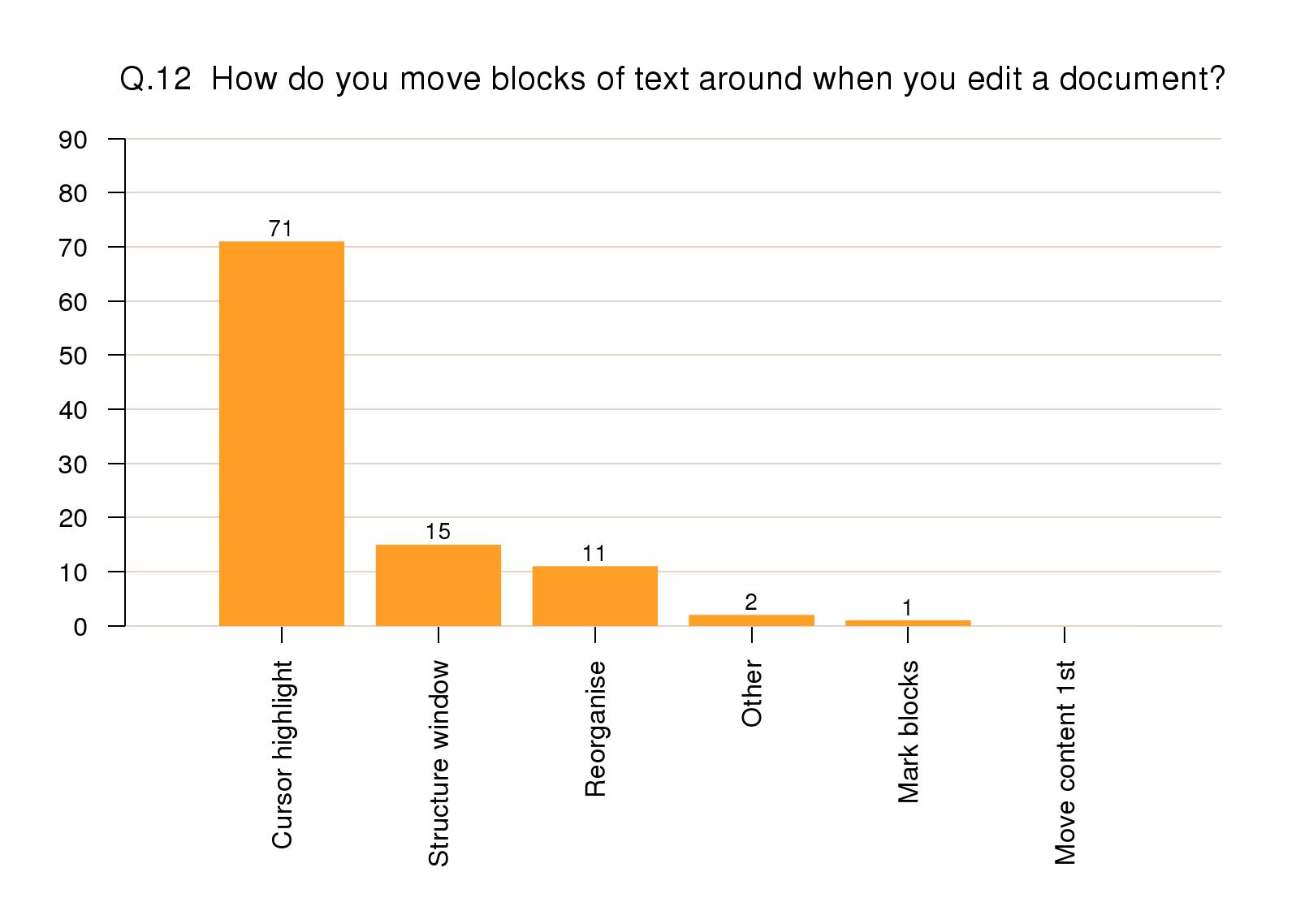
Moving element content
Moving blocks of text around was overwhelmingly done
by cursor highlighting and cut-and-paste. Only 15% used
a structure window to select the material. However, 11%
said they had to reorganize the markup manually after a
move (to promote or demote sectioning).
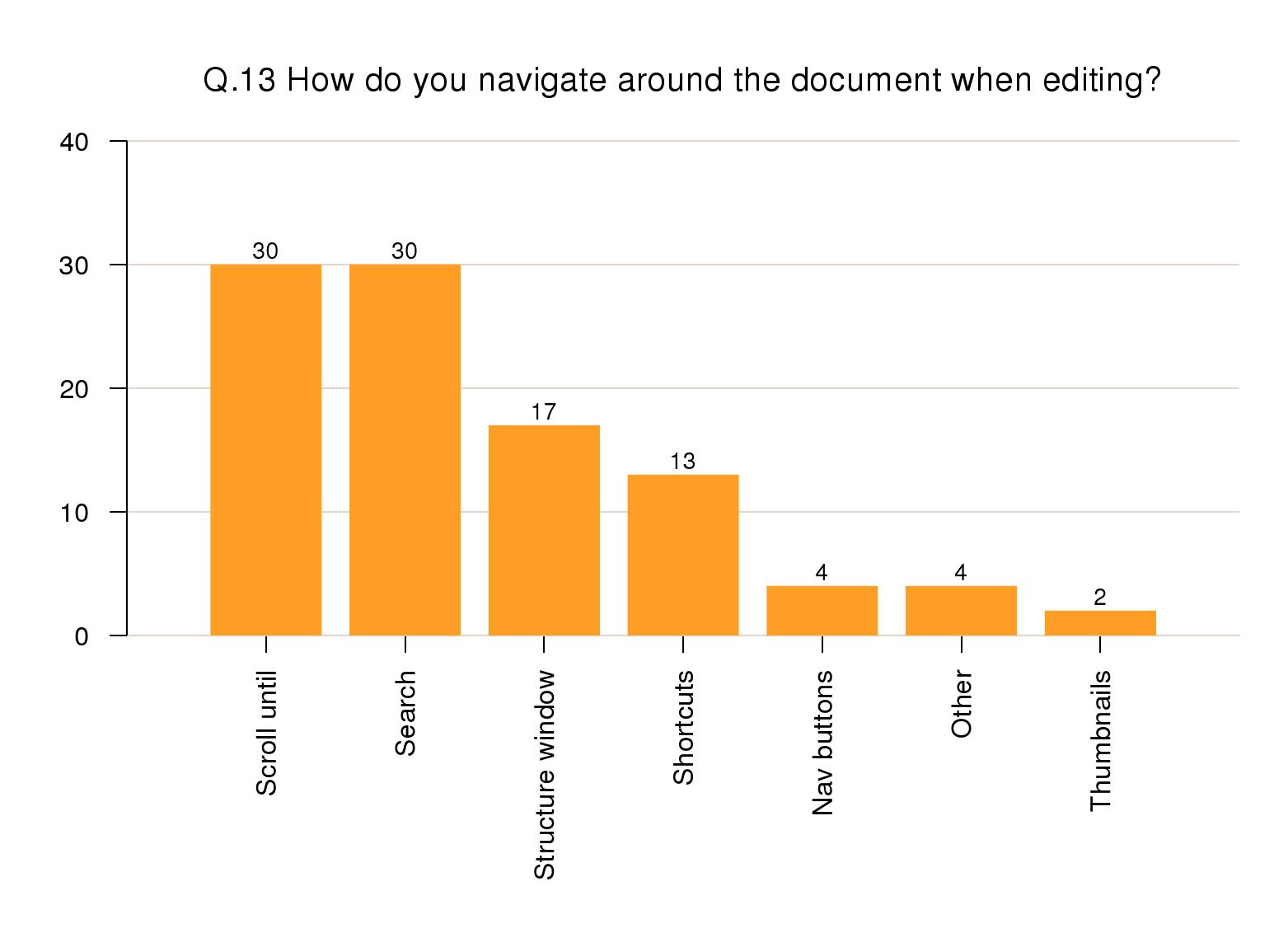
Navigating in the document
To navigate around the document, 30% of responses
used scrolling and 30% used searching. Only 17% used a
structure window, but 13% used keyboard shortcuts rather
than mouse controls.
