Positioning HTML Table Normalization within an Existing Pipeline
Note: Use of the term: Normalization
The focus of this paper is the transformation of a lax HTML table element structure
to conform to a strict content model. We refer to this transform as normalization
in this paper.
Before looking at our design for the normalization of HTML tables, we will briefly describe how this was intended to fit into the existing pipeline comprising a set of XSLT filters. The pipeline was a significant design consideration.
Our overall XSLT processing pipeline comprises three sub-pipelines: two normally identical input pipelines (one for each input document) and a single output pipeline. A comparator, implemented in Java, combines the output from the two input pipelines using different alignment algorithms, the comparator then outputs a raw result as the initial input to the output pipeline.
Positioning HTML Table Normalization
in the pipeline
The relevant XSLT filter stages in the new XSLT pipeline:
-
Generic XML processing - input pipelines A and B
-
HTML Table Normalization - input pipelines A and B
-
HTML Table Validation - input pipelines A and B
-
CALS/HTML Table Regularisation - input pipelines A and B
-
XML Comparator - aligns the return from A and B input pipelines
-
Reversed Table Regularisation - output pipeline
The HTML table normalization stage was designed to be positioned immediately before the HTML table validator in the pipeline. Placing normalization before validation allows HTML tables to be processed as valid that would otherwise have been marked as invalid. The HTML table validator helps verify that the table normalization has worked as required by the content model.
HTML Table Validation
The HTML table validation XSLT filter is transpiled from Schematron. It marks valid
HTML tables with special attributes and only tables marked valid
have special processing applied.
The main responsibility of the HTML table validator is to ensure that the table has
sufficient integrity such that it can be processed by following XSLT filters. The
initial focus was on checking colspan and rowspan attributes would not cause an irregular number of columns in each row. Subsequent
enhancements added basic rules for table element structure. The validator fulfils
a secondary role in warning of potential problems even when these are not critical
to table processing.
CALS/HTML Table Processing (Regularisation)
Note: CALS Tables
At this point we need to mention CALS tables as some filters in the XSLT pipeline need common code to handle both HTML and CALS tables. The CALS table specification shares a common ancestry with HTML tables but there are still significant differences. CALS tables can be considered to be a superset of HTML tables.
The Table Regularisation XSLT filter stage in the pipeline was designed to work with
both HTML and CALS table models but was first implemented for CALS tables. The rationale
for 'regularisation' is described in the paper The Impossible Task of Comparing CALS Tables
. To quote from the paper:
...we need to regularise the tables which involves some fairly complex processing with the objective of representing the table in a regular rectangular grid on which the comparison can be performed.
XML Comparator
The XML Comparator in the pipeline is responsible for aligning elements from the XML document outputs from two input pipelines. The result is a single XML document with annotations added to the XML tree to mark where there are differences.
The comparator expects a strict structure for HTML and CALS tables (marked as valid)
in the input to the comparator. Special Control
attributes identify each table's Column Container
and Row Container
elements.
Reversed Table Regularisation
The output of this filter is a valid table that can be rendered normally with content
changes highlighted. Changes to table structure introduced by the Regularisation
filter are reversed. Differences in content are identified but when differences in
table structure conflict, the table structure from the priority
document is preserved.
Table elements in the HTML Standard
When <table> elements conforming to the HTML standard are encountered inside an XML document,
it would be reasonable to expect that they are processed in a way that conforms to
the HTML standard. For this reason we need an HTML table normalization solution within
our XSLT pipeline that aligns as closely as possible to the HTML standard. There are
two distinct parts in the standard: the User Content Model and the User Agent HTML Parser.
User Content Model
The HTML Living Standard for users defines a lax content model for all HTML elements, including the HTML <table> element. An example of the lax nature of the HTML table content model is that container
elements like <tbody> or <tr> can be omitted in certain circumstances.
User Agent HTML Parser
A user agent
(such as a web browser) conforming to the HTML standard must follow parsing rules
specified in [WHATWG 2023]. These parsing rules ensure that variations in the input HTML are processed, and
therefore rendered, in a standard way.
