Bański, Piotr. “Why TEI stand-off annotation doesn't quite work: and why you might want to use it
nevertheless.” Presented at Balisage: The Markup Conference 2010, Montréal, Canada, August 3 - 6, 2010. In Proceedings of Balisage: The Markup Conference 2010. Balisage Series on Markup Technologies, vol. 5 (2010). https://doi.org/10.4242/BalisageVol5.Banski01.
Balisage: The Markup Conference 2010 August 3 - 6, 2010
Balisage Paper: Why TEI stand-off annotation doesn't quite work
and why you might want to use it nevertheless
Piotr Bański
Assistant Professor
Institute of English Studies, University of Warsaw
Piotr Bański is an Assistant Professor at the Institute of English Studies, University
of Warsaw, where he
teaches formal linguistics (primarily linguistic morphology and syntax), lexicography,
and the history of
English. He has participated, in the role of the XML architect, in projects building
the IPI PAN corpus of
Polish (encoded in the XCES) and the National Corpus of Polish (a 109-word
resource encoded in multi-level stand-off TEI). He is co-administrator of two TEI-based
multilingual
projects, FreeDict (grouping bilingual dictionaries) and Open-Content Text Corpus
(with multiple monolingual
and aligned parts; currently at the alpha stage).
The present submission focuses on the concept of stand-off annotation as it is implemented
in the current
version of the TEI Guidelines. We look at the motivation for choosing the stand-off
approach to encoding
Language Resources, briefly recount the history of the concept within the broadly
conceived TEI setting (since
TEI P3 and the LT NSL suite, through CES and XCES, ending in TEI P5), review the various
kinds of hyperlink
semantics and identify three kinds of reasons for the poor uptake of the TEI-recommended
stand-off annotation
approach to corpus encoding. We also suggest some solutions that may contribute to
a change in the current
state of affairs.
The present contribution concerns the application of the TEI Guidelines (TEI Consortium, 2010) to the
description of Language Resources (LRs), defined as follows:
A Language Resource is any physical or digital item that is a product of language documentation,
description, or development, or is a tool that specifically supports the creation
and use of such
products (Simons & Bird, 2008).
More specifically, we are looking at linguistic corpora – what Witt et al., 2009a call static text-based LRs. We
furthermore restrict the discussion to text corpora, though we believe that much of
it is true of e.g. speech corpora, or multimodal corpora in general.
We also believe that the general implications of the discussion can be carried over
to other places where linguistics meets markup, or, more generally still, where
two communities with different backgrounds meet to describe an range of phenomena
of interest to both of them.
Among text corpora, we look at those encoded in TEI XML. [1] The aim of the paper is to assess the suitability of the TEI for the purpose of creating
multi-layer
descriptions of linguistic phenomena, but also for more focused applications, such
as those described in Boot, 2009 or Cummings, 2009.
The question we will ask is not whether stand-off annotation in the TEI is doable – the answer to that is clear and successful stand-off TEI systems exist. The question
will
be rather: is stand-off TEI feasible, available out-of-the-box to an XML-literate
OWL (Ordinary Working Linguist) with a crush for the TEI.[2] Here, the answer is unfortunately, it depends, and we shall look at the dependencies.
Some of them are internal to the TEI and hence potentially open to relatively quick
local fixing, some of them
external and affecting the XML world at large. The TEI-internal issues will be shown
to have twofold nature,
technological and sociological, the former easier to solve and conditioning the latter.
In what follows, we first attempt to answer the question of why bother: why stand-off
markup is an attractive
technique from the point of view of a linguist (Section 2). Next, in Section 3, we briefly look at the history of SGML and XML stand-off approaches in the broadly
defined context of the TEI and also at the semantics postulated for the interpretation
of stand-off devices. In
Section 4, we look at the TEI's approach to stand-off annotation, and in Section 5 at the various issues that may condition the insufficient level of uptake of this
approach in the linguistic community. Finally, in Section 6, we sketch some solutions for
the problems identified in the present article. Section 7 concludes the paper.
2. Practical motivation for stand-off representations
This section looks at the motivation for using stand-off representations as seen from
the point of view of an Ordinary Working Linguist. The arguments come
mostly from modularity, both theoretical and practical, but we also look at the issues
of sustainability and interoperability of LRs. We finish by presenting three
different multi-layer TEI stand-off annotation systems as illustration and a point
of reference for further discussion.
2.1. OHCO, overlap, modularity, and the nature of OWLs
One of the claims that gave markup studies a solid push was the thesis that text is
OHCO, an ordered
hierarchy of content objects[3] . The thesis has been shown to be both inaccurate as a general claim and valid as
a statement of
tendencies and pragmatic advantages: while the OHCO thesis does not hold in all cases,
due to the existence of
overlapping hierarchies and non-contiguous objects, it appears to constrain many conceptualizations
of the
nature of text, and OHCO-based approaches to e.g. text editing appear to have practical
advantages. Much of
linguistic modelling is also done assuming OHCO as the general conceptual approach,
accompanied by additional
devices (movement, linking, feature percolation, re-entrancy, etc.) as ways to more
or less system(at)ically plug the holes
that OHCO alone cannot fill.
Criticism of the OHCO thesis has appeared extensively in the literature – see e.g.
Renear et al., 1993 for an early formulation of the problems and reformulations of the thesis, and DeRose, 2004 for an overview of ways in which non-OHCO structures can be represented, also within
the
TEI; the Extreme Markup Languages and Balisage series contain numerous articles devoted
to this issue. Our
purpose here is not to provide new flashy arguments for something that has already
sprung extensive research on
alternatives to XML and on ways to handle the failure of the OHCO thesis by devices
native to XML. Our aim is
practical: we point out that overlap and discontinuity, and the need to embrace rather
than trick them, are
inherent in both theoretical linguistic constructs and in corpus linguistic practice.
We furthermore point out
that the existence of mismatches in description is one of the arguments for a modular
approach to linguistic
modelling, whereby objects with sometimes strikingly different properties are supposed
to constitute separate
domains of study, which are linked by correspondence or mapping rules. This is what
we mean by theoretical
modularity. There is also a more practical aspect of modularity, where it is advisable
to keep the output of
various linguistic tools separated, especially where each of these separate outputs
may constitute the base for
further descriptions in a multi-layer system.
This state of affairs is not only due to the fact that different kinds of linguistic
description require
different and often conflicting segmentations at various levels, some examples of
which we shall look at below.
It is also due to the fact that there is no single way to demarcate the domain of
any component of grammar –
there are a multitude of syntactic, semantic, morphological, phonological, etc. theories
with differing
theoretical apparatus, and sometimes even with differing domains of application, although
they are theories of
seemingly the same phenomena. Consider the virtual non-existence of linguistic morphology
in the days of the
early Generative Grammar (from the late 50's throughout the 60's), when the syntagmatic
aspect of word
composition (ordering of morphs, the "atoms of word forms") was delegated to the syntactic
component, and its
paradigmatic aspect (allomorphy, i.e. modifications in the shape of morphs) was delegated
to the ultra-powerful
phonological component (cf. Anderson, 1992, ch. 2 for a concise discussion and references).
Consider also the lack of interest of Classical Phonemics in morphophonological phenomena[4], which later became part of the focus of Generative Phonology. Similar remarks concern
the division
of labour between and across the semantic and pragmatic components – for those models
that distinguish between
the two – vis-à-vis models based on so-called Cognitive Grammar, which introduce different
divisions. The point
is that there is no single unified approach to morphology, syntax or semantics, etc.,
and any encoding strategy
choosing one particular perspective as privileged is bound to attract criticism and
to discourage researchers
working in different paradigms. We OWLs can sometimes agree that what we want to describe
is stretches of
manifestations of natural language. Sometimes, this is also the limit of our consent,
and anything beyond this,
e.g. our views on the proper segmentation of these stretches, should be presented
as equal variants rather than
one "proper" version with possible "deviations".
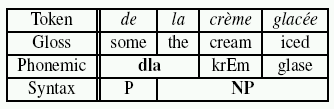
On a plane more familiar to markup specialists, consider an example from Wörner et al., 2006
that concisely presents the nature of the problem with overlapping linguistic hierarchies:
the French
preposition de and article la are pronounced
as a single phonological unit, [dla]. At the same time, the preposition and the article are children of two
different nodes in a syntactic tree:
Figure 1: Overlapping lexical, phonological and syntactic hierarchies (copied from Wörner et al., 2006)
The same is true of other cases involving separate syntactic elements getting merged
morphologically or
prosodically, as in the German in das becoming ins, English gonna , won't or
I'd've, the last of which is a fairly typical example of cliticization
(where a syntactically independent element is prosodically dependent on another; in
this case, both the
contracted 'd and 've cliticize onto the
pronoun I), and of numerous other examples cited in the linguistic literature,
often under the heading of "bracketing paradoxes" or "mismatches" of various sorts.
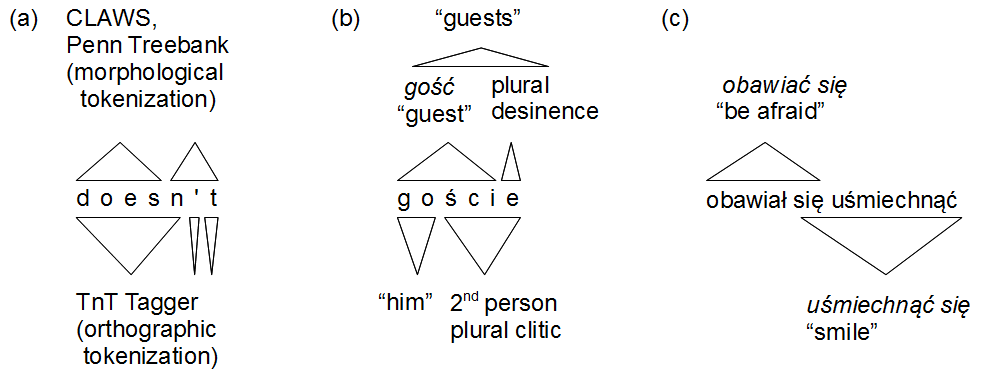
Consider also somewhat different misalignments, for example conflicting POS (part-of-speech)
descriptions.
These may involve changes in the number and the kind of grammatical labels used (e.g.
compare the various
tagsets of the CLAWS tagger), but the differences may
in many cases go deeper and may involve conflicting segmentations: compare the divisions
within
[does][n't] (CLAWS/Penn Treebank) vs. [doesn]['][t] (TnT Tagger), as adduced by Chiarcos et al., 2009.[5] Some relevant cases are illustrated below.