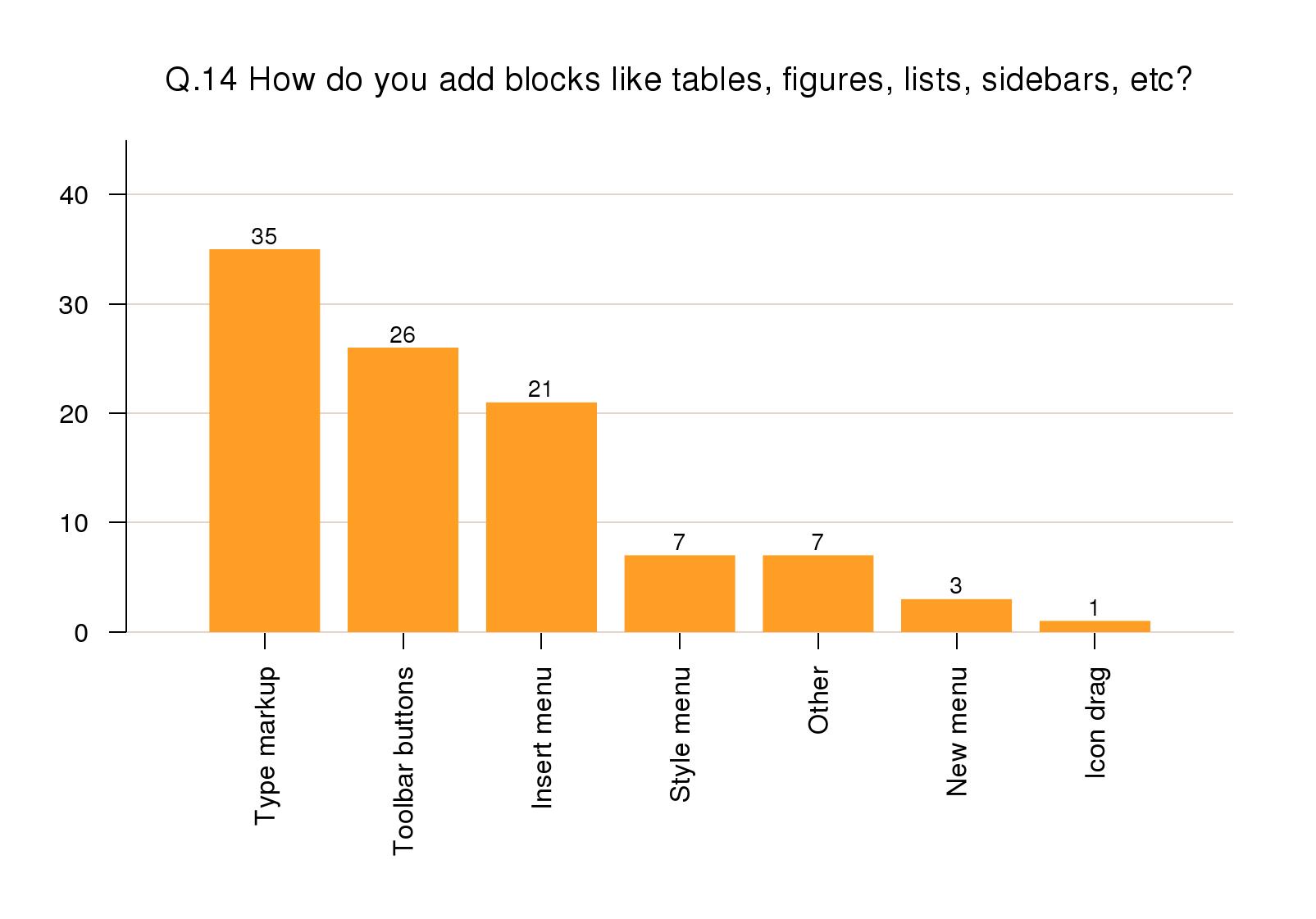
Adding new elements
To add new block-level material (elements in element
content), 35% of responses mentioned manual insertion by
keyboard shortcuts or typing; 26% via toolbar buttons;
and 21% via the Insert menu. Style-driven addition was
listed by 7% and there was another 7% of
Other which were
application-specific.
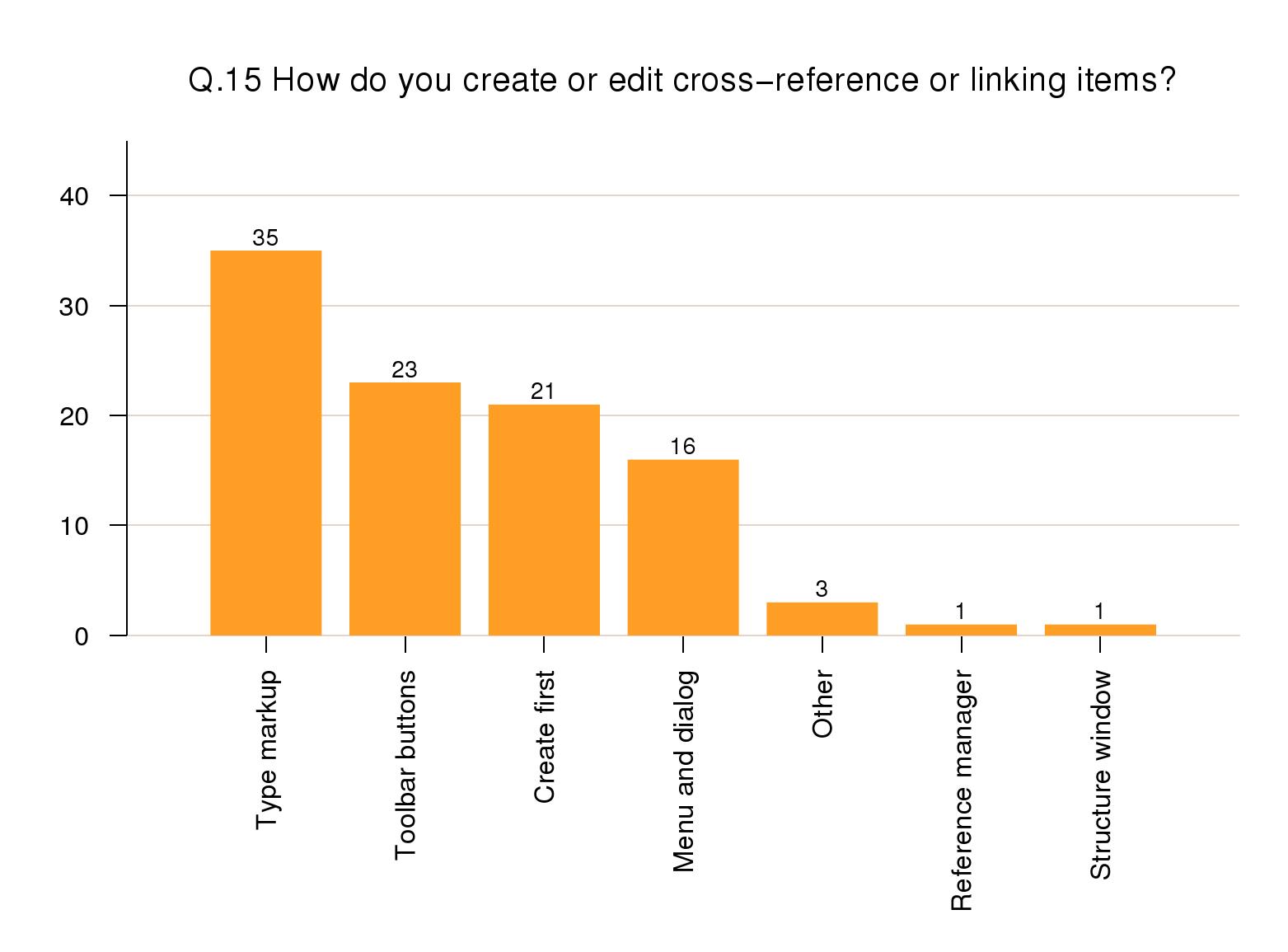
Linking and cross-referencing
For linking items (cross-references, footnotes,
citations, and hyperlinks; which are largely
mixed-content insertions), 35% again specified keyboard
shortcuts or typing, and 23% via toolbar buttons. 21%
mentioned having to create the ID target before they
could add an IDREF link to it, but 16% used a
menu-and-dialog mechanism.
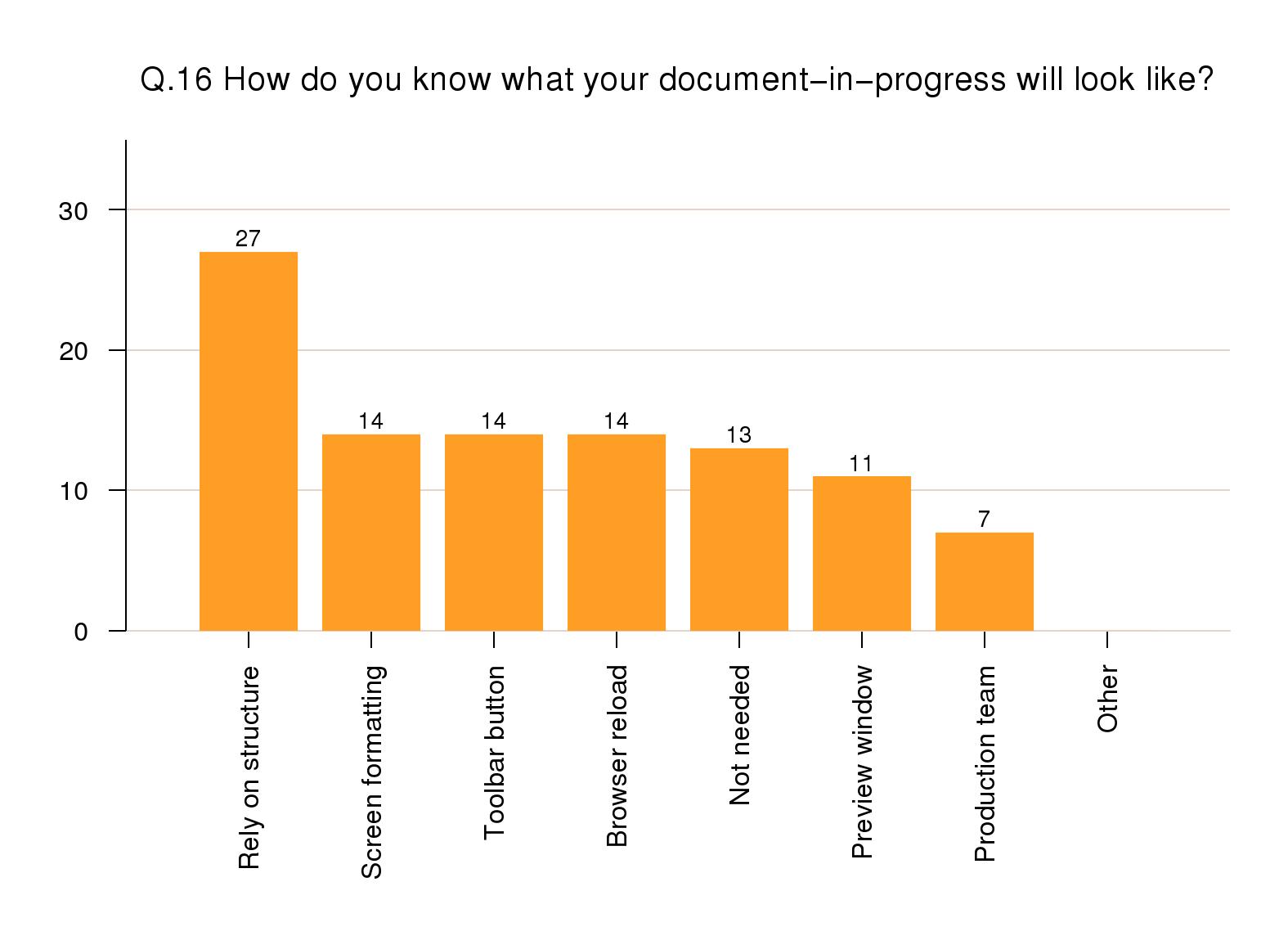
Viewing the formatted result
Fully 40% of responses did not preview a document in
development, and relied on the structuring of the markup
to ensure it would be formatted correctly. 14% felt that
the synchronous typographic display was adequate as a
check, another 14% used toolbar button to show a typeset
preview window, and yet another 14% used a browser
preview. 11% ran a continuous synchronous previewer and
7% relied on a separate production team.