A convenient way to observe HTML table parser behaviour in the web browser is to look
at the elements
view of the browser's developer tools pane (see: Figure 1).
Figure 1: HTML Web Browser Screenshot
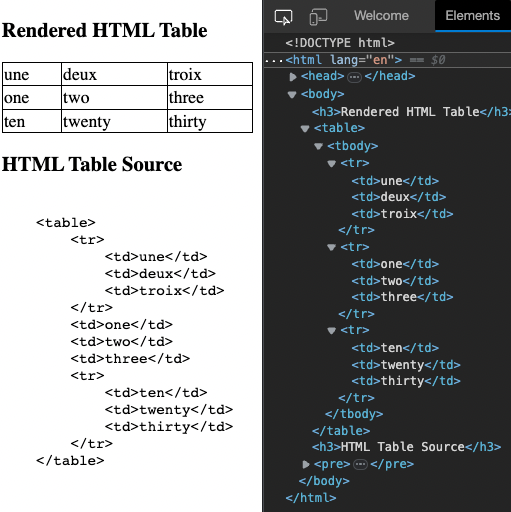
Showing a parsed HTML table element in a browser's developer tools pane.
A decision was made to develop an XSLT based HTML table normalizer
that aligned with the HTML table processing model, as specified in the HTML standard,
while allowing for necessary deviations from the standard.
The HTML table processing model specifies rules for the following set of insertion modes:
The case against integrating an off-the-shelf HTML parser
It takes a reasonable amount of effort to reproduce the table processing behaviour of an HTML parser. So, before looking at the XSLT design, we first need to address the question of why we did we not just simply integrate an existing parser.
An existing conforming HTML parser implemented in Java could technically have been
integrated into our pipeline without any major architectural change. In practice however,
we found we had additional and sometimes conflicting requirements that made an off-the-shelf
parser unsuitable. The different requirements have two main causes: the first cause
is that, in many cases, the input documents hosting HTML tables will not be HTML and
may also be in any namespace. The second cause is that the main goal for our normalisation
is to assist a table comparison rather than render the table; normalisation is taken
a step further for colgroup, col, tbody, thead and thead elements, in other cases we restrict normalisation, for example, so 'foreign' elements
within a table element are never extracted outside of a table element.
The Scope of HTML Table Normalization
We deliberately constrained the scope of the HTML table normalizer to only modify a lax HTML table element structure so that it conforms to the element structure in the strict content model defined by the HTML table standard. An additional requirement to the HTML table processing specification was that any unrecognized 'foreign' elements within a table should be kept and wrapped or hoisted as necessary according to the processing rules of adjacent HTML table elements.
We do not need to consider problems associated with non well-formedness of XML because an XML parser is at the first stage of the input pipeline. Also, at this stage in the pipeline, we do not consider other parts of the HTML standard that aren't related to element structure that could cause problems.
HTML Table Characteristics Outside the 'Normalization' Scope
In the list below we summarise HTML table characteristics that are not handled by the HTML table normalization filter but are considered in later pipeline stages:
-
The number of columns per table row - as affected by 'td' and 'th' elements along with 'colspan' and 'rowspan' attributes.
-
The arrangement of `colgroup` and `col` elements along with 'span' attributes found on these elements.
-
The order of the top-level elements: 'caption', 'colgroup', 'thead', 'tbody' and 'tfoot'.
-
When there is more than one of a specific top-level element. For example, two 'thead' elements.
The XSLT Design
The XSLT design for HTML table normalization has two distinct parts: the 'Content Model' module and the 'Processing' module. A line count for the XSLT of each module gives an approximate idea of the implementation complexity. There are about 60 lines of code for the 'Content Model' and 200 lines of code in the 'Processing' module (excluding XSLT for non-core features).
The Content Model
Element Data
The XSLT design is centred around a simple HTML table content model. The content model
for the HTML Table elements is represented by a single XPath map assigned to the $expectedChildren global variable. Each map entry has a key that is an HTML table element name and
a value comprising a sequence of expected child table element names corresponding
to the key:
<xsl:variable name="expectedChildren"
as="map(xs:string, xs:string+)"
select="map {
'table': ('caption','colgroup','tbody','thead','tfoot'),
'tbody': ('tr'),
'thead': ('tr'),
'tfoot': ('tr'),
'tr': ('td','th'),
'td': (''),
'th': (''),
'caption': (''),
'colgroup': ('col')
}"/>Data for the $expectedChildren map shown above are exposed separately by $tableElementNames and $tableDescendantNames global variables.