Figure 2: Conflicting tokenizations: morpholexical (of the English doesn't and the Polish
goście) and syntactic (się-haplology in
Polish)
On the left, we present two attested strategies for the tokenization of the English
doesn't (after Chiarcos et al., 2009). In the middle, two possibilities
of the interpretation of the string goście in Polish are shown, whereas
the diagram on the right illustrates overlapping syntactic segments, where obawiał
się means "he was afraid" and się uśmiechnąć means "to
smile"; notice that both strings involve the reflexive marker się,
preposed with respect to the second verb's lemma (= canonical form).
While the first case demonstrates a single function word with multiple possible segmentations
depending on
the given software tool, case (b) shows a single form that realizes distinct "underlying"
sequences: either a
plural noun (consisting of a stem and an ending (desinence) – but this level of detail
is rarely needed) or a
weak pronoun go "him" followed by an auxiliary (person-number) clitic śmy. Case (c) shows two overlapping syntactic words – this is an example of the
haplology of the Polish reflexive marker (see Kupść, 1999). The marker is obligatory for both
verbs used here (the forms *obawiał and *uśmiechnął are ungrammatical without the accompanying się) but
under appropriate circumstances, multiple instances of się may (and in fact
should, in idiomatic Polish) reduce to a single occurrence that is perceived as shared
by the verbs involved.
(As a further complication, these parts of the reflexive verb need not be adjacent.)
Although all of the examples above present various cases of overlap, we do not want
to treat them in the
same way. Cases (b) and (c) belong to the same respective levels of grammatical description
(basic segmentation
in (b), syntactic word identification in (c)) and the contrast between the alternatives
in each case is not
based on any theoretical difference – in the words of Renear et al., 1993, they belong to a single
perspective, and therefore are a counterexample to even the weakest version of OHCO.
At the same time, we do
not want to subject them to any kind of non-OHCO mechanism apart from a simple disjunction
between (sub)trees:
we want a single document to provide us with both variant readings in the case of
(b), and both syntactic words
in the case of (c). Example (a), on the other hand, may be argued to show different
perspectives, as defined
from the point of view of the software tool that is used to tokenize and tag the resulting
strings. In such
cases, we want the different tokenizations to reside in different documents.[6]
Similarly, if the only difference lies in the assignment of POS labels – for example,
the tag for the
comparative degree of an adjective (better, older) in the CLAWS-5 tagset used to tag the British National Corpus, is "AJC", whereas
in the
CLAWS-8 tagset it is "JJR" – then, although expressing the labels in a single document
would be trivial (e.g.
in multi-valued attributes), we want them placed in separate documents, because they
represent different
perspectives or at least different tools. This is completely independent from the
practical issue of validation
of such multi-token attributes and the like – even if the validation were trivial,
these perspectives are
fundamentally different for practical reasons and should be kept separate also with
an eye to using one of them
but not the other for the purpose of building the next annotation layer. [7]
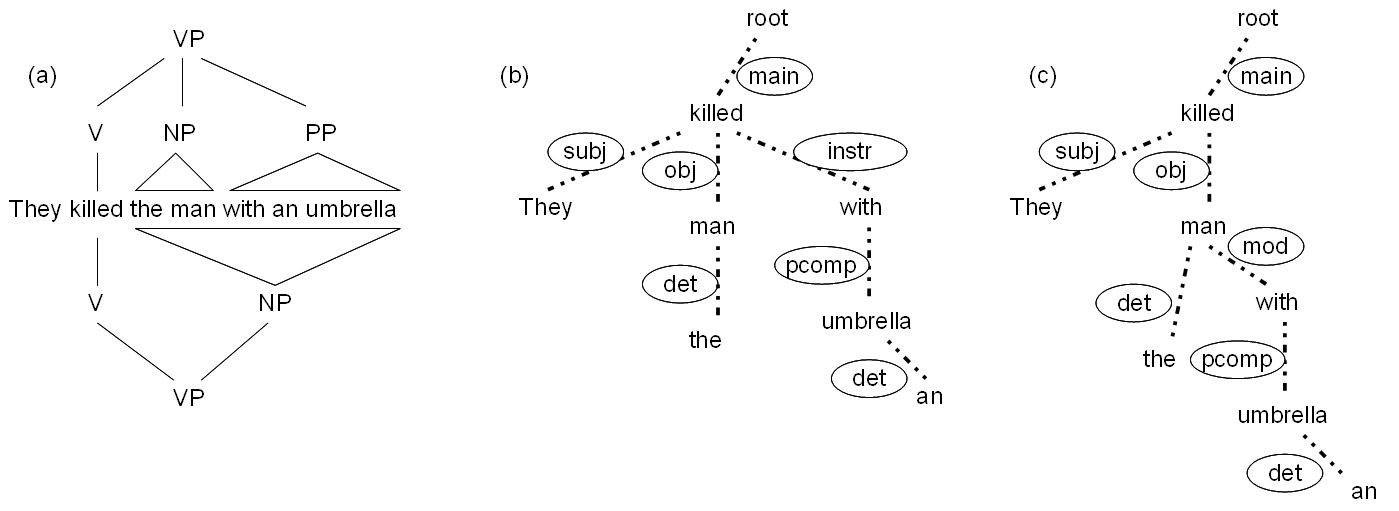
Consider one more example, of the ambiguous sentence they killed the man with an
umbrella. The realistic phrase structure analysis in such cases stops at the level of chunking
(shallow
parsing) – in this case, [they][killed][the man][with the umbrella], with no indication of the structure of
the verb phrase (VP) that starts at kill and continues to the end of the sentence on
either reading. If deep parsing were attempted, the result would be as in (a) below,
where the prepositional phrase
modifies either the verb kill (upper tree) or the noun man (lower tree).
Figure 3: Conflicting phrase structure analyses of a single sentence (a) vs. dependency analyses
(b) and (c)
The prepositional phrase (PP) with an umbrella can be interpreted
either as a separate instrumental adverbial (upper tree in (a)) or as part of the
noun phrase (NP) object (a
modifier of the noun – not indicated separately in the lower tree in (a)). In the
dependency analysis, we
are looking at graphs with labelled edges. The meanings of the labels are as follows:
main introduces the entire structure, subj = subject,
obj = object, instr = instrumental
adverbial, det = determiner (article), pcomp = prepositional complement; diagram (c) shows the modification of the object man necessary to reflect the interpretation whereby the man was carrying an
umbrella (=the lower tree in (a)), mod = modifier.
Examples (b) and (c) represent a dependency analysis of the same sentence (based on
the http://www.connexor.eu/ "machinese" demo),
with (b) corresponding to the interpretation encoded by the top tree in (a), while
(c) reflects the interpretation of the
bottom tree of (a). Dependency analyses involve graphs with labelled edges, which
may – but need not – be isomorphic
with trees, and therefore their OHCO-compliance can at best be partial.
In essence, what is needed for linguistic description is best captured by keeping
the text in as neutral form as
possible, and offering various views of it, depending on the whim or the particular
set of linguistic beliefs of the
given user. One way to achieve this goal is to use stand-off annotation, whereby the
source data is kept separate, either as raw text or with “low density” XML markup
(i.e., with gross structural markup
alone, e.g. identifying headers and paragraphs but little more, in order not to instil
any theoretical linguistic
interpretation into the text), and whereby all the possible linguistic interpretations
are kept in separate documents,
either referencing the source text directly, or forming a hierarchy of annotation
layers (see e.g. Goecke et al., 2010 or Ide & Romary, 2007 for more details).[8]
While some of the cases of overlap and discontinuity presented here are open to reanalysis
in terms other
than stand-off annotation, even in the TEI itself – by means of milestone elements,
fragmentation, in-file
stand-off elements such as <link> and <join> or linking
attributes such as @exclude, @synch and others (cf. DeRose, 2004 and chapters 16 and 20 of the TEI Guidelines),
there is one important factor that rules out such strategies, and that is modularity of description. Descriptions of properties belonging to different theoretical
perspectives are expected to be separate, in order to constitute separate modules
that can be judged, verified
and challenged on their own.[9]
2.2. Issues of sustainability and interoperability
It is one of the tenets of at least some sustainability-oriented encoding practices
that the object of
description (in our case, text) be maximally divorced from its possible theoretical
views (annotations). This
way, the text, kept in as neutral form as possible, remains an attractive resource,
open to future analyses and
to the creation of new views, i.e., new annotation layers (this goes under the heading
of extensibility).
Equally attractive are the annotations themselves – they can serve as the basis for
comparison of tools and theories.
Security (immutability) of the text itself is also essential, and this is what stand-off
approaches strive to
guarantee, because they are non-destructive with respect to the resource that gets
annotated.[10].
Interoperability values the ease of transduction, both in the case of the source text
and with respect to
its annotations. Sometimes, the ease of mapping a single layer of annotation to another
resource (e.g. a
translated document) is also important.
On the other hand, Rehm et al., 2010 point out that stand-off approaches are not optimal from the
point of view of sustainability because they require dedicated tools in order to merge
annotations with the
source text. This is very true of the current state of affairs. Our point is that
if stand-off annotation can be
handled by generic XML tools then the issue of the longevity of the annotation layers
(note that the source text
is relatively safe) piggybacks on the general well-being of XML technology, ages together
with it, and is open to
whatever plastic surgery is applied to make XML or its descendants look good 20 years
from now.
Rehm et al., 2010 point out that the approach they suggest, multiply-annotated text, which also uses layers of annotation but each of these layers contains an
exact copy of the source text, and thus achieves sustainability through redundancy,
has more advantages than
stand-off approaches that keep a single copy of the source text. It is not our aim
to argue against that
theoretical stance because, like the stand-off approach that we concentrate on here,
it assumes modularity of
description, and modularity is what OWLs need. Additionally, in principle, both approaches
can be mixed in e.g.
crowd-sourced corpora where annotation layers are contributed by external parties.
Both approaches also appear
to share one more problem: the lack of generic XML tool support, a matter which we
will return to below.
Summing up, stand-off technology has both advantages and disadvantages from the point
of view of the two
deservedly hot leitmotifs of language documentation and linguistic infrastructure:
sustainability and
interoperability. On the one hand, the advocates of stand-off markup note the relative
stability of source text
with low-density markup (or with no markup at all), as well as the putative flexibility
of the annotation
layers. On the other hand, those who concentrate on the holistic advantages of language
resources note that the
merger of the source with the annotation layers requires dedicated machinery. In the
next section, we look at
three stand-off TEI systems that attempt to cope with these issues in various ways.