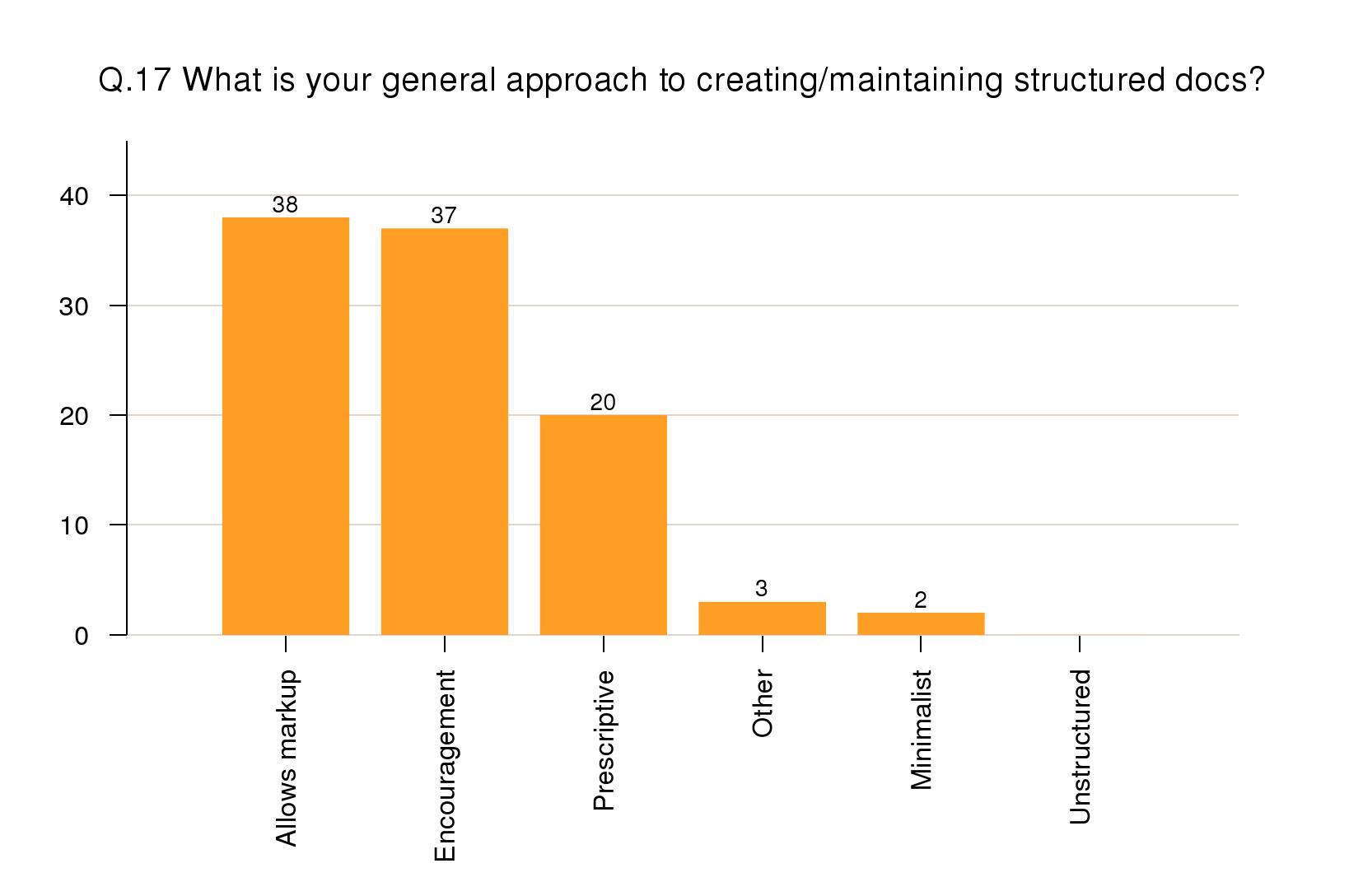
General approach to markup
On the general question of the respondents' approach
to editing, roughly equal numbers (37–38%) were
comfortable with a system that allowed them to specify
markup without prescription, and with systems than
encouraged but did not enforce a specific way of marking
up (for example, optional structural-based styling in
wordprocessors). However, 20% did prefer a prescriptive
system.
Respondents were also asked in open-ended questions about
what features they would recommend to others looking for
software; what features they found best and worst in their
software; and for any features they would like to see
added.
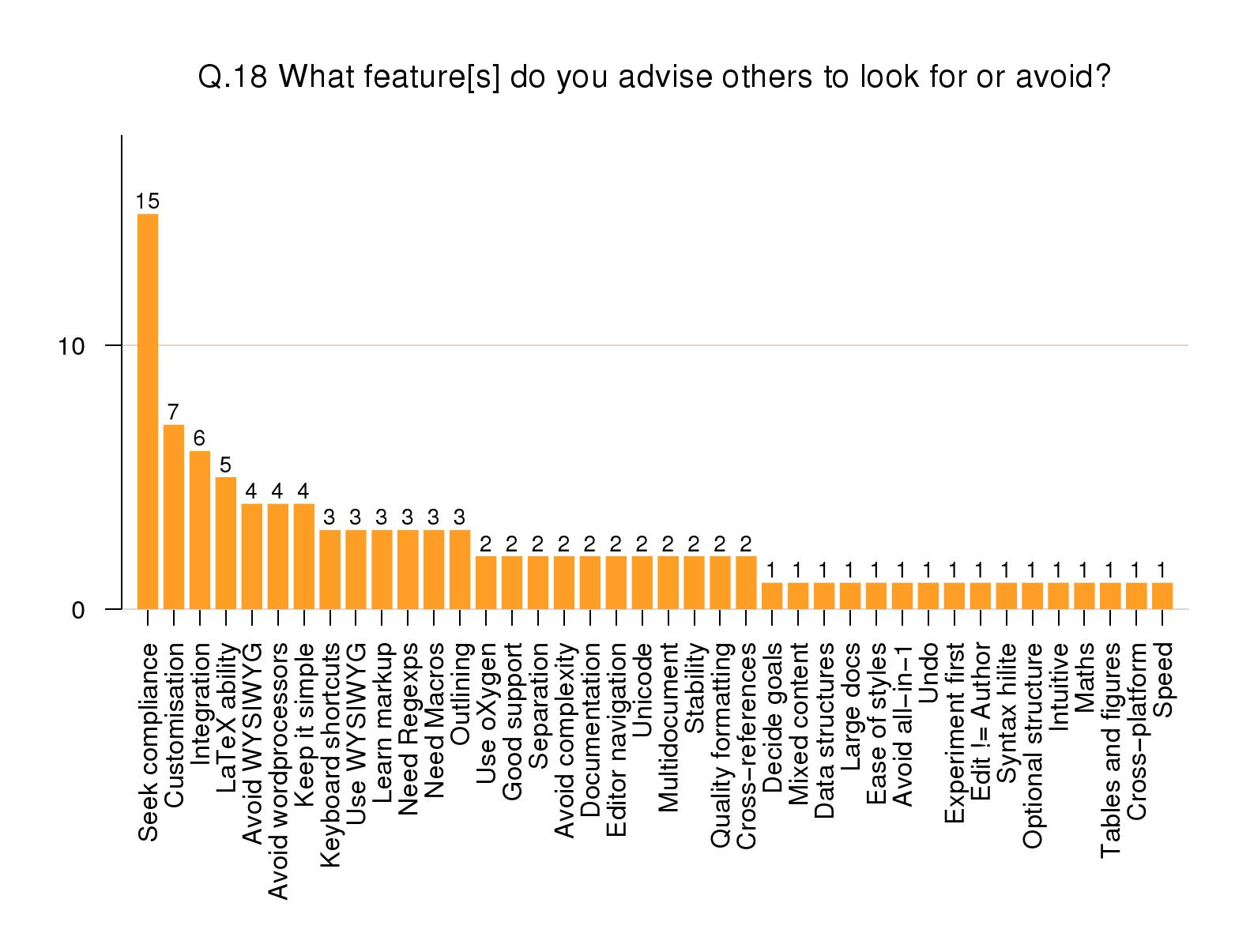
Advice to others
The most important feature was seen as robust
compliance with standards (15%). 7% recommended
customizability, and 6% felt integration with other
systems was important. Level at 4% were Avoid
WYSIWYG, Avoid Wordprocessors,
and Keep it simple (the converse,
Use WYSIWYG rated 3%). Again there was a
very long tail of other factors, but without significant
distinction.