<xsl:variable name="tableElementNames" as="xs:string*" select="map:keys($expectedChildren)"/>
<xsl:variable name="tableDescendantNames" as="xs:string*"
select="let $t := $tableElementNames[not(. = 'table')] return ($t, $t!$expectedChildren?(.)) => distinct-values()"/>Content Model Functions
The content model provides three simple high-level functions that use the $expectedChildren map, these are:
findValidChild(currentName as xs:string, expectedChildList as xs:string*) as xs:string?
Returns $currentName if in the $expectedChildList sequence, otherwise it returns the nearest ancestor to $currentName in $expectedChildList if there is one otherwise the empty-sequence is returned.
If the result of this function is an empty sequence, it means that $currentName is not valid and cannot be made valid
by adding a wrapper element. If the result is equal to $currentName then $currentName is valid for the context, otherwise the result is the name of the wrapper element
that will make it valid for the context.
findParentName(childName as xs:string) as xs:string
Returns the parent element name corresponding to the $childName parameter. For the special case where the $childName parameter value is tr
then tbody
is always returned as tbody
overrides thead
and tfoot
.
isValidTableDescendant(elementName as xs:string) as xs:boolean
Returns true if the $elementName parameter value is a valid descendant of the table element.
Table Processing
The XSLT in the table processing module does not itself reference table element names
in XPath expressions except for the <table> element. Instead, all XPath associated with the table element structure uses data
from the separate module for the content model described above.
See XSLT Implementation Detail for a detailed description of the components in the XSLT module for table processing.
HTML Table Processing Rules In Practice
The HTML table processing model as documented in the HTML specification has a lot of detail; it is complicated by the need to describe the processing of tags in HTML that may not be well-nested. We describe here a simplified view of the HTML table processing model that is all we need for normalization when the HTML table is already in the form of parsed XML (and therefore also well-formed).
Any element inside an HTML table element and defined somewhere within the HTML table content model may either be valid,
with regard to the content model, or fit one of two possible error
cases. The first error case is where the processor adds one or more enclosing elements.
In the second error case the problem element is moved to another position higher up
in the tree.
Note: Insertion Modes and the HTML Standard
The insertion mode
in the HTML Table processing model corresponds directly with the content model as
defined in the XSLT. Each key in the $expectedChildren XPath map of in the content model XSLT is a table parent element name. This element
name aligns with an insertion mode in the HTML Table processing model. For example,
the tbody
in the XSLT corresponds with the in table body
insertion mode of the HTML Table processing model.
Not Deep Enough
The case when, given the insertion mode, the current element and zero of more adjacent siblings require one or more enclosing elements to be valid.
An example would be, when processing child elements of a <table> element (in table
insertion mode): if a <td> element followed by other <td> elements is encountered instead of the expected <tbody> element. In this case, we wrap the <td> elements inside a <tbody> element and then switch to the in table body
insertion mode to process the children of the <tbody> element.
Too Deep
The case when, given the insertion mode, the current element should to be at a higher level in the tree than it is currently to be valid.
An example of this would be encountering a <tbody> element when in the in row
insertion mode, i.e. processing the children of a <tr> element. In this case, the <tbody> element and all following siblings are lifted outside the <tr> element and inserted at a point in the element tree where they are valid.
Example 1 - Not deep enough
: A <table> element with child <tr> and <td> elements
XSLT Behaviour
For this example, we can see the effect of the XSLT transform for HTML table normalization by looking at the input XML alongside the expected output XML, as shown in Figure 2.