2.3. Selected TEI stand-off systems
The present section contains brief descriptions of selected complex systems involving
versions of the TEI stand-off technology. The selection is absolutely
partial and subjective, but, we believe, it serves its purpose nevertheless, exemplifying
three out of many possible variants of stand-off systems.
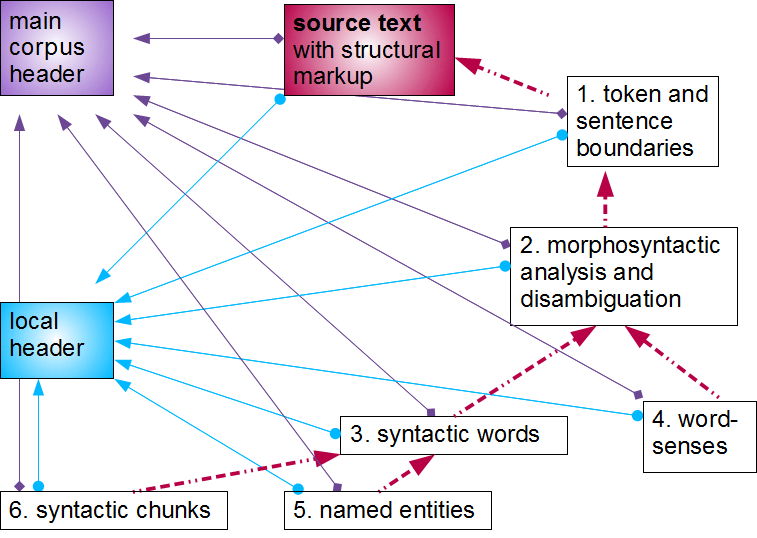
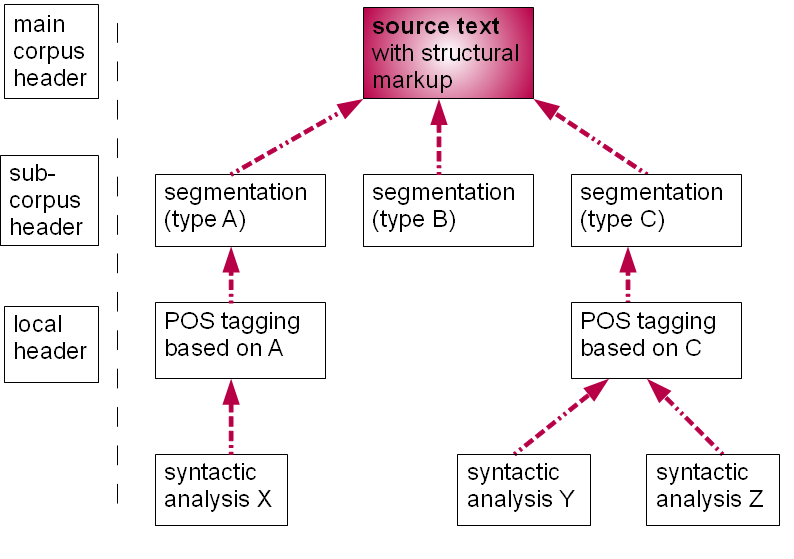
The first resource to be presented is the National Corpus of Polish (NCP), an over-109-segment deliverable of a 3-year
state-funded project ending in late 2010, available for searching at http://nkjp.pl/. We present the structure of a
single corpus text in the diagram below.
Figure 4: National Corpus of Polish (NCP): dependencies in a robust multi-layer stand-off system
Dependencies among the annotation layers in the National Corpus of Polish. Red arrows
( ) denote the dependencies among the various parts of the hierarchy. Blue arrows () and purple arrows () signal the inclusion of the local header and the main corpus header, respectively.
For the sake of readability, these relationships are
not indicated in the diagrams that follow.
In the NCP, the source text has minimal structural inline markup, down to the level
of the paragraph
(<p> or <ab>, the latter standing for "anonymous block" where we don't want
to make a semantic commitment). Sentence boundaries as well as the individual tokens
are identified at the
segmentation layer (1.); this is also where segmental ambiguities such as those discussed
in Figure 2 (b) are indicated. The segmentation layer serves as the basis for the layer
that, firstly, identifies all the morphological interpretations of the given segment,
and secondly, attempts to
disambiguate them in the morphosyntactic context (2.); this layer is referenced by
the next two: (3.) the layer
of syntactic words (grouping e.g. analytic tense realizations but also elements such
as obawiać się and uśmiechnąć się, cf. Figure 2 (c)) and (4.) the layer of word-sense disambiguation (experimental, for 100
selected lexemes with multiple interpretations). The layer of syntactic words is the
basis for the final two
layers: the layer of named-entity recognition (5.)[11] and the layer of shallow parsing, identifying syntactic chunks (6.). All NCP documents,
source text
and annotations alike, include two kinds of headers: the local header that describes
the properties of the
source text and contains a changelog for all the modifications and additions that
affect the given directory,
and the single corpus header, which contains information shared by all parts of the
corpus, including
definitions of various taxonomies, which are referenced from the local headers. An
early version of TEI ODD
"literate encoding" documents describing some of these schemas has been made available
at http://nlp.ipipan.waw.pl/TEI4NKJP/. See Bański & Przepiórkowski, 2010 for more description and references to more detailed papers on each of the
annotation layers.
The two resources that follow took the overall model of the NCP as their starting
point, and tailored it to
their specific purposes and the context in which they are deployed. The first of them
is the Open-Content Text
Corpus. This is a resource meant to be both the open-source testing ground for TEI
stand-off applications and
at the same time, to constitute a common platform for collective research and academic
work on preserving and
describing language resources, especially those for "lower-density languages". While
we leave the details aside
(see Bański & Wójtowicz, 2010), we note that the multilingual nature of the corpus (at the time of
writing, it contains mini-subcorpora for 55 languages) forces the introduction of
one more layer of
organization, with its own header. Thus, each text of the OCTC includes three headers,
the links to which have
been mercifully omitted from the diagram below. Because the corpus is meant as a platform
for many possible
research or student teams, it is explicitly modelled as a multi-instance
stand-off structure, which means that it is expected that a single annotation layer
of the OCTC may come in
many variants, depending on the tools used to create it. This is indicated below.
Figure 5: Open-Content Text Corpus (OCTC): dependencies in a multi-instance stand-off system
Dependencies among the annotation layers in the Open-Content Text Corpus. Red arrows
(
) denote the dependencies among the various parts of the hierarchy.
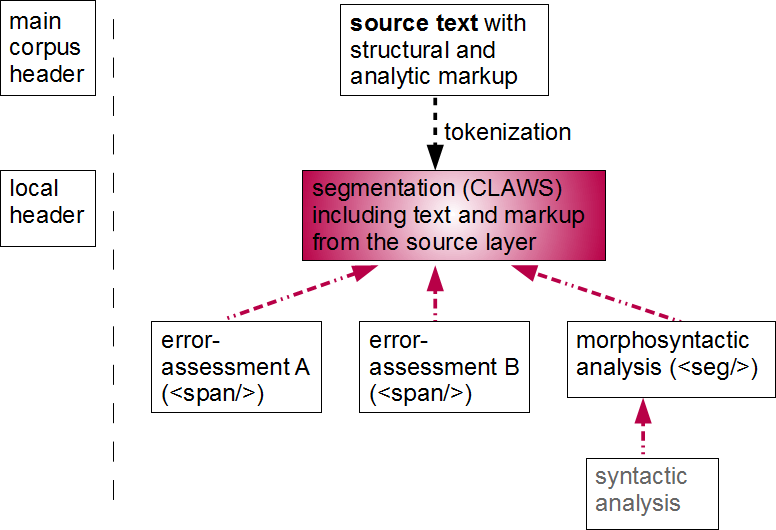
The final example presents the prototype structure of the English subcorpus of the
FLEC (Foreign Language
Examination Corpus), a learner corpus containing examination essays by students of
the University of Warsaw.
Its primary aims are to study the transfer of linguistic structures of Polish onto
the second language and to
measure the inter-rater agreement in order to attain greater objectivity in grading
language exams (see Bański & Gozdawa-Gołębiowski, 2010 for details). The electronic source texts are produced by transcribers (the exams
are
written in hand), who fill out templates already divided into sentence-sized chunks,
and introduce extra markup
for unclear passages, special textual features, gaps and the like. The source text
is then tokenized according
to an agreed tokenization standard (by default, according to whitespace and punctuation,
but the English part
additionally obeys the CLAWS tokenization rules), and each token is indexed. This
becomes the new base that
other annotation layers reference, and in effect, the original source text remains
only as a backup. This
system is close to what Cummings, 2009 describes; to distinguish it from systems in which the
source text receives only light tagging (or no tagging at all, as in the American National Corpus), we use the term
"rich-base stand-off system" to refer to it.
Figure 6: Foreign-Language Examination Corpus (FLEC): dependencies in a rich-base stand-off
system
Dependencies among the annotation layers in the Foreign-Language Examination Corpus.
Red arrows ( ) denote the dependencies among the various parts of the hierarchy. The black arrow
indicates that the segmentation layer takes over all the functions and the content
of the source layer,
which is retained only for archival purposes but does not participate in further processing
of the
corpus.
Each essay is rated by at least two instructors, on special forms that make it possible
to transcribe the ratings into electronic form. The morphosyntactic
layer is added separately, to make it possible to perform searches. In the future,
a syntactic level is planned, that will allow for searches based on syntactic
criteria for, e.g., specific constructions.
Here is where modularity is required and enforced by practical considerations: the
individual parts of the
corpus are scheduled to be created at different points in time, as dictated by the
availability of the new
data, the ability of the transcriber team to cope with the hand-written exams, then
to cope with the raters'
judgements, while the morphosyntactic descriptions are created.
2.4. Motivation for stand-off representation: summary
This section looked at the motivation for the use of stand-off annotation in linguistic
applications. We
first looked at the application of the OHCO thesis to linguistic theorizing and found
that there was no
straightforward relationship between cases where OHCO failed and the preferred encoding
strategy. The choice
appears to depend on the particular perspective (hinted at rather than defined here
with reference to
linguistics): whether OHCO-conforming or not, perspectives that reflect the modular
nature of the grammar, or
that are due to practical issues such as the choice of the particular tagging tool
or tagging system, call for
dedicated annotation documents. In systems such as the FLEC, the practical issues
reach even further and depend
on the human annotators of each kind of documents (the essays are planned to be always
transcribed as soon as
possible, to provide raw material for studies of the lexical content).