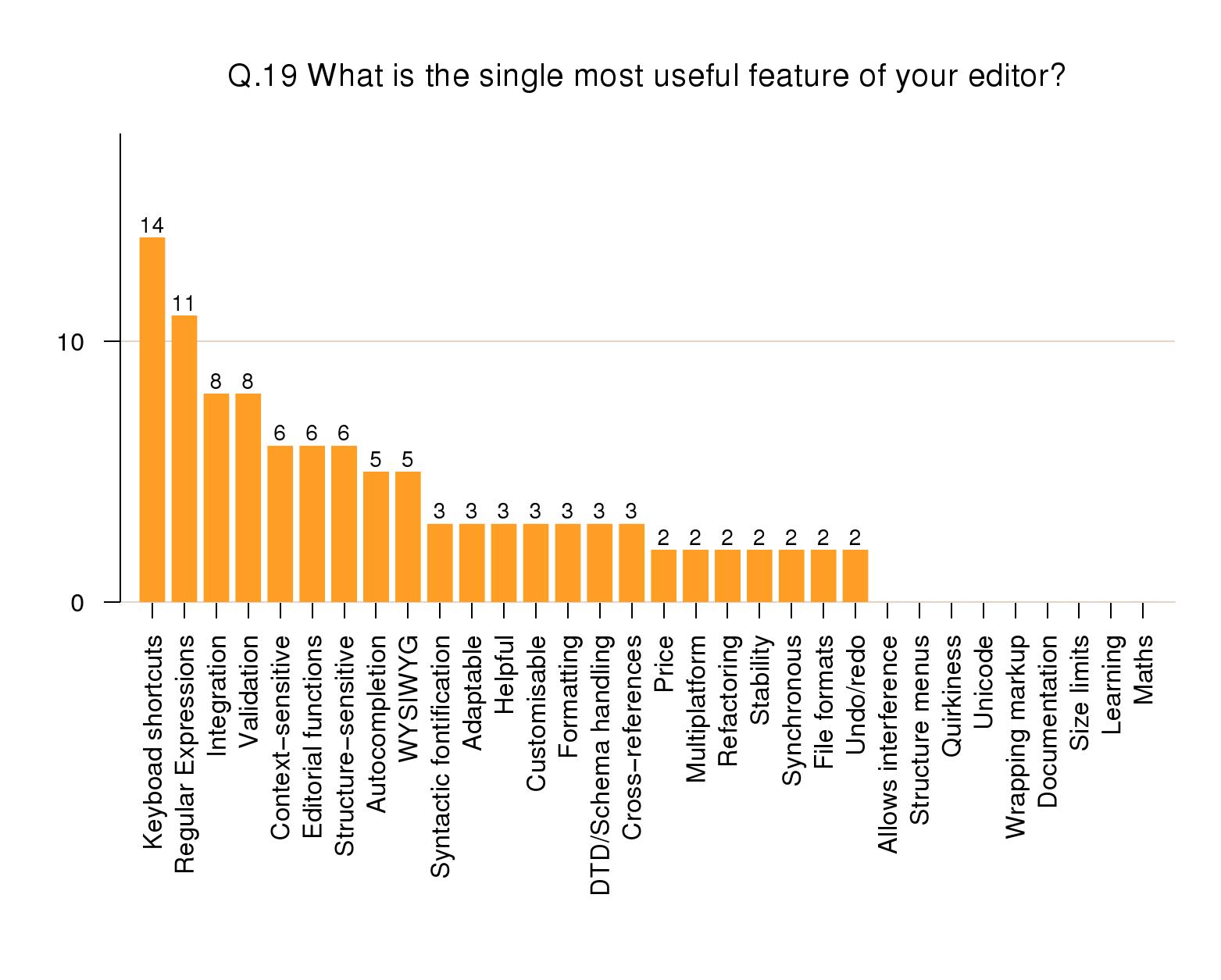
Most useful features
For usefulness, keyboard shortcuts rated the highest
at 14% of mentions. Regular Expression searches followed
at 11%, and Integration and Validation features at 8%
each. A cluster of editorial functions came next at 5–6%
each: context-sensitive or structure-sensitive editing;
spell-checking, grammar-checking, and thesaurus;
autocompletion; and WYSIWG display. At a lower level
(3%) were colored editing, adaptability and
customizability, and the quality of formatting,
DTD/Schema handling, and cross-referencing. Price and
multi-platform availability were not significant at
2%.
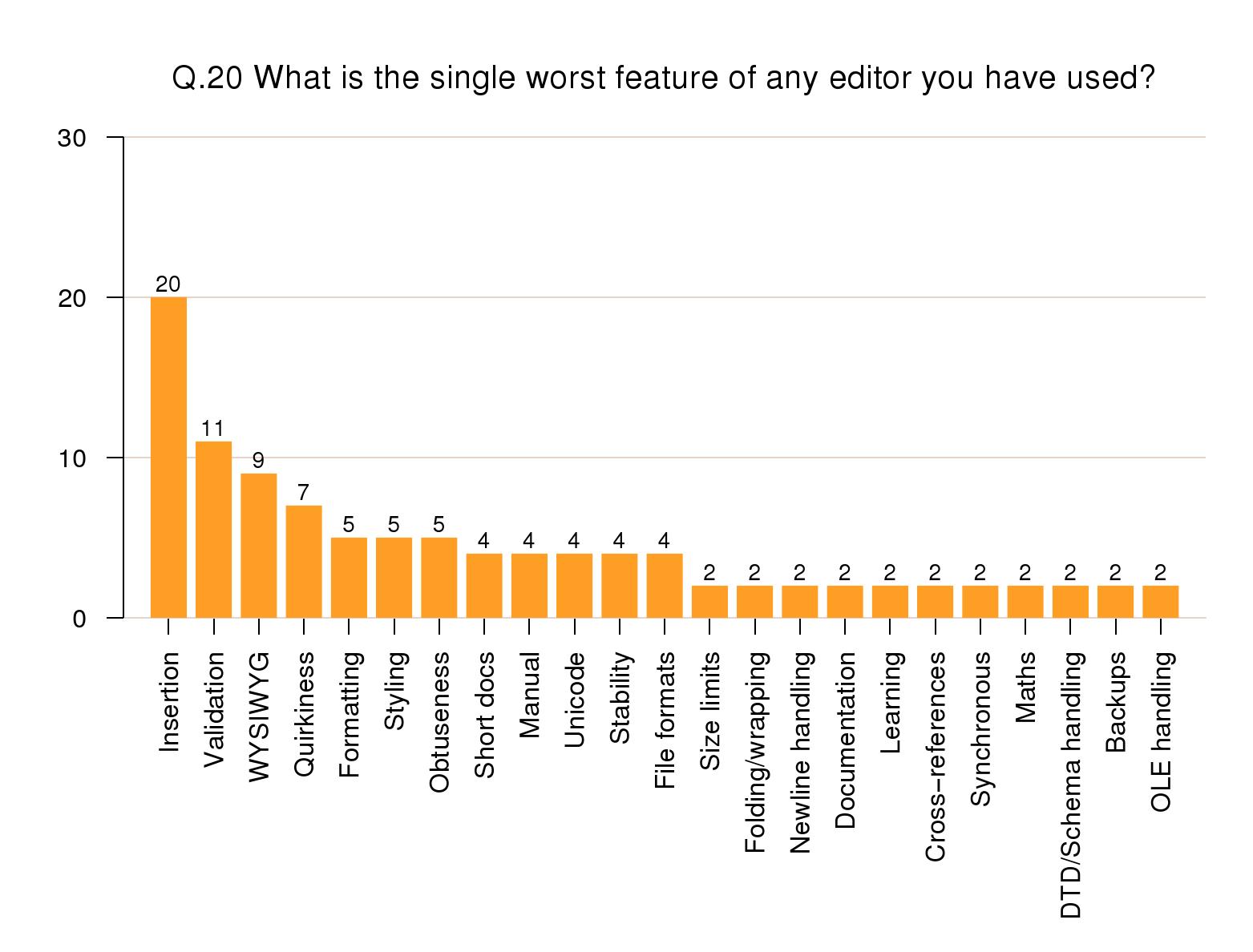
Worst features
By contrast, the worst features of editors were led
by automated or pre-emptive insertion problems at 20% —
wrong types, interference with formatting, refusal to
mark up as instructed, or insistence on adding incorrect
markup. Validation errors (faulty editors, not faulty
documents) followed at 11%, and WYSIWYG problems at 9%.
Quirkiness or obtuseness of the interface were rated at
7% and 5% respectively (failure to follow established
patterns), and matters related to styling and formatting
also at 5%. Poor documentation, the need for manual
intervention, lack of Unicode support, program
stability, and support for different file formats all
rated 4%, and there were others in a low long
tail.