Figure 2: The input and output XML documents for Example 1
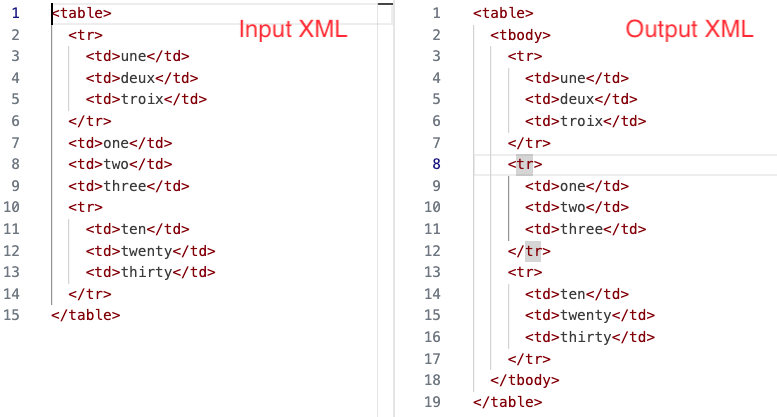
A view of the input XML (left) and output XML (right) for Example 1.
The HTML table in the input XML above has two problems; the first is a missing wrapper
<tbody> element for all child elements of <table>, while the second problem is a missing <tr> wrapper element for three <td> elements. In the output we can see that the missing <tbody> and <tr> enclosing elements have been added as required by the content model.
XSLT Execution
To explain execution of the XSLT, an xsl:message instruction in the fixupChildNodes() function adds a heading each time the function is called, starting always with the
heading
. Each insertion mode corresponds to the formal HTML Table Processing Model, in the
XSLT transform it is simply the name of the parent element which we're inserting nodes
into, for example, 'tbody' corresponds to the “in table body” insertion mode.
-- Insertion Mode: table --
The fixupChildNodes function is just a thin wrapper for an xsl:iterate instruction that iterates over each node in the sequence passed as a function parameter.
The terminal output in Figure 3 shows the state for each iteration of the node sequence passed to the function as
a parameter.
Figure 3: Tracing execution of Example 1

Screenshot of the output from xsl:message instructions within the XSLT after running Example 1.
Tracing recursive function calls
The trace output in Figure 3 for the fixupChildNodes function shows the function invoked recursively for each insertion mode for the current content model. Because recursion can be hard to follow when tracing code execution, the depth of recursion of this function is tracked for the purpose of code-tracing. The indentation at the start of each line in the trace output is proportional to recursion depth.
Showing the node state on each iteration
The state for each node iteration is shown on a single line by an xsl:message instruction
as it is processed, The final column on each line summarises the change in state of
the iterator by showing XML tag representations for the start and end of each sequence
of nodes to be wrapped. In this example we see <tbody>...</tbody> and <tr>...</tr> tags. Each part of the information on this trace output line is summarised below:
Table I
Summary of the descriptor used to track iterator state within the fixupChildNodes function.
| # | Descriptor | Iteration State Detail |
|---|---|---|
| 1 | {n} of {z} nodes
|
The position of the node in the iteration sequence where n is the position and z is the length of the sequence
|
| 2 | of {mode} | Where mode is the current insertion mode for the iterator.
|
| 4 | name: {name} | The node name, so when a node is an element this is the element name |
| 5 | expected: {name} | The expected element name returned after invoking findValidChild() with the current node and the insertion mode.
|
| 6 | buffer: {state} | The iteration state for the current node. Possible values: no, start, end, continueand hoist. |
| 7 | <{name}> | The XML start tag for the wrapper element name is shown when the buffer state is start. |
| 8 | </{name}> | The XML end tag for the wrapper element name is shown when the buffer state is end. |
Insertion Mode: table
In the trace output, the buffer
state reflects how element wrapping is performed in the iterator. In Example 1, the
buffer state is set to start
on the first element because the call to findValidChild() returns tbody and this is not the same as the tr element name. In this state, instead of adding the element to the result tree, the
iterator buffers
the tr element by setting the $wrapStart iterator parameter to the node position. At the same time, to track the required
element wrapper name, the $prevValidName iterator parameter is set to tbody.
The call to findValidChild() for all following elements (td, td, td and tr) in the iteration returns tbody also, because this matches the $prevValidName the buffer state is shown as continue
, in this state, nodes are still not added to the result tree but the iterator parameters
remain unchanged