Let us reiterate: many of the above issues could be encoded within single files, thanks
to the ingenuity of
the many designs allowing for non-OHCO representations. But we OWLs are not even going
to try them: we want our
encoding layers separated, for reasons both theoretical (they encode different pieces
of our descriptions and we
want to keep it that way) and practical (we want relatively generic systems that "just
work" without requiring
dedicated tools; if they require too much hassle, we'll just grab a different, existing
solution, and not
necessarily one based on XML).
3. Stand-off annotation: the semantics of hyperlinks
To our knowledge, the earliest mentions of stand-off annotation, at least in the broad
context of the TEI,
were made in papers co-authored by Henry Thompson and David McKelvie, with the participation
of Amy Isard and
Chris Brew (Thompson & McKelvie, 1997, McKelvie et al., 1998, Isard et al., 1998). They were mostly made in the context of the LT NSL package (later to become LT
XML), created at the
University of Edinburgh. In these papers, the foundations for stand-off semantics
were laid. Below, we look at
some of the possible interpretations of stand-off links, the first four defined by
the LT NSL group. Much of that
has later surfaced in the XInclude and XLink specifications (the latter partially
based on TEI pointing
techniques).
We can distinguish at least the following kinds of possible interpretations of linking
attributes and elements:
Inclusion semantics of hyperlinks as originally presented in Thompson & McKelvie, 1997,
with a simplified notation of the @target attributes. The proposals were unclear about
the target
metadata (in red) and either involved the loss of it (Thompson & McKelvie, 1997, McKelvie et al., 1998) or preserved it (Isard et al., 1998); the latter option is
shown in the figure above.
replacement (later turning into XML Inclusions; involving the loss of
the pointer metadata),
Figure 8: Replacement semantics
Replacement semantics of hyperlinks as presented in McKelvie et al., 1998 and Isard et al., 1998. This is the straightforward ancestor of XInclude semantics.
inverse replacement ("include everything but the element that I point
at, and use me instead of it"); this raises the question of feasibility of implementation
if more than one
such replacement is performed in a single document;
multiple-point linking (in the future, it became the semantics of the
TEI's <link>, specialized into <join> ). See also Listing 4 below.
correspondence semantics, the most underspecified semantic
relationship possible (not mentioned in the LT NSL system but logically necessary
and somewhat akin to
multiple-point linking); correspondence semantics may be enough for visualising applications
– i.e., there
is no need to derive an extra TEI representation: all that the application has to
know is which fragments
of one layer correspond to which fragments of another, and that is enough to act on
them. Correspondence
semantics in also necessary in the case of multimodal corpora, where annotation layers
(in)directly address
binary streams. In the TEI, there exist a variety of devices for simple pointing,
from the @target
attribute (and the deprecated @targets), sometimes embedded in the <ptr> or
<ref> elements, through the entire range of pointers with added shades of interpretation
beyond pointing or linking, such as @corresp, @ref or @ana, among many others (see
http://www.tei-c.org/release/doc/tei-p5-doc/en/html/REF-ATTS.html for a complete list of TEI
attributes). Note also that the simplest version of multiple-point linking semantics
involves this kind of
pointing, but at more than one resource at the same time.
merger semantics, possible under limited circumstances, "merge my
attributes/content with the attributes/content of the element I am pointing at" –
this is a viable
possibility for e.g. a morphosyntactic layer composed out of <seg> elements containing
feature structures and pointing to a segmentation layer composed of empty <seg>
elements, whose only role is to address character spans in the source text. A variation
of this scenario
with more content is illustrated below.
Figure 9: Merger semantics
Merger semantics, possible if the relevant schemas are non-conflicting (in the extreme
case, if
both annotation documents are instances of the same schema that also allows the occurrence
of both
kinds of element content together). The effect is that of unification of descriptions.
reverse inclusion semantics – literal interpretation of the semantics
of CES links (see below); untenable for at least practical reasons, though we stress
that it has been used
mostly in the context of virtual representations, and with such a proviso, reverse
inclusion semantics may
even be argued to be useful for descriptions of binary streams, which get virtually "adorned" with the annotation information.
Figure 10: Reverse inclusion (virtual)
This type of inclusion can be called, in the context of the system presented here,
"reverse
inclusion". It represents the literal reading of the most popular characterisation
of stand-off markup
in the Corpus Encoding Standard documentation. The result is a virtual structure that
in fact had to be
realised as either straight inclusion or replacement, or else correspondence semantics.
The last kind of semantics is inspired by the prose descriptions of the Corpus Encoding
Standard (http://www.cs.vassar.edu/CES/), an SGML-based specialization
of the TEI-P3 (cf. Ide & Véronis, 1993, Ide, 1998) and its later XML version, XCES (http://www.cs.vassar.edu/XCES, cf. Ide et al., 2000). This standard was an important way to offer OWLs a handy TEI-like tool for quick
deployment and proved very
popular in corpus-linguistic circles. One of its most important features was that
it severely narrowed down the
sometimes enormous range of options offered by the unconstrained TEI – this task had
already been performed for
the OWL, who only needed to choose from among the optional elements and attributes,
but crucially, not so much
from equivalent ways to annotate texts. Other important features of the XCES
were:
focus on the implementation of stand-off methodology,
three different content models for the three different layers (source text, analysis
(morphosyntax and
chunks), alignment),
re-entrant cesCorpus (supporting the structural encoding of subcorpora),
specific recommendations for morphosyntactic and alignment markup.
(X)CES hyperlink semantics was always stated in free prose and typically mentioned
“annotations virtually
added to the base document” – treated literally, it would result in something like
the “reverse inclusion”
mentioned above. However, while it is natural to be able to predict and shape the
behaviour and composition of
the document under the control of the annotator, i.e. the annotation document, it
is not necessarily so with
respect to the source. This means that at best, we can expect inclusion or replacement
semantics here, although
what was often meant in the XCES, we believe, might have been simply correspondence
semantics, with redundant
text fragments copied from the source text layer, somewhat in the manner of multiply-annotated
text of e.g. Goecke et al., 2010, but with no guarantee of exhaustivity of description.
In the listing below, we illustrate some of the above-mentioned concepts of hyperlink
semantics with
fragments of existing text resources, the National Corpus of Polish (Listing 1) and the
Open-Content Text Corpus. The NCP uses correspondence semantics; it is worth pointing
out that the word abyś is split into the sentential conjunction aby "in
order to" and the person-number clitic ś, which is marked as orthographically
adjoined to its host (text tokens are listed in comments above the corresponding <seg>
elements).
In the OCTC listings below, we first look at a segmentation file that uses mixed semantics:
correspondence
semantics for the containing element, <ab> ("anonymous block"), and replacement semantics
realised by the XInclude directive using the W3C-defined xpointer() scheme.[12]
The result of resolving XInclude directives – the first segments of the Universal
Declaration of Human
Rights in Swahili – is provided in Listing 3 below.
The final listing illustrates one possible take at the multiple-point semantics –
a fragment of a document
aligning the Polish and the Swahili versions of the Universal Declaration. It does
not use the
<link> element, usually suggested for this purpose, but rather separate <ptr>
elements, for greater granularity (in some cases, many:many relationships between
fragments of text must be
expressed and using <link> elements with multi-valued @target attributes would be
rather tedious).
In conclusion, it is also advisable to mention the concept of radical stand-off that the XCES
evolved into, in the context of the American National Corpus, which keeps the source
files in the form of raw
UTF-16 text and uses dedicated software (ANCTool) to merge the raw text with the annotations
selected by the
user, cf. Ide & Suderman, 2006. Our interpretation of the the XCES evolving in the context of the ANC
and ending up merely as one of the output formats of the ANCTool is that the creators
of the ANC have drawn
conclusions from the stalled development of the W3C XPointer standard, various versions
of which the XCES
attempted to use over the years, and finally gave up on it and switched to an in-house
tool that made it possible
for them to go all the way towards radical stand-off annotation, which undoubtedly
has some advantages from the
point of view of sustainability of LRs (the texts are kept as read-only, so there
is no danger of corrupting them
by fixes and adaptations of markup).[13]
4. Stand-off markup in the TEI
We begin by distinguishing two uses of stand-off devices and then concentrate on what
features of the XCES can be found implemented in TEI P5.
4.1. local stand-off
Recall that one of the purposes of stand-off annotation is to make it possible to
handle
overlapping hierarchies and any other sort of conflicting markup. The TEI has several
devices for this purpose, mentioned in chapter 20
of the Guidelines. The prototypical example is <join>, aggregating
elements that it points to into a virtual object. Other members of the family include
<alt>, <span>, and the least semantics-laden
<link>. [14]
Due to the fact that pointers in TEI P5 are URI-based, these elements may be used
as
both "local stand-off" and "remote stand-off" elements (where the former is not an
oxymoron
and the latter not a tautology): if the metaphor for “stand-off” is paraphrased as
“creating/organizing a structure in resource A out of elements of resource B by pointing
to
them”, then in the cases where the pointing is local, A and B are the same resource.
The
remaining discussion in this section does not refer to such uses, but we return to
them in
Section 6. In the remainder of this section, we look at the kind of
stand-off annotation that involves pointing across separate documents.
4.2. The converging paths of the XCES and TEI P5
TEI P4 was an
XML-ised version of P3, with minimal changes, and only the introduction of TEI P5 saw drastic modifications
in the recommendations for linking. To an outside observer, this may be described
as the TEI's reabsorption of the modifications introduced
by the CES as the latter forked from TEI P3. Apart from important low-level modifications
of
elements designed to annotate linguistic structure, the important changes were the
introduction of a self-nesting <teiCorpus> element (it did not self-nest
in P4; this is a feature crucial in resources such as the above-mentioned NCP or OCTC;
see
also Section 2.3) and the generalization of the concept of stand-off markup, made possible by the
switch from IDREF-based pointing to the current URI-based version.[15]
It is worth highlighting an ingenious move in the introduction of stand-off annotation
in the TEI, namely the use of the XInclude standard
(http://www.w3.org/TR/xinclude/).
The initial version of the XCES (cf. Ide et al., 2000) used XLink (then
http://www.w3.org/TR/xlink/, currently
http://www.w3.org/TR/xlink11/) as the pointing device, with XPointer
xpointer() schemas (back then, the schema was called xptr()) as
the content of xlink:href. The XPointer xpointer() draft
(http://www.w3.org/TR/xptr-xpointer/) was being born right at that moment and
nothing forewarned of its remaining at the draft stage for ever, or at least until
now.