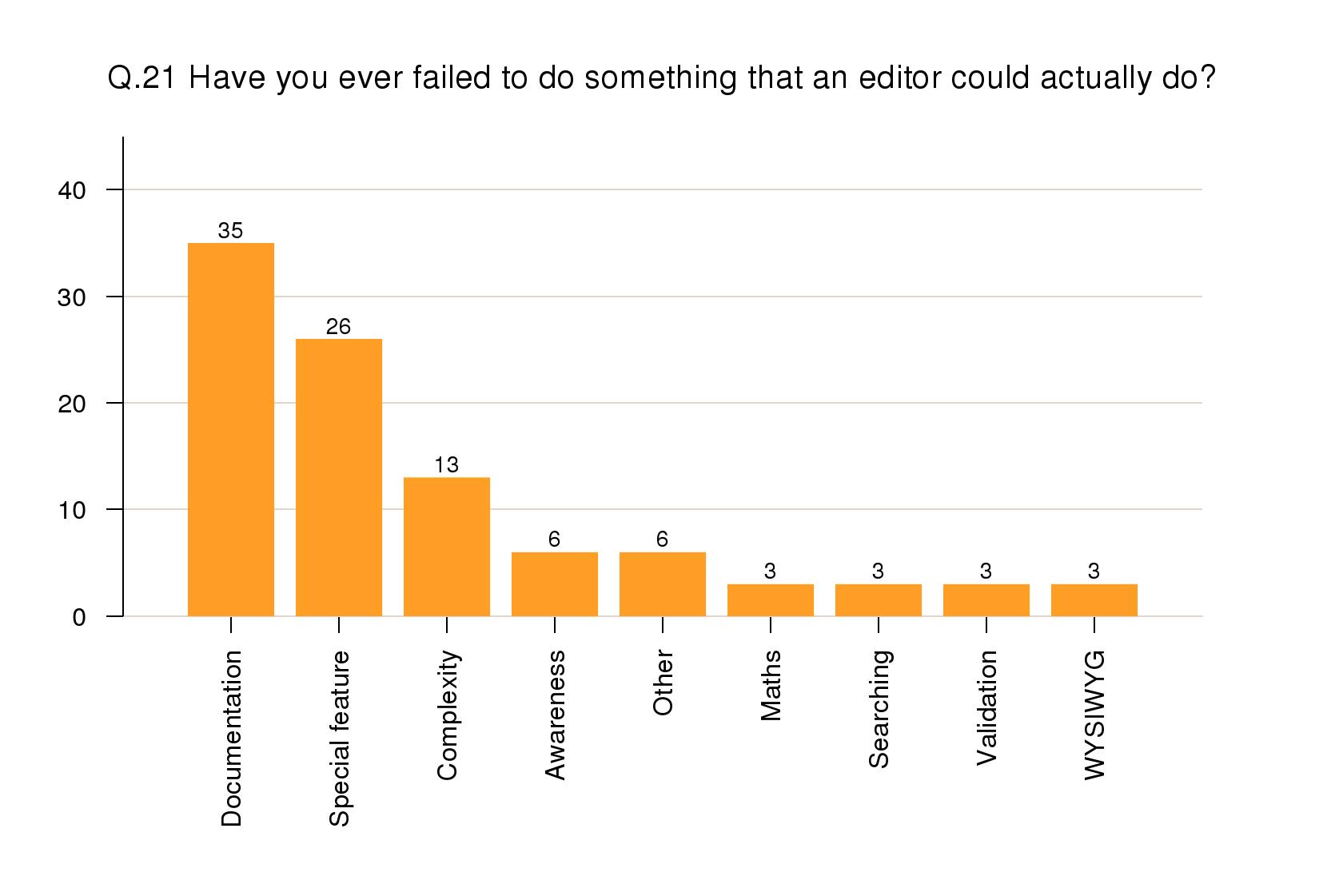
Failure to fulfil a task
When asked if they had ever failed to find out how
to do something that an editor was actually capable of,
35% mentioned the difficulty of finding items in
documentation, and 26% mentioned problems in getting an
editor's special feature (one of its unique selling
points) to work. 13% mentioned trying to overcome
unnecessary complexity, and 6% felt that such failure
was down to lack of awareness of a product's
capabilities. The tail included mathematical features,
searching, validation, and WYSIWYG problems.
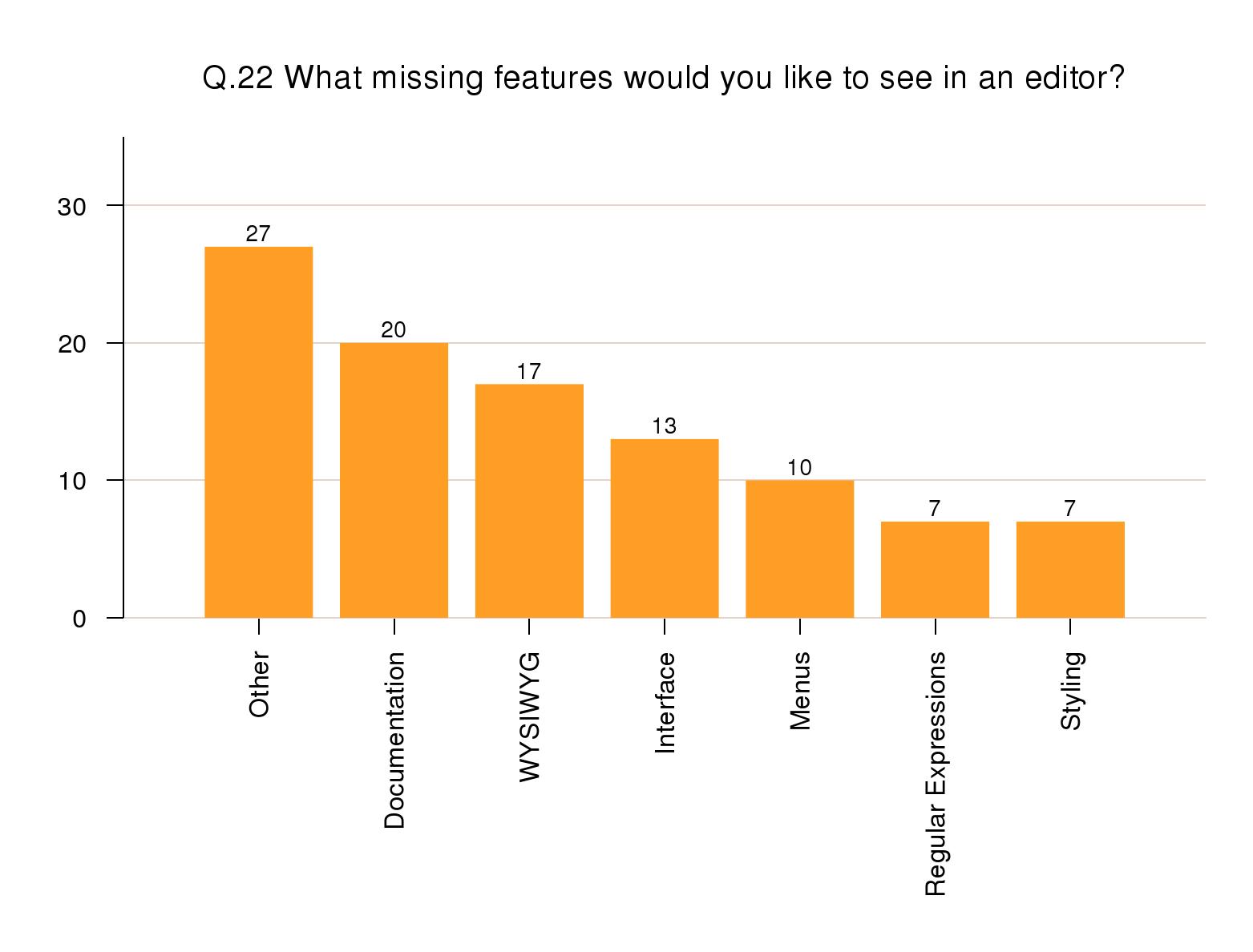
Wish list
The opportunity to add to a Wish list led the
Other category to account for 27% of
responses. Heading the remainder were improved
documentation (20%), better WYSIWYG (17%), and better
interfaces (13%) and menu systems (10%). The addition of
Regular Expressions rated 7% and better access to
styling also 7%.
Discussion
In the open-ended questions, and in the
Other areas of each question, users were able
to elaborate on their responses. In these, there was sometimes
extensive and persuasive argument both for and against the
exposure of markup, the limitation of structural control, the
adaptability of editing systems (including DTDs and Schemas),
and the conflict between how a writer perceives interaction
with a document and how the creator of the editing system
perceives it. These views — necessarily one-sided, as they
come from long-term authors with technical understanding,
rather than from non-technical writers or newcomers (see
Figure 1) — illustrate an important point
about structure which has not been widely
considered at a technical level.
While it is accepted wisdom that structure
is A Good Thing in all writing (and this has become an article of
faith in markup theory), there is a difference between what
markup experts mean by structure and what writers understand
by it. Both parties accept that there is a framework
underlying all formal documents, usually in the conventional
part-chapter-section-subsection hierarchy, with other
components adduced where needed (principally figures, tables,
lists, and their derivatives). The differences appear to lie
in the perception of the relationship of these elements to
each other.
The classical theory, derived from computer science and
graph theory, is that the document is a hierarchical tree
(actually inverted: a root-system) and that all necessary
actions can be seen in terms of navigation around the tree,
and of insertion into and withdrawal from the the nodes which
form the branches and leaves.
The conventional writer, however — and we expressly
exclude the markup expert, as well as the
experienced technical authors who responded to the survey — is
by repute probably only marginally aware of this tree; but we
have been unable to measure this at present. In this view, the
document is seen as a continuous linear narrative, broken into
successive divisions along semantic lines, and interspersed
with explanatory material in the form of figures, tables,
lists, and their derivatives. From inspection, this appears to
hold true whether it is a sales report, a novel, a textbook,
or an academic paper. The terminology used is therefore also
different: inserting a node into
the tree has meaning for the document engineer who designs the
document type or the formatting engine, but is meaningless for
the writer, who thinks in terms of new chapter
or add a paragraph.[2]
This may explain to a considerable extent why the
anything, anywhere document model in
commonly-used wordprocessors has become so pervasive: it is
virtually impossible expressly to allow an object to occur
only in a specific place, or to forbid one from occurring at
any point. The interface to such models has become widespread
precisely because it allows this latitude, regardless of
whether it makes structural sense or not, and because such
interfaces are marketed for general-purpose, ad hoc, and
trivial use, as well as for complex or sophisticated use. This
is despite the result that in terms of formal structure, all
wordprocessor documents are in effect a simple series of
paragraphs one level deep (with a small exception for those
that group list items in a container or provide containment at
the mixed-content level).[3]
It would therefore appear that the lack of adoption of
structured-editing interfaces could be due to a lack of
understanding by authors of the tree model, or to a sense that
it constrains them unreasonably during the writing process.