The XLink recommendation was also fresh and promising to see much heavier use than
it does
today, remaining endemic to only a few specifications. See Ide, 2000 to glimpse at the optimism that the introduction of new W3C standards brought into
the LR community.
TEI P5 documents concerning the use of stand-off annotation
(http://www.tei-c.org/Activities/Workgroups/SO/) date from 2003 at the
earliest, and at that time, the XInclude recommendation was at least at the Working
Draft
stage and promising to become at least useful. XInclude explicitly uses replacement
semantics (not inclusion semantics, despite the similarity in names) as defined by
Thompson & McKelvie, 1997 (see Section 3), and that must have appeared
the perfect solution, the more so that it allowed the TEI to delegate some of the
intended
functionality to an independent W3C standard, promising to get wide support in XML
parsers.[16] Additionally, TEI P5 stand-off implementation was designed with the use of
TEI-defined XPointer schemes in mind, which was another brilliant move because nothing
(except perhaps for xpointer()'s prolonged draft status, but one should always
hope) signalled that these schemes will remain as unimplemented by parsers today as
they were at the
time of their registration.[17]
5. Problems with implementing TEI stand-off annotation
Stand-off annotation, with all its advantages for language description and documentation,
typically requires
a dedicated tool to implement the hyperlink semantics, compare e.g. LTXML2
(http://www.ltg.ed.ac.uk/software/ltxml2), ANNIS
(http://www.sfb632.uni-potsdam.de/d1/annis/), ANCTool
(http://www.americannationalcorpus.org/tools/anctool.html) or applications using MonetDB
(http://monetdb.cwi.nl/). In this context, let us repeat that using XInclude accompanied by a set
of XPointer schemes was an ingenious move, because in theory, it should allow an OWL
to be able to use TEI
stand-off with ordinary off-the-shelf tools. In this section, we look at the various
factors that conspire to
what we believe is the undeserved lack of uptake of TEI stand-off devices. We divide
these factors into external
and internal, and among the latter, we make a distinction between technological and
sociological.
5.1. Technical issues external to the TEI
In this section, much depends on the reader being able to make the distinction between
(i)
@xpointer as the name of an XInclude attribute that can sometimes contain just a shorthand
pointer (an NCname), (ii) XPointer as referring to the entire XPointer Framework,
and (iii)
xpointer() as referring to one of the XPointer schemes – that is why the sentence
“@xpointer can hold XPointer's xpointer()” is meaningful, and true. Unsurprisingly,
these terms are notoriously confused on various occasions. Similar remarks concern
string-range()
as the name of one of the xpointer() scheme's functions, defined
by the W3C draft, and string-range() as the name of a TEI-defined XPointer scheme, on a par with xpointer(), element(), and other third-party
schemes registered with the W3C. Some of these issues are addressed in a TEI Wiki
article at http://wiki.tei-c.org/index.php/XPointer.
As has been mentioned above, the TEI recommendations for stand-off annotation rely
on
the use of external standards, most importantly XInclude and the XPointer Framework,
with
its potential for defining third-party XPointer schemes. To cut a long story short:
tool
support for W3C XPointer schemes other than element() (obligatory for XInclude) and
xmlns() does not exist, as far as the popular XML parsers are
concerned, and support for third-party schemes is scant.
It might be claimed that these issues are internal to the TEI, after all, because
they
depend on the TEI's internal choice to use XInclude and to use its own XPointer schemes
for pointing
into the text. However, there appears to be no alternative to the use of XPointer
schemes
for pointing into spans of characters (short of unwinding history back to the era
of TEI
extended pointers whence XPointer comes), and in this sense, the lack of support for
XPointer's xpointer() scheme blocks the possible development of support for the TEI-defined
schemes, because that support should ideally piggyback (in terms of data structures,
basic
mechanisms, etc.), on the support for the W3C-defined xpointer().[18]
It has to be noted that there exists a single widely accessible implementation of
XInclude that goes beyond
the minimum prescribed by the W3C Recommendation: libxml2 (http://xmlsoft.org/) with the xmllint parser that supports limited
xpointer() functionality, although unfortunately in a buggy way, so that while it can be tasted
and
demonstrated, it cannot be employed full-scale.[19]
The lack of tool support made the developers of the National Corpus of Polish resign
from using
XInclude-based stand-off in favour of the underspecified semantics of the @corresp attribute that
simply states correspondence between two elements (or an element and a span of characters),
cf. Listing 1. Since this has to be handled by dedicated project tools anyway, it is enough for
these tools to read information from @corresp rather than mimic the behaviour of an XInclude
processor. This shows the inaccessibility of TEI stand-off to users without technical
background or technical
support – it does not work out-of-the-box despite the measures that the Guidelines
took to ensure that the
technique is lucidly described. The OCTC attempts to use W3C-defined xpointer() scheme as much as
possible (cf. Listing 2) in order to be able to fall back from W3C technology to
TEI schemes when the latter are finally implemented.
Cayless & Soroka, 2010 point out the possibility of TEI pointers to point outside of their
"lawful" domains and out across the whitespace, ignorable or not. This issue is real
and actually seen in
practice, in the xmllint bugs reported by the present author. Cayless and Soroka's
observations should be
treated as imposing specific constraints on stand-off pointers, whose ranges, must be located inside the elements identified by each individual pointer; this is trivial
in the
case of the lower value of the offset (which should not go below 1 in the case of
the W3C pointers or below 0
in the case of TEI-defined pointer schemes) but becomes less than trivial when it
comes to ensure that the
maximal value of the pointer does not extend beyond the addressed string.
5.2. TEI-internal technical issues
We argue here that, despite properly seizing the opportunity for a free ride with W3C
specifications, some aspects of the putative reabsorption of XCES innovations into
the TEI were not fully
addressed.
The TEI diverges from its path of reabsorbing the XCES in that it packages all
information, be it the source text or its annotations, into a single
teiCorpus/TEI/text format. (Recall that the XCES used three different DTDs
for the source text, the morphosyntactic analysis, and the alignment documents; they
were
different up to the root element.) This is inadequate for two reasons:
it strains the semantics of the <text> element (annotations do
not contain text, or at least do not have to contain it to be useful),
it packages technical annotation documents into the format expected of source text
documents, which means that rather than putting a sequence of e.g. <seg> ("segment") elements with morphosyntactic information in
feature structures straight into text/body (which is not ideal, as pointed out above,
but for many would probably suffice), the developer has to trace the TEI content model
and use e.g. the <ab> ("anonymous block") element as a wrapper for
<seg>s only for the purpose of satisfying the content model
designed for texts; similarly, it is impossible to keep a sequence of <linkGrp> or <spanGrp> elements in text/body – one has
to use at least an empty dummy <div> for the document to validate. This
feels like a kludge and the developer is tempted at this point to leave the TEI for
the XCES or PAULA.
Note that one way out would be to redefine the content model inside
<text> – after all, the TEI offers the mechanism of ODD for this
purpose (cf. Burnard & Rahtz, 2004). However, that would still mean that
annotations are kept under <text>,
special effort must be put into designing the ODD beyond a mere selection of
the appropriate modules and elements, and
the resulting document is not TEI-conformant, because it changes the content model
of
<text> (cf. chapter 23.3 of the
Guidelines). That in itself is no tragedy, but recall that we want to cater, among others,
to OWLs (ordinary working linguists), also with a view to the issues raised in the
following
section. An OWL would often look for an out-of-the-box solution that the XCES promised
(although
only for morphosyntactic annotation). Furthermore, breaking TEI-conformance may mean
that whatever
tools there exist for handling the TEI may refuse to handle the non-conformant documents.
Again, we
are thinking of an OWL who wants it to "just work", and we bear in mind that the recourse
to using
W3C standards was exactly a step towards ensuring that things "just work". Having
an OWL design
their own ODD in order to store stand-off annotations does not contribute to that
goal.
The users are aware of some of this, cf. a recent TEI-L (http://listserv.brown.edu/archives/cgi-bin/wa?A0=TEI-L) discussion thread (e.g. Martin Holmes's message of Sat, 20 Mar 2010 06:38:00 -0700) on where to keep
<linkGrp> and similar elements: no consensus has been reached: there are users who keep it
in text/body, text/back, or who would rather keep this in the header (because they
feel it is a different kind of data), or, finally, “somewhere else” and we will see
presently what this
suggestion is.
5.3. Social and sociological issues
Standards are good only insofar they meet the expectations of, and get a chance of
getting feedback from,
the community that they are targeted at. However, corpus linguists or corpus producers
appear to be
underrepresented in the TEI community. TEI-L, an otherwise helpful mailing list with
a very high
signal-to-noise ratio, falls largely silent when corpus-design-related questions are
asked, in comparison to
e.g. questions regarding the encoding of manuscripts, literary works, or bibliographies.
Instead of concluding
that TEI-ers with a corpus-design twist are the most unfriendly of TEI-ers, one should
rather conclude that
there are few such TEI-ers around, and ask why, and whether the XCES has taken them
all away.
A corpus linguist, if s/he is going to choose XML (rather than plain text or a RDBMS)
as
the format of choice, may easily choose the XCES – dated but simple and sufficient
for
lightly-analysed corpora, or PAULA (Dipper, 2005) – not so simple but with an
array of technical backup and a bunch of smart people popularizing it, or finally
a more
dedicated format such as that of the ANC (“extreme stand-off”, cf. Ide & Suderman, 2006), a testbed for the nascent ISO Linguistic Annotation
Framework (Ide & Romary, 2007) and more specifically, for the abstract pivot
format, GrAF (Ide & Suderman, 2007).
The question is whether the TEI has a chance to become an alternative to these systems
for an OWL. Incidentally, when searching the Net for a reference to the origin of
the
interpretation of “OWL” used here, I came across a similar point made by Farrar & Moran, 2008:
“[...] any new approach or technology requires critical mass. If too few in a
community use the technology, then it will usually fail. TEI recommendations (using
SGML)
never caught on with the ordinary working linguist, likely due to the unavailability
of
tools to produce it. The situation with recent best-practice XML recommendations has
been
only slightly better.”
One of the points we want to make in this contribution is that the TEI still has to
win
some of the corpus linguistic audience in order to kickstart the development-feedback
cycle
for stand-off corpus encoding. It needs to make a move towards a corpus-oriented OWL,
possibly by addressing the issues raised here and by a pressure towards the implementation
of a widely-accessible generic tool that supports stand-off architecture. That would
be the
next of the numerous services to the linguistic and XML community that the TEI has
done over
the years.
6. A sketch of solutions
The TEI is a very good choice for complex corpus encoding with a view to sustainability
and interoperability because, apart from its other virtues, it offers a homogeneous format for encoding all the annotations and storing “formal
metadata” in the TEI headers – this point is made in Bański & Przepiórkowski, 2010, and
illustrated in Przepiórkowski & Bański, 2010. However, at present, stand-off TEI deployment
for such purposes requires dedicated visualisation and query tools acting on the
correspondence semantics of hyperlinks (because XInclusions fail due to the lack of
support for third-party
XPointer schemes anyway), as well as some dedication to simplify parts of the architecture
that are unduly complex for someone who wants to “just do it”, just create a stand-off
annotation document without having to create a mock text document in the process.
Some of the necessary pieces of the puzzle are already there. Recall that the (X)CES
used
three different content models for annotating the source text, the annotations, and
the
alignment. We do not want to argue for that – that would not be as homogeneous a format
as
what the TEI offers currently. Instead, we would like to point out that it is possible
to
reabsorb the (X)CES inventions more fully into the current TEI model, by keeping text
under
<text>, and non-text elsewhere. Let us have a look at the content model
of the <TEI> element:
element TEI
{
att.global.attributes,
attribute version { xsd:decimal }?,
( teiHeader, ( ( model.resourceLike+, text? ) | text ) )
}
model.resourceLike contains <facsimile> (for digital facsimiles) and
<fsdDecl> (for feature system declarations).
Another element that is planned to be included in this model, defined by a planned
new chapter of the Guidelines
devoted to genetic editions, is <document> (the physical object, the manuscript or
other primary source, comprising one or more written surfaces, see http://www.tei-c.org/SIG/Manuscripts/genetic.html). Another addition, suggested by Boot, 2009, is <dataSection> (to store, e.g., <linkGrp> elements
that just do not fit under <text>). In two e-mails to the TEI-L (on 21 Mar 2010 and on 22 Mar 2010), the present author has suggested the introduction of <standOff> for
the same purpose. What this shows it that a need for an extra sibling of <text> is recognized
in the community, and, in the case of <document>, it is actually being implemented.
Implementing an element that could store stand-off markup would be the final, and
in our view necessary, step in
reabsorbing the XCES innovations into the TEI. It would simplify the content model
for the annotation creators,
making it possible for them not to abuse the semantics of <text>, and at the same time not to
be bound by the requirements of <text>'s content model.
We sketch the possible configurations resulting from implementing this solution using
<standOff> because the name of this element corresponds with the topic of the present
contribution. We note, however, that the name "standOff" is only used for the same
of discussion and that e.g.
Peter Boot's suggestion for the name of the element in question, namely <dataSection> sounds
just as good, although perhaps too generic (everything here is data).
Recall that the TEI contains a range of elements with uses that we have referred to
in
Section 4.1by the mildly fortunate term "local stand-off". They are elements
that may sometimes be perfectly justified inside <text>, but there have
been suggestions to move them into the teiHeader or (as in Boot, 2009) to move
them to a sibling of <text>. We suggest that two of these solutions can be
used, depending on the annotating task at hand (we reject the option of locating these
elements in the header). Those who would rather separate the "local stand-off" elements
from
text proper, could use three child elements of <TEI> at the same time:
{ teiHeader, standOff, text }. The third group, the creators of the "classical"
stand-off annotation levels, would use { teiHeader, text } for text documents but
{ teiHeader, standOff} for annotations. This is not the place to suggest the
content model of the putative <standOff> element – suffice it to say that
we would expect it to hold, among others, elements from the "analysis" and "linking"
parts of
the TEI module inventory.[20]
It is also worth mentioning that, for the purpose of establishing character offsets
in
XPointer schemes, the W3C proposals point to character segments and use "1" as the
initial
offset, the TEI and LAF proposals look at inter-character points and use "0" as the
initial
offset. We consider this an unfortunate difference as it is not user-friendly and
the cost of
adapting to W3C model, while the TEI schemes are not implemented yet, should be minimal.
Lastly, community pressure (or simply funding) is needed to implement XPointer extensions
in a generic XML tool (the best candidate being libxml2 by
Daniel Veillard, with the xmllint parser, because it already has some of this functionality
that no other popular and freely available parser has), so that the ingenious TEI
stand-off
system based on XML Inclusions can do something more than merely look nice.[21]
Our claim is that it should be possible for a corpus-oriented OWL with the basic TEI
awareness to read
portions of chapter 15 on
language corpora and chapter
16 on stand-off linking and chapter 17 on analytical
mechanisms in order to be able to construct a simple working stand-off-annotated corpus
prototype that they will
be able to visualise and perhaps even to query. Ideally, even that step should be
simplified and expressed as a
single chapter-like set of recommendations (possibly in the form a TEI ODD file) targeted
specifically at corpus linguists.[22]
7. Conclusion
The motivation for the present analysis was to flesh out certain inadequacies of the
TEI approach to
stand-off annotation, in order to see how many of the problems have causes internal
to the TEI Guidelines, and
how many can be attributed to external factors, such as the lack of sufficiently developed
generic XML tools or
the inadequacies of standards assumed by the TEI. The ultimate question, therefore,
is: should the TEI be used
for modern stand-off text encoding at all, or should developers turn to other formats,
such as the excellent
PAULA toolkit (cf. Dipper, 2005), the slightly aged XCES (Ide et al., 2000) or the more
generic but still incomplete LAF family of standards (Ide & Romary, 2007).
If the TEI wants to become a viable alternative to other formats, it should ensure
that an OWL can easily
implement and use a prototype stand-off corpus. This is conditioned by two factors:
one internal (making content
models of stand-off documents maximally friendly and packaging them for out-of-the-box
deployment) and one
external (the lack of generic parsing tools that would implement XInclude with third-party
XPointers schemes,
ideally as modules). Both issues are solvable. Both would normally be solved by community
pressure but the
community (sub-community of NLP-oriented TEI users) has yet to be formed and in its
absence, it is the rest that
should act, for the sake of making the TEI community richer and more dynamic, and
in this way, to supply all of
us with new ideas and research topics, and new tools (including better support for
stand-off document creation,
visualisation and querying) to go with them, because tools follow users. We have identified
three classes of
problems, all tied together. In order to move on, the tie should be cut, preferably
at a few places at the same
time.
Wittern et al., 2009 mention that a separate chapter concerning corpus
annotation has been considered for inclusion in the Guidelines but never ended up
finished and included. We
believe to have shown here that that chapter, after considerable revisions, might
be one of the ways in which the
TEI reaches out to OWLs interested in corpora, whether of the purely textual or the
multimodal kind. The nascent
Special Interest Group for linguists (http://wiki.tei-c.org/index.php/TEI_for_linguists) is another
step towards that goal.
Acknowledgements
I wish to thank the six anonymous Balisage reviewers for their encouraging and helpful
comments. It was not
possible to implement all of the suggestions in a single article, but I did my best.
The responsibility for the
remaining errors naturally remains my own.
I would like to express my gratitude to B. Tommie Usdin for her enormous patience
and support, without which
I would not be able to complete this article in time for publication.
References
[Anderson, 1992] Anderson, S. (1992). A-Morphous
Morphology. Cambridge Studies in Linguistics (No. 62). CUP.
[Bański & Gozdawa-Gołębiowski, 2010] Bański, P.,
Gozdawa-Gołębiowski, R. (2010). Foreign Language Examination Corpus for L2-Learning
Studies. In Rapp, R.,
Zweigenbaum, P., Sharoff, S. (Eds.) Proceedings of the 3rd Workshop on Building and
Using Comparable Corpora
(BUCC), Applications of Parallel and Comparable Corpora in Natural Language Engineering and
the
Humanities, 22 May 2010, Valletta, Malta, pp. 56–64. Available from http://www.lrec-conf.org/proceedings/lrec2010/workshops/W12.pdf.
[Bański & Przepiórkowski, 2009] Bański, P., Przepiórkowski, A.
(2009). Stand-off TEI annotation: the case of the National Corpus of Polish. In Ide,
N., Meyers, A. (Eds.)
Proceedings of the Third Linguistic Annotation Workshop (LAW III) at
ACL-IJCNLP 2009, Singapore, pp. 64-67.
[Bański & Przepiórkowski, 2010] Bański, P., Przepiórkowski, A.
(2010). The TEI and the NCP: the model and its application. In Arranz, V., van Eerten,
L. (Eds.) Proceedings of
the LREC workshop on Language Resources: From Storyboard to Sustainability and LR Lifecycle
Management (LRSLM2010), 23 May 2010, Valletta, Malta, pp. 34–39. Available from http://www.lrec-conf.org/proceedings/lrec2010/workshops/W20.pdf.
[Bański & Wójtowicz, 2010] Bański, P., Wójtowicz, B. (2010). The
Open-Content Text Corpus project. In Arranz, V., van Eerten, L. (Eds.) Proceedings
of the LREC workshop on
Language Resources: From Storyboard to Sustainability and LR Lifecycle Management (LRSLM2010),
23 May 2010, Valletta, Malta, pp. 19–25. Available from http://www.lrec-conf.org/proceedings/lrec2010/workshops/W20.pdf.
[Boot, 2009] Boot, P. (2009). Towards a TEI-based encoding scheme for the
annotation of parallel texts. Literary and Linguistic Computing 24(3), pp.
347–361; doi:https://doi.org/10.1093/llc/fqp023
[Cayless & Soroka, 2010] Cayless, H, Soroka (2010). On
Implementing string-range() for TEI. Presented at Balisage: The Markup Conference
2010, Montréal, Canada, August
3–6, 2010. In Proceedings of Balisage: The Markup Conference 2010. Balisage Series
on Markup Technologies, vol.
5 (2009); doi:https://doi.org/10.4242/BalisageVol5.Cayless01
[Chiarcos et al., 2009] Chiarcos, Ch., Ritz, J., Stede, M. (2009).
By all these lovely tokens... Merging conflicting tokenizations. In Ide, N.,
Meyers, A. (Eds.) Proceedings of the Third Linguistic Annotation Workshop (LAW
III) at ACL-IJCNLP 2009, Singapore, pp. 35-43.