But the existence of the tree, and its supervention in the
interface, are artefacts of the way in which editing software
has been written, and reflections of the preoccupations of the
designers and programmers. This is made plain by the fact that
the interface of structured editors implements the tree,
rather than implementing a model of the document with which
the author is more familiar. The use of the synchronous
typographic interface (popularly, if erroneously, known as
WYSIWYG) goes some way towards hiding the
technicalities of tree-based editing, but our objective here
is to investigate the extent to which it is possible to
present writers with a model of the document which matches
their expectations rather than those of
the document engineer or programmer.
Taking this view, it is possible that an interface which
provides the existing markup facilities (from a document
engineering point of view) but replaces the
engineering-oriented or technology-oriented approach with one
more closely matched to the users' expectations, would stand a
better chance of acceptance among authors. While this has been
attempted in some recent products, it appears to have
addressed specific individual demands rather than the general
principle.
The interface is the product
The development of the graphical user interface, common
support libraries, dynamic data exchange, object linking and
embedding, context-awareness, and many other related
technologies, has led to the frequent blurring of the
distinction between applications for the user. Sending an email
can now invoke the default wordprocessor as the editor; clicking
on a hypertext link in a document will open a web browser;
following a link in a browser will open the (usually)
appropriate application for the type of file; and a table in a
document could be provided by an embedded spreadsheet object.
The commonality of the interface framework (the position of
the menus, arrangement of the toolbar, and availability of the
other affordances) increases software reusability and makes it
easier for the user to carry across skills from one application
to another; but it also leads users into a state of unawareness
of exactly which application is active at any one time. This
also provides one of the building-blocks for the development of
interface components which are generically grouped under the
banner of Web 2.0, which attempts to imbue all
visible objects with the status of an affordance.
A side-effect of this is that a large number of
applications, even across platforms, share an increasingly
common interface framework, and are increasingly expected by the
users to provide the same affordances. User tolerance for
differences based on platform, vendor, or application appears to
be shrinking, such that a new product would have to offer some
very radically new and valuable feature indeed for it to justify
breaking the conceptual mold expected by the user.
Taking into account the expectations of users found in the
survey above, there is a growing sense that the interface is the
product, and the product is the interface, regardless of the
technologies employed underneath. The structure-directed
document editing model, which requires a foreknowledge or
awareness of the underlying hierarchical document model, may
prove to be unsatisfactory in the light of this approach.
Building on the information gathered in the surveys it was
possible to construct a list of operations or actions
(keystrokes, menu items, toolbar buttons) which were seen as
problematic. This meant either that they were to be handled
specially or even avoided because of their meaning or ambiguity
(in the opinion of the expert practitioners); or that they were
opaque to the user because of terminology, placement,
expectation, or effect (in the opinion of the users).
From the requirements of users in the survey of requests to
the forums, editing software is required by most users to
be WYSIWYG; that is, to employ a synchronous
typographic interface with no markup visible to the user.
Whether or not an editor allows another form of access to the
markup (tokenized, raw text, breadcrumb, or marching display),
is not relevant for the present purpose: this is something the
software creator can choose to do or not to do.
In all cases it was seen as a priority that the behavior of
the interface should be what the user expects.
Where in some cases this becomes context-dependent, it was
regarded as essential that the behavior should
not be the simple binary-strict IR or CS
refusal on the grounds that you can't do that
here. This was cited on numerous occasions both in the
surveys and in related discussions as being The Wrong Thing,
especially when the user's action was seen as perfectly
reasonable, but simply happened to take place at a time when the
cursor position indicated otherwise.
In all cases discussed, it was seen as important to avoid
asking the user a question in order to determine what is The
Right Thing unless absolutely essential. Additional interface
features which learn from past behavior, and which allow
preferences to be set where there might be ambiguity, were
considered to be outside the scope of this model. While these
have been implemented in some systems, the present author is
unaware of any specifically related to structural editing, and
this would be an important area for future work.
It cannot be emphasized too strongly that users, and
especially intending users, vote with their feet when judging an
application by its interface. In the absence of compelling
direction from elsewhere in an organization, and where products
are essentially comparable in function, an interface's
appearance as well as its apparent usability are regarded as
actually being the product.
By contrast, when functions are widely disparate, and the
interfaces are roughly comparable, the functions may become the
product. As we saw earlier, some interfaces fail to afford
features that do actually exist in the product, and this may
provide a third effect on the perceived usability.
In all three cases the quality, behavior, performance, and
other attributes of the underlying engines and routines may only
rarely be considered by the individual user except as part of a
formal evaluation process, and may even then be dismissed in
favor of the specific attractions of a particular interface. The
importance of accurate interface usability testing
before product release cannot therefore be
ignored: while the market will always have the final say,
releasing an untested interface is likely to be
counterproductive.
The following changes to the interaction are derived from
the findings of the four enquiries (experts' survey, software
analysis, user requirements study, and user survey), and will be
subject to testing in the final phase (see section “Testing”).
Keypresses
The Enter (Return) key
In most synchronous typographic wordprocessor
environments the default action is to end the current
paragraph and start a new one (the older conflation of
new line and new paragraph has
mostly disappeared from wordprocessors but it still present
in the less capable web editors). In the case of list items,
Enter starts a new item rather than a new paragraph within
the same item.
The behavior in an environment like a list raises the
question of how to exit the list environment — how to revert
from list-item creation to normal paragraphs — when the
markup is invisible. This is critically relevant where the
system is unable to allow the placement of the cursor beyond
the end of the last environment because no markup is
visible.
The next-paragraph behavior can usually
be modified in a stylesheet, so that a given paragraph style
(for example, Title) can be programmed to create a new
paragraph of another style (eg Author) when Enter is
pressed. In tabular matter, it may navigate down a cell, or
create a new empty row. In some SGML/XML editors
investigated, however, it caused a system beep or the
insertion of white-space in mixed content.
Because of its history, there is an expected
down (linefeed) action associated with the
key, and the first two examples above conform to this (new
paragraph; new item), as does the stylesheet-directed
creation of a specific following style, and this is the
defined behavior.
The problem of terminating a list or similar
second-level container was partly solved in Emacs
psgml-mode, STiLO, and some other editors by detecting a
repeated Enter or split-element instruction (C-c RET in
Emacs) with no intervening keystroke, and interpreting this
as signaling a demand to exit to the next level up in the
hierarchy. In STiLO, a third and subsequent presses cycled
through all element types available at that level. While
this kind of complex behavior is very useful to the expert,
it is not easily guessable, and is not obvious to the
non-expert. Ctrl-Enter was adopted for this exit
container action on the grounds that it is already
familiar in the sense of a hard return, and
with the possibility that this should be configurable by the
user, perhaps via a beginner/expert mode. There appears to
be no suitable alternative paradigm from online editing
(wikis, blogs, IM) which could be adopted.
The TAB key
Informally, many experts would concur in banning this
key altogether by disabling it. Its typewriter-style use to
align text with locally-dependent locations across the
user's window is a good example of a visual-only
instantiation which is not stable.
In practice it appears to have two valid uses, given its
association with the forward direction,
especially in tabular matter.
One use is to navigate forward linearly through markup;
that is, from one element or text node to the next in mixed
content, identifying its location in a telltale or highlight
(this might solve the problem of cursor placement beyond the
last text node referred to above); and from one element to
the the next in serial order in element content, in effect
performing a width-first traverse.
The other use is as an Insert Table key
when outside a table, moving to the next available location
where a table make sense; and it would revert to the
traditional spreadsheet-style cell-to-cell traverse when
inside a table. Both uses were designed to be tested.
The spacebar
Apart from inserting spaces in character data content,
there appears to be no other legitimate use for the key in a
structured editing environment. Its use as a pager key in
Unix-based systems and its adoption by web browsers for a
similar purpose, as well as its use as a button or link
selector, is be avoided in the current context except for
accessibility functions when using the menus and
toolbars.
Backspace and Delete
Backward and forward deletion in character data content
would operate as expected. When adjacent to a markup
boundary, however, it seems reasonable that deletion should
continue in the same direction by jumping linearly to the
next point where character data exists (if any; attribute
values excluded), possibly accompanied by a transient audio
or visual warning.
Another possibility is that when all character data
content has been deleted from an element, and all descendant
elements are similarly empty, an additional press of one or
other of these keys should remove the containing element
itself. This would conform to the expectation of deletion
associated with both keys, but requires separate testing as
it may or may not conform to the user's expectations when
content has already been deleted, as the user will be
unaware of the existence of any empty markup structure when
there is no character data present.
Menu items
The NEW menu item
Many writers on interface usability deprecate the use of
nouns and adjectives on toolbar and menu labels, and insist
that using verbs or attributes allows greater comprehension
(the canonical example being [Apple2008]). In many cases they are right, but
in the case of software for writing, the terms commonly used
(in English) include phrases such as new
chapter, new paragraph, or
new section, and these are so prevalent a way
of expressing the action that they justify being collected
under a menu or toolbar button labelled
New.
The first encounter with this is already familiar in
many editors as New Document, which allows
selection from a set of precompiled DTDs or Schemas. The
user indications in the survey were that such a set needs to
be very much wider, and must allow a much easier method of
adding new document types. (Although that activity is
outside the scope of this study, it does have implications
for document type and stylesheet designers and for the
introduction of a robust means of element type and attribute
hint documentation.)
The use of Insert (which we discussed
earlier), or Surround/Enclose,
are always restricted to the element types available at the
current cursor location (which may be indeterminable by the
user when no markup is visible). By contrast, a selection
from a New menu moves to the next available
location where the selected item can be inserted, if the
current location precludes it. If the user asks for a new
chapter, and their cursor is currently in the middle of an
acronym, they do not mean literally insert the new chapter
markup there, or recursively split elements until a valid
insertion point is reached; they mean go to the next place
where a chapter can start, and start it there.
When requesting the insertion of inline markup in mixed
content, however, Add may be convenient
semantic sugar for New (as in add
quote, add emphasis). The same
principle of next available location would be
honored, as such markup can usually occur arbitrarily in
mixed content.
As a corollary to this principle, where a new element
has required element content, all
required element types must be added, and the focus then
returned to the first location of character data. Where
there is a required choice, that must be presented to the
user (one of the unavoidable occasions, and perhaps a
suitable opportunity for the implementation of the first
mode of TAB key operation explained above).
Formatting controls
Given that a synchronous typographical editor operating
with a stylesheet would not normally have any use for the B,
I, and U buttons, nor for the typeface and font-size
dropdowns, it is tempting to abolish them completely except
when in style-creation mode.
However, as the user expects to be able to control
formatting from the menu and toolbars, the B, I, and U
buttons should operate a drop-down of all the available
markup which uses those styles in the current stylesheet.
For example, as we have pointed out elsewhere, there are at
least eight reasons[4] why an author or editor might want to
use italics,
foreign words
scientific names
emphasis
titles of documents
names of products
mathematical variables
headings
decoration
and probably as many again for bold and
underlining combined [Flynn2002].
By the same token, the typeface dropdown (restricted to
those faces in use by the stylesheet) can be used to select
from those elements currently employing those faces; and the
font-size dropdown to select those employing those sizes.
The effect for the user is identical to the existing usage,
and requires no additional mouse-click, only a longer dwell
time and a move to select the right usage.
A similar argument can be made in favor of other visual
selectors such as color. In stylesheet-editing mode, if one
is provided, the buttons and dropdowns may revert to
conventional usage to allow new styles to be constructed or
existing ones to be modified.
The toolbar
Many remaining items on a conventional toolbar can to a
large extent be replaced by markup-oriented controls when
working with a stylesheet, using the principles given
above.
Toolbar items with an application in markup control,
such as those for use with tabular setting, can of course be
retained largely unchanged, but by the same token they must
disappear from the toolbar when the DTD or Schema has no
tabular elements: a corollary of providing the user with the
best affordances possible is that inapplicable ones should
be eliminated.
The non-markup document controls such as Save, Open, and
Print are of course retained in their normal form.
Additional buttons for cross-reference management,
citation, indexing, and other apparatus common in structured
formal documents are added where the DTD or Schema provides
for such facilities. These are already familiar to many
users from reference management software.
Generic tools such as spellcheckers, thesauruses, and
grammar-checkers remain unaffected, but they need to be
relevant and up-to-date: a number of applications tested
failed to include common technical terms like
filetype as well as recent everyday words
like blog and wiki.
Other
Referencing
For normal cross-references (assuming the ID/IDREF
mechanism is used), adding a reference to an existing target
is non-problematic, requiring only a pop-up of available
targets, or acceptance of a scroll to the target and a click
on it). An attempt to add a reference to a non-existent
target must create a placeholder for the point of reference,
and then require the user to identify the target, completing
the resolution when the target is established. In both
cases, the stylesheet must know the correct generated text
to add at the point of reference, if any, either based on
the element type of the target (table number, section
number), or as a page number. In all cases, moving the
target ID to another element will update all references to
it.
For bibliographic references, the stylesheet must
contain sufficient information for the correct formatting
style (or choice) according to the conventions of the
discipline. A similar behavior to the normal cross-reference
action can be assumed when the reference entries are
embedded in the document (as is possible with DocBook or
LaTeX, for example), but this can be pre-empted by dragging
and dropping a reference from an external citation database,
either maintained locally like Zotero, Endnote, or BIBTeX,
or from suitable data in a browser page on a journal or
reference database site; with the ID resolution being
satisfied by the inclusion of the referenced item in a
suitable format at the end of the document.
Mathematics
The visual control of mathematics poses special problems
which have been addressed in several models developed by
software writers and vendors (Euromath, Arbortext, LyX,
Scientific Word, and others), and is not considered
here.
Unstructured editing
Several respondents to the surveys mentioned the need
for systems which deduce structure while the author writes
without structural controls; for systems which can open
documents with broken structure (that is, badly-formed or
invalid documents) in order to allow them to be mended; and
for systems which allow incomplete but otherwise well-formed
or valid documents to be saved for later completion. While
these are unquestionably still needed [Birnbaum1997], and mechanisms for their instantiation
have been available for many years [Shafer1995], they are outside
the scope of this research.
External files
The use of drag-and-drop is an essential interface
component for the inclusion of images, real-time updates,
file objects, and other linking actions (like the
bibliographic citations mentioned earlier), although
traditional attribute entry of filenames and URIs must
remain accessible. The embedding of local (file:///) URIs is
deprecated for reasons of non-portability, but no viable
solution is apparent for standalone usage without widespread
adoption of a catalog method (below). The embedding of
non-standard methods such as links to OLE objects and local
email repositories is a particular difficulty.
A particular demand was seen for the management of
external entities, both parsed and unparsed, as this was
given as a deficiency in many editors. The use of XML
Catalogs is regrettably under-developed.
Character data
It ought to be unnecessary to mention explicitly, but
all visible (printable) keyboard characters — indeed all of
the Unicode repertoire — must be accepted without error.
With markup hidden, there can be no excuse for markup
characters entered from the keyboard being interpreted
as markup characters.
Where letters or symbols from outside the base character
repertoire of the document are entered, editors for systems
which require additional facilities to handle them (such as
LaTeX) must automatically add the relevant modules
(packages) to the Preamble (an approximate equivalent to the
Internal Subset of an XML document).
Editing
The cut/copy/paste actions applied to character data in
text nodes behave as normal. The three-button equivalent
mouse actions common in some systems must remain available.
Embedded whole-element markup in mixed content is
cut/copied/pasted with any marked surrounding character
data, but will silently disappear if pasted into a location
where that markup would be invalid (see the rules governing
Target Markup Adoption below).
The paradigm of clicking on the start-tag to mark the
whole of an element is inapplicable when markup is
invisible, and a tree or other diagrammatic representation
of the document in a side-pane may be confusing for the
non-expert, but an equivalent style-oriented margin similar
to Word's allows whole-element selection in element content,
as does the three-click selection in Mac OS X.
Cutting (or copying) whole elements in element content
and pasting them elsewhere is subject to the rules of the
DTD/Schema in use. If the user attempts to paste the
material into a location where the markup would not be
permitted (into mixed content, for example), the markup in
the clipboard content is removed down to the mixed content
level, and the result pasted as mixed content. Pasting
whole-element material from element content into element
content at a higher or lower level automatically promotes or
demotes the container of the clipboard content to a suitable
level to be allowed.
Highlighting across markup boundaries copies the marked
character data and any embedded whole-element markup. As
mentioned above, cut/copy and paste then work on the text
nodes in mixed content and any whole element nodes included
in the selection. A principle which we term Target
Markup Adoption determines that pasting
fragmentary mixed content adopts the style of the target
container and not the source style,
whereas pasting whole elements (in element content) retains
the internal consistency of styling, subject to any
inheritance or disinheritance at the target location. This
principle is already in partial use in some embedded XML
editors designed for web applications.
An attempt to apply (inline) styling to marked text
across element boundaries will surround any text with the
appropriate markup where permitted, but leave text unmarked
in elements where the relevant subelements cannot be
applied.
Testing
Implementing this in program code would, in effect, mean
rewriting a large part of the interface of an existing editor,
or writing an entire new one from scratch. As this is beyond
the scope of the research, the Paper Prototyping method of
testing is being used [Snyder2003].
This involves preparing sequences of screenshots or
facsimiles on sheets of paper, and giving test subjects tasks
which they carry out by indicating on the sheets what action
they would take. The tester then replaces the sheet with the
one which shows the result of that action, and the process is
repeated. A record of the sequences is kept for analysis. The
use of Personas (constructed psychological profiles of
canonical users) enables experienced test subjects to match
responses to those of the target audience. Testing will be
carried out in the Usability Laboratory of the Human Factors
Research Group at University College Cork.