[Cummings, 2009] Cummings, J. (2009). Converting Saint Paul: A new TEI
P5 edition of The Conversion of Saint Paul using stand-off methodology.
Literary and Linguistic Computing 24(3), pp. 307–317; doi:https://doi.org/10.1093/llc/fqp019
[DeRose, 2004] DeRose, S. (2004). Markup overlap: a review and a horse.
Proceedings of Extreme Markup Languages 2004.
[DeRose et al., 1990] DeRose, S., Durand, D., Mylonas, E., Renear, A.
(1990). What is text, really?. Journal of Computing in Higher Education, Winter
1990, Vol. I (2), pp. 3–26
[Dipper, 2005] Dipper, S. (2005). XML-based stand-off representation and
exploitation of multi-level linguistic annotation. In Proceedings of Berliner XML Tage 2005
(BXML 2005). Berlin, pp. 39–50.
[Goecke et al., 2010] Goecke, D., Metzing, D., Lüngen, H.,
Stührenberg, M., Witt, A. (2010). Different views on markup. distinguishing levels
and layers. In Linguistic modeling of information and markup languages. Contributions to language
technology. Springer Netherlands, pp. 1–21.
[Ide, 1998] Ide, N. (1998). Corpus Encoding Standard: SGML Guidelines for
Encoding Linguistic Corpora. Proceedings of the First International Language Resources
and Evaluation Conference,
Granada, Spain, pp. 463–470.
[Ide, 2000] Ide, N. (2000). The XML Framework and Its Implications for the
Development of Natural Language Processing Tools. Proceedings of the COLING Workshop
on Using Toolsets and
Architectures to Build NLP Systems, Luxembourg, 5 August 2000.
http://www.cs.vassar.edu/~ide/papers/coling00-ws-final.pdf
[Ide et al., 2000] Ide, N., Bonhomme, P., Romary, L. (2000). XCES: An
XML-based Standard for Linguistic Corpora. Proceedings of the Second Language Resources and
Evaluation Conference (LREC), Athens, Greece, pp. 825–830.
[Ide & Romary, 2007] Ide, N., Romary, L. (2007). Towards
International Standards for Language Resources. In Dybkjaer, L., Hemsen, H., Minker,
W. (Eds.), Evaluation of Text and Speech Systems, Springer, pages 263–284.
[Ide & Suderman, 2006] Ide, N., Suderman, K. (2006). Integrating
Linguistic Resources: The American National Corpus Model. In Proceedings of the Fifth
Language Resources and Evaluation Conference (LREC), Genoa, Italy.
[Ide & Suderman, 2007] Ide, N., Suderman, K. (2007). GrAF: A
Graph-based Format for Linguistic Annotations. In the proceedings of the Linguistic
Annotation Workshop, held in
conjunction with ACL 2007, Prague, June 28-29, pp. 1–8.
[Isard et al., 1998] Isard, Amy, McKelvie, David, Thompson, Henry S.
(1998). Towards a minimal standard for dialogue transcripts: a new SGML architecture
for the HCRC map task
corpus, In 5th International Conference on Spoken Language
Processing - 1998, paper 0322.
[Lawler & Aristar Dry, 1998] Lawler, J. and H. Aristar Dry (Eds.)
(1998). Using computers in linguistics: a practical guide. London:
Routledge.
[Kupść, 1999] Kupść, A. (1999). Haplology of the Polish Reflexive Marker.
In Borsley, R.D., Przepiórkowski, A. (Eds.) Slavic in HPSG, pp. 91–124,
Stanford, CA: CSLI Publications.
[Przepiórkowski & Bański, 2010] Przepiórkowski, A., Bański, P.
(2010). TEI P5 as a text encoding standard for multilevel corpus annotation. In Fang,
A.C., Ide, N. and J.
Webster (eds). Language Resources and Global Interoperability. The Second International
Conference on Global Interoperability for Language Resources (ICGL2010). Hong Kong: City University
of Hong Kong, pp. 133–142.
[Rehm et al., 2010] Rehm, G., Schonefeld, O., Trippel, T., Witt, A.
(2010). Sustainability of linguistic resources revisited. Presented at the International
Symposium on XML for the
Long Haul: Issues in the Long-term Preservation of XML, Montréal, Canada, August 2,
2010. In Proceedings of the
International Symposium on XML for the Long Haul: Issues in the Long-term Preservation
of XML. Balisage Series on
Markup Technologies, vol. 6 (2010); doi:https://doi.org/10.4242/BalisageVol6.Witt01
[Simons & Bird, 2008] Simons, G.F., Bird, S. (2008). Toward a
global infrastructure for the sustainability of language resources. In Proceedings of the
22nd Pacific Asia Conference on Language, Information and Computation: PACLIC 22. pp.
87–100.
[Witt et al., 2009b] Witt, A., Rehm, G., Hinrichs, E., Lehmberg, T.,
Stegmann, J. (2009). SusTEInability of linguistic resources through feature structures.
In Language Resources and Evaluation, vol. 43:3, pp. 363–372. doi:https://doi.org/10.1093/llc/fqp024
[1]TEI stands for Text Encoding Initiative – the project, the organization and the community
whose primary deliverable are the Guidelines for Electronic Text Encoding and
Interchange (TEI Consortium, 2010), summing up or recommending best practices for the encoding
of a multitude of varieties of textual phenomena (see Jannidis, 2009 for a concise description
and Renear, 2004 for broader discussion from the perspective of version P4 and for the placement
of the TEI in the context of text encoding studies). As Renear, 2004 puts it, after HTML,
the TEI is probably the most extensively used SGML/XML text encoding system in academic
applications. It is also worth pointing out that the TEI partially informed the development of
the
XLink and XPointer W3C recommendations, and also the ISO Feature Structure Representation
standard (ISO
24610-1). Currently, there is some interaction between the TEI encoding methods and
the emerging Language
Annotation Framework (LAF) standards, created by the ISO TC 37 SC
4 committee.
The TEI began in 1987 and has been through several versions, coming all the way from
SGML to XML and
following closely the developments in the field of XML specifications. As we shall
show below, some of the
attempts are still to be completed. The current version of the TEI is TEI P5 – see
Wittern et al., 2009 for a brief account of the innovations that this version introduces, and Cummings, 2008 for a broader view in the context of the Humanities.
[2] The acronym OWL in the sense of "ordinary working linguist" predates the Web Ontology
Language by a few
decades. A relevant book reference is e.g. Lawler & Aristar Dry, 1998, but as Michael Maxwell
(personal communication) tells me, the term was in use among field linguists at least in the 80's.
He goes on to say that its coining on the part of field linguists (particularly SIL field linguists)
was a reaction to the disdain with which some theoretical linguists looked down on
field work, or at least
on field work that wasn't grounded in some (acceptable) theory..
[4] Morphophonology, defined roughly as dealing with the alternation of phonemes (the
abstract contrastive
elements of speech), was often – and with some embarrassment – kept in dark corners
of most structuralist
theories of at least the first half of the 20th century.
[6] See Chiarcos et al., 2009 for discussion of cases where such fundamentally different
tokenizations need to be merged and for a proposal of a merging algorithm.
[7] Although some correlations between the violations of Renear et al., 1993's OHCO-3 and the
placement of the offending structures within the same document suggest themselves,
I believe this issue –
if it is a valid issue at all – to be beyond the scope of the present submission.
[8] Naturally, stand-off annotation is not restricted to XML applications alone, but this
is what we take as our
focus here.
[9] It is also worth mentioning that in some cases, the objects of interest do not form
a contiguous whole
and neither is there any hierarchy to talk about. For example, the layer of word sense
disambiguation need
only contain references to the particular forms of the lexemes disambiguated in the
accompanying lexicon.
This is exactly the case in the National Corpus of Polish, cf. Figure 4.
[11] In the earlier version of the corpus, for technical reasons, this layer was based
on the
morphosyntactic disambiguation layer (2.), which is reflected in some of the early
publications.
[12] The NCP listing is taken from http://nlp.ipipan.waw.pl/TEI4NKJP/ and slightly modified. The OCTC examples in Listing 2 and Listing 4 are taken from the OCTC
SVN repository. They use W3C-defined pointers, which can be used as a fallback from
the TEI XPointer version (not shown in the listing).
[13] Another way to cope with the lack of XPointer support has been to use XPointer-like
attributes with
in-house tools. This is the case of the PAULA, as illustrated by a fragment of Figure
1 in Dipper, 2005:
Such XPointers, however, would under the W3C definition return sequences of spans
rather than single spans --
what is missing is a position predicate that can be found in the OCTC listing above.
This is not meant as
criticism of the PAULA approach but merely as an observation that XPointer xpointer()
syntax, due to the lack
of tools implementing it, started a life of its own, being used as a concise replacement
for what could be,
e.g. @node, @from, and @length attributes.
[14] We ignore <ptr> and <ref>, because these are,
respectively, the plain and the adorned instances of the infrastructure that makes
<join> and its kin usable. Likewise, we ignore the role of pointing
attributes on elements other than those mentioned here.
[15] This is not to claim that the change was unidirectional and conditioned by the (X)CES.
In fact, as Lou
Burnard (personal communication) points out, TEI P3 already had a basis for stand-off
systems thanks to the
<xptr> element that handled external pointing. This has of course got streamlined in
P5, with the adoption of uniform pointing devices. For more on these changes, cf.
Wittern et al., 2009. Our usage of the term "reabsorption" concerns the fact that the CES/XCES
was/is a specialized system in which, by its very nature and due to the theoretical
assumptions that shaped
it, language-resource-oriented solutions had to be introduced from the outset. Whether
their emergence in
TEI P4 and P5 was only a matter of convergence of two independent lines of thought
or whether the more
specialized standard informed the more general one is something that I do not concern
myself with, although
I would welcome a situation whereby one open project benefits from the findings of
another, rather than
waste its time on reinventing the wheel.
[16] This prediction was eventually borne out, after some issues of infoset merger were
solved, especially those concerning @xml:base fixup
(cf. http://norman.walsh.name/2005/04/01/xinclude); nowadays, full XInclude
support is among the basic features that all general-purpose parsers are expected
to
have.
[18] It may be speculated that, since XInclude already allows for including raw text (as
a whole resource),
it should also be allowed to address into raw text (in the extreme stand-off fashion), with
appropriate XPointer schemes. For example, an appropriate scheme for addressing raw
text could be a variant
of the string-range() function, e.g.
Several
issues would have to be addressed at the application level (e.g. skipping the BOM
character, recognizing
character encoding, etc.), but on the whole, it does not feel particularly exotic
and would only require
lifting the XInclude ban on the simultaneous presence of @parse=”text” and
@xpointer as well as an adjustment in the MIME types enumerated in the XPointer Framework
Recommendation. Both issues are demand-driven and potentially interrelated: if XInclude
were able to handle
addressing into raw text, interest in developing modular implementations of XPointer
schemes might follow.
This is further elaborated on in Bański, 2010.
[20] The NCP and to a slightly larger extent the OCTC would introduce one more innovation
in the handling of annotation structures of the same text: complexes involving a {
teiHeader, text } and multiple instances of { teiHeader, standOff}
would become, abstractly, <teiHeader, { text,
standOff(1..N)}> (where angle brackets denote an
ordered pair, and curly brackets a set), because in both corpora, the header is shared
(XIncluded) among all the relevant documents. We leave the interesting consequences
of
such a setup for another occasion.
[21] Note that the fact that XInclude can act on IDs is enough only for the purpose of
including pieces of an XML tree (or entire trees). However, stand-off annotation is
(or
can be, with the replacement semantics of XInclude rather than the correspondence
semantics of @corresp), not about including
elements and thus merging infosets – given the need for different content models for
different annotation layers, stand-off annotation is about including text. A little step on the way towards this goal is offered by the xpath1() XPointer extension, supported by some parsers. Being an
XPath implementation, however, it cannot support addressing into the text content,
which
misses a crucial part of the entire enterprise (one cannot XInclude substrings for
the
purpose of defining a segmentation level, with segments often defined over substrings
of
orthographic words, cf. Bański & Przepiórkowski, 2009).
[22] It is worth mentioning two TEI-stand-off-oriented tools refined in the National Corpus
of Polish and
available under the GPL: poliquarp, for
querying and concordancing multi-level TEI corpora and anotatornia, for manual annotation of individual
layers.
Bański, P.,
Gozdawa-Gołębiowski, R. (2010). Foreign Language Examination Corpus for L2-Learning
Studies. In Rapp, R.,
Zweigenbaum, P., Sharoff, S. (Eds.) Proceedings of the 3rd Workshop on Building and
Using Comparable Corpora
(BUCC), Applications of Parallel and Comparable Corpora in Natural Language Engineering and
the
Humanities, 22 May 2010, Valletta, Malta, pp. 56–64. Available from http://www.lrec-conf.org/proceedings/lrec2010/workshops/W12.pdf.
Bański, P., Przepiórkowski, A.
(2009). Stand-off TEI annotation: the case of the National Corpus of Polish. In Ide,
N., Meyers, A. (Eds.)
Proceedings of the Third Linguistic Annotation Workshop (LAW III) at
ACL-IJCNLP 2009, Singapore, pp. 64-67.
Bański, P., Przepiórkowski, A.
(2010). The TEI and the NCP: the model and its application. In Arranz, V., van Eerten,
L. (Eds.) Proceedings of
the LREC workshop on Language Resources: From Storyboard to Sustainability and LR Lifecycle
Management (LRSLM2010), 23 May 2010, Valletta, Malta, pp. 34–39. Available from http://www.lrec-conf.org/proceedings/lrec2010/workshops/W20.pdf.
Bański, P., Wójtowicz, B. (2010). The
Open-Content Text Corpus project. In Arranz, V., van Eerten, L. (Eds.) Proceedings
of the LREC workshop on
Language Resources: From Storyboard to Sustainability and LR Lifecycle Management (LRSLM2010),
23 May 2010, Valletta, Malta, pp. 19–25. Available from http://www.lrec-conf.org/proceedings/lrec2010/workshops/W20.pdf.
Bird, S., Simons, G. (2003). Seven dimensions
of portability for language documentation and description. Language 79(3), pp.
557–582; doi:https://doi.org/10.1353/lan.2003.0149
Boot, P. (2009). Towards a TEI-based encoding scheme for the
annotation of parallel texts. Literary and Linguistic Computing 24(3), pp.
347–361; doi:https://doi.org/10.1093/llc/fqp023
Cayless, H, Soroka (2010). On
Implementing string-range() for TEI. Presented at Balisage: The Markup Conference
2010, Montréal, Canada, August
3–6, 2010. In Proceedings of Balisage: The Markup Conference 2010. Balisage Series
on Markup Technologies, vol.
5 (2009); doi:https://doi.org/10.4242/BalisageVol5.Cayless01
Chiarcos, Ch., Ritz, J., Stede, M. (2009).
By all these lovely tokens... Merging conflicting tokenizations. In Ide, N.,
Meyers, A. (Eds.) Proceedings of the Third Linguistic Annotation Workshop (LAW
III) at ACL-IJCNLP 2009, Singapore, pp. 35-43.
Cummings, J. (2008). The Text Encoding Initiative and
the Study of Literature. In Schreibman, S., Siemens, R. A Companion to Digital Literary
Studies. Oxford: Blackwell. http://www.digitalhumanities.org/companionDLS/
Cummings, J. (2009). Converting Saint Paul: A new TEI
P5 edition of The Conversion of Saint Paul using stand-off methodology.
Literary and Linguistic Computing 24(3), pp. 307–317; doi:https://doi.org/10.1093/llc/fqp019
DeRose, S., Durand, D., Mylonas, E., Renear, A.
(1990). What is text, really?. Journal of Computing in Higher Education, Winter
1990, Vol. I (2), pp. 3–26
Dipper, S. (2005). XML-based stand-off representation and
exploitation of multi-level linguistic annotation. In Proceedings of Berliner XML Tage 2005
(BXML 2005). Berlin, pp. 39–50.
Goecke, D., Metzing, D., Lüngen, H.,
Stührenberg, M., Witt, A. (2010). Different views on markup. distinguishing levels
and layers. In Linguistic modeling of information and markup languages. Contributions to language
technology. Springer Netherlands, pp. 1–21.
Ide, N. (1998). Corpus Encoding Standard: SGML Guidelines for
Encoding Linguistic Corpora. Proceedings of the First International Language Resources
and Evaluation Conference,
Granada, Spain, pp. 463–470.
Ide, N. (2000). The XML Framework and Its Implications for the
Development of Natural Language Processing Tools. Proceedings of the COLING Workshop
on Using Toolsets and
Architectures to Build NLP Systems, Luxembourg, 5 August 2000.
http://www.cs.vassar.edu/~ide/papers/coling00-ws-final.pdf
Ide, N., Bonhomme, P., Romary, L. (2000). XCES: An
XML-based Standard for Linguistic Corpora. Proceedings of the Second Language Resources and
Evaluation Conference (LREC), Athens, Greece, pp. 825–830.
Ide, N., Romary, L. (2007). Towards
International Standards for Language Resources. In Dybkjaer, L., Hemsen, H., Minker,
W. (Eds.), Evaluation of Text and Speech Systems, Springer, pages 263–284.
Ide, N., Suderman, K. (2006). Integrating
Linguistic Resources: The American National Corpus Model. In Proceedings of the Fifth
Language Resources and Evaluation Conference (LREC), Genoa, Italy.
Ide, N., Suderman, K. (2007). GrAF: A
Graph-based Format for Linguistic Annotations. In the proceedings of the Linguistic
Annotation Workshop, held in
conjunction with ACL 2007, Prague, June 28-29, pp. 1–8.
Ide, N., Véronis, J. (1993). Background and
context for the development of a Corpus Encoding Standard, EAGLES Working Paper,
http://www.cs.vassar.edu/CES/CES3.ps.gz
Isard, Amy, McKelvie, David, Thompson, Henry S.
(1998). Towards a minimal standard for dialogue transcripts: a new SGML architecture
for the HCRC map task
corpus, In 5th International Conference on Spoken Language
Processing - 1998, paper 0322.
Kupść, A. (1999). Haplology of the Polish Reflexive Marker.
In Borsley, R.D., Przepiórkowski, A. (Eds.) Slavic in HPSG, pp. 91–124,
Stanford, CA: CSLI Publications.
Przepiórkowski, A., Bański, P.
(2010). TEI P5 as a text encoding standard for multilevel corpus annotation. In Fang,
A.C., Ide, N. and J.
Webster (eds). Language Resources and Global Interoperability. The Second International
Conference on Global Interoperability for Language Resources (ICGL2010). Hong Kong: City University
of Hong Kong, pp. 133–142.
Rehm, G., Schonefeld, O., Trippel, T., Witt, A.
(2010). Sustainability of linguistic resources revisited. Presented at the International
Symposium on XML for the
Long Haul: Issues in the Long-term Preservation of XML, Montréal, Canada, August 2,
2010. In Proceedings of the
International Symposium on XML for the Long Haul: Issues in the Long-term Preservation
of XML. Balisage Series on
Markup Technologies, vol. 6 (2010); doi:https://doi.org/10.4242/BalisageVol6.Witt01
Renear, A. (2004). Text Encoding. In Schreibman, S.,
Siemens, R., Unsworth, J. A Companion to Digital Humanities. Oxford: Blackwell.
http://www.digitalhumanities.org/companion/
Simons, G.F., Bird, S. (2008). Toward a
global infrastructure for the sustainability of language resources. In Proceedings of the
22nd Pacific Asia Conference on Language, Information and Computation: PACLIC 22. pp.
87–100.
TEI Consortium (Eds.) (2010). TEI P5: Guidelines for
Electronic Text Encoding and Interchange. Version 1.6.0. Last updated on February
12th 2010. TEI Consortium.
http://www.tei-c.org/Guidelines/P5/
Thompson, H. S., McKelvie, D.
(1997). Hyperlink semantics for standoff markup of read-only documents, Proceedings of SGML
Europe. Available from http://www.ltg.ed.ac.uk/~ht/sgmleu97.html.
Witt, A., Heid, U., Sasaki, F., Sérasset, G.
(2009). Multilingual language resources and interoperability. In Language Resources and
Evaluation, vol. 43:1, pp. 1–14. doi:https://doi.org/10.1007/s10579-009-9088-x
Witt, A., Rehm, G., Hinrichs, E., Lehmberg, T.,
Stegmann, J. (2009). SusTEInability of linguistic resources through feature structures.
In Language Resources and Evaluation, vol. 43:3, pp. 363–372. doi:https://doi.org/10.1093/llc/fqp024
Wittern, Ch., Ciula, A., Tuohy, C. (2009). The
making of TEI P5. Literary and Linguistic Computing 24(3), pp. 281–296;
doi:https://doi.org/10.1093/llc/fqp017