The actions and behaviors are specified as sequences of
keystrokes or mouse movements, and prepared for testing using
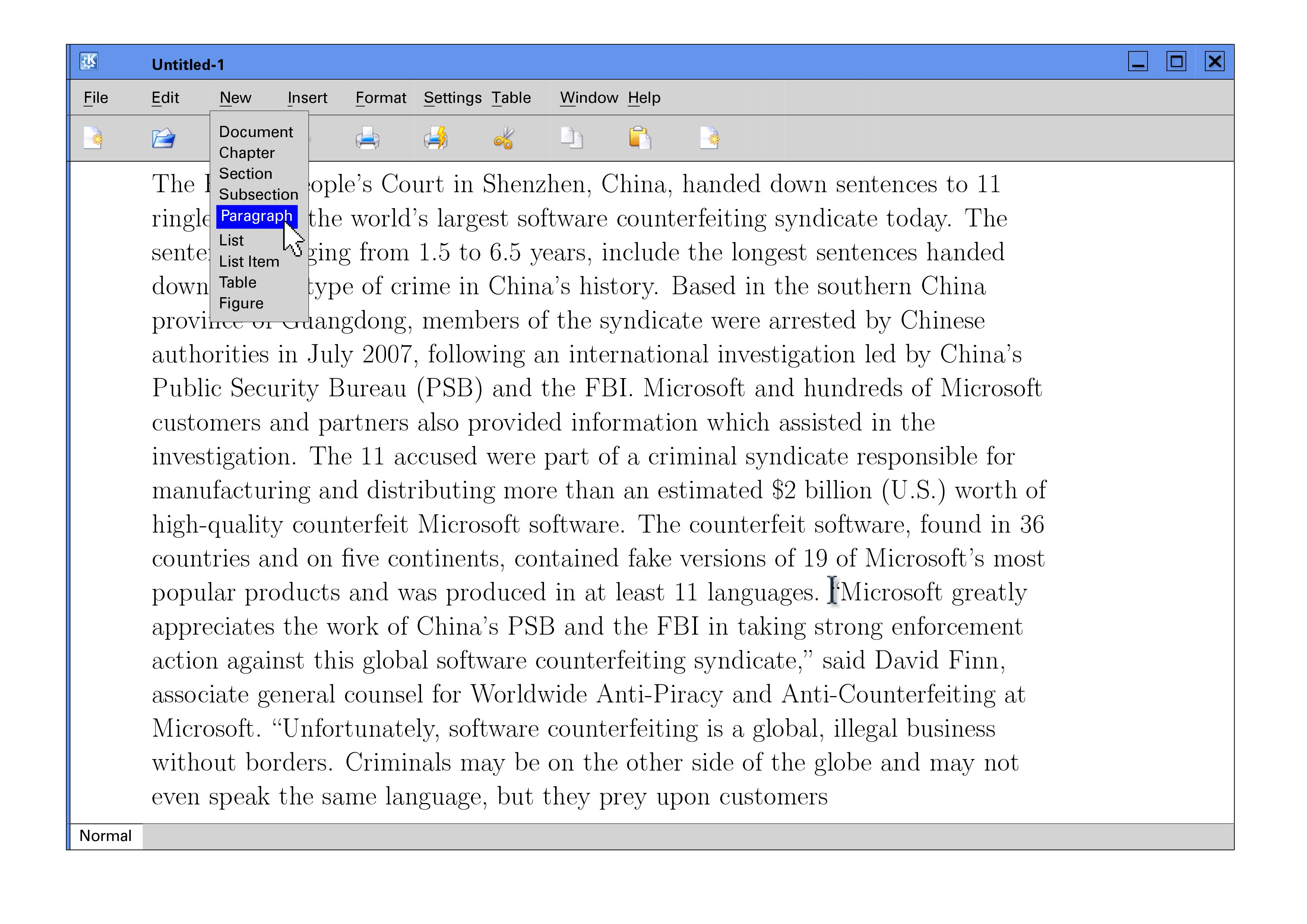
generated simulations of screenshots (see Figure 3.
Figure 3: Paper prototyping: simulated screenshot of model
editor
Use of the New menu in mixed
content
Duplicates of each screen using the existing interfaces of
OpenOffice, Word, or oXygen as appropriate will be used for a
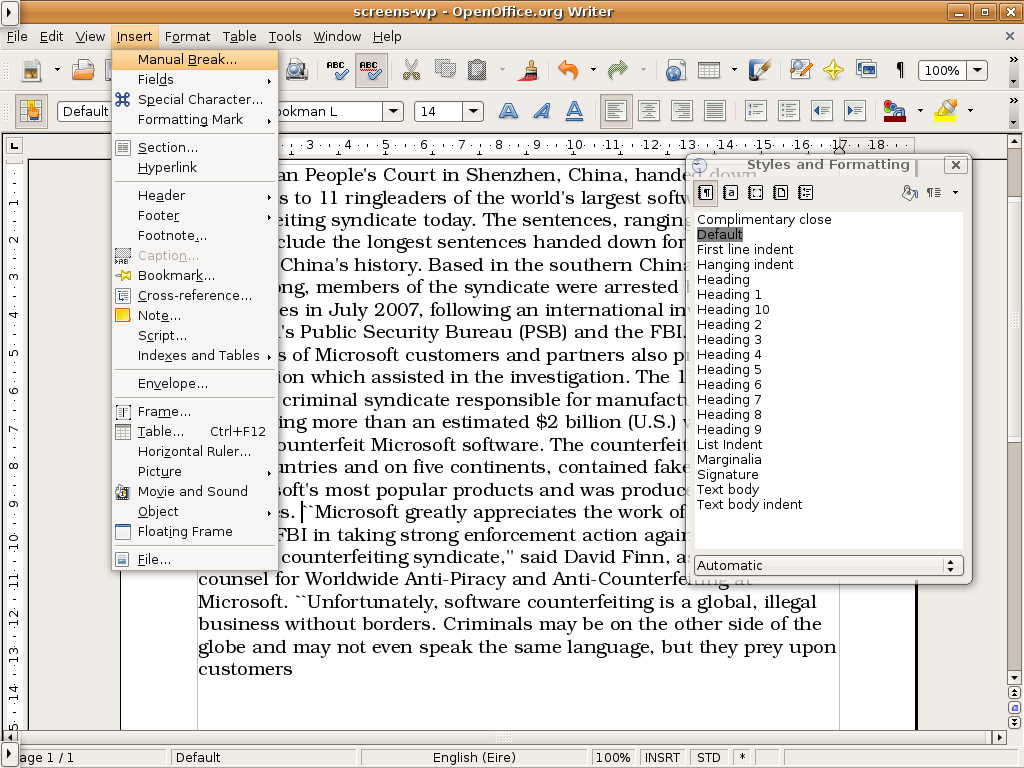
control sample (seeFigure 4.
Figure 4: Paper prototyping: control screenshot using
OpenOffice
Inserting a paragraph break
Testing will be conducted in the autumn of 2009.
References
[Anghelache2004] Angelache,
Romeo: The Meaning of Scientific Documents. In
New Developments in Electronic Publishing (AMS/SMM Special
Session, Houston, May 2004), ECM4 Satellite Conference,
Stockholm, June 2004 pp. 5–7.
[Birnbaum1997] Birnbaum,
David: In Defense of Invalid SGML. In Proc.
Annual Joint Meeting of the Association for Computing in the
Humanities and the Association for Literary and Linguistic
Computing, Kingston, Ontario (1997)
[Denning1986] Denning, Peter
J: Electronic Publishing. Technical Report 86:21,
NASA Ames Research (Oct 1986)
[Flynn2006] Flynn, Peter:
If XML is so easy, how come it's so hard?: The usability
of editing software for structured documents. Extreme
Markup Conference 2006, Montréal, QC (Aug 2006)
[Gibson1979] Gibson, James
J: The Ecological Approach to Visual
Perception. Houghton Mifflin, Boston (1979), p.36
et seq.
[Heck1993] Heck, André:
Electronic Publishing and Advanced Information
Retrieval. In Astronomical Data Analysis Software and
Systems II, 52 (1993)
[Lariviere2006] Larivière,
Vincent; Gingras, Yves; and Archambault Éric: Canadian
collaboration networks: A comparative analysis of the natural
sciences, social sciences and the humanities. In
Scientometrics 68:3 (Dec 2006) pp.519–533. doi:https://doi.org/10.1007/s11192-006-0127-8.
[Lombardi1983] Lombardi,
John V: Computer Literacy: The Basic Concepts and
Language, Indiana University Press (1983)
0253314011
[Shafer1995] Shafer, Keith:
Creating DTDs via the GB-Engine and Fred. OCLC
Online Computer Library Center, Inc., Dublin, Ohio
(1995)
[Snyder2003] Snyder, Carolyn:
Paper Prototyping: The Fast and Easy Way to Design and
Refine User Interfaces. Morgan Kaufmann, San Francisco
(2003) 1558608702
[1] Or, indeed, LaTeX. Or even stylesheets for Word or
OpenOffice.
[2] In the case of narrative or dramatic literature,
structure has entirely other meanings, and
concerns plot revelation, narrative pace, character
development, and other factors completely unrelated to our
use of the term.
[3] Containment has its own perils: the author has an
example of an OpenOffice document, a book of a dozen
chapters by different authors, in which the editor
unwittingly pasted chapters two to twelve into the bounds
of the last endnote at the end of the first chapter. The
publisher asked for some endnotes to be subsumed into the
text, and when the editor deleted the last endnote of the
first chapter, all the remaining chapters vanished from
the document.
[4] To which might validly be added
illustrative for authors of manuals on
typography.
Angelache,
Romeo: The Meaning of Scientific Documents. In
New Developments in Electronic Publishing (AMS/SMM Special
Session, Houston, May 2004), ECM4 Satellite Conference,
Stockholm, June 2004 pp. 5–7.
Birnbaum,
David: In Defense of Invalid SGML. In Proc.
Annual Joint Meeting of the Association for Computing in the
Humanities and the Association for Literary and Linguistic
Computing, Kingston, Ontario (1997)
Flynn, Peter:
If XML is so easy, how come it's so hard?: The usability
of editing software for structured documents. Extreme
Markup Conference 2006, Montréal, QC (Aug 2006)
Larivière,
Vincent; Gingras, Yves; and Archambault Éric: Canadian
collaboration networks: A comparative analysis of the natural
sciences, social sciences and the humanities. In
Scientometrics 68:3 (Dec 2006) pp.519–533. doi:https://doi.org/10.1007/s11192-006-0127-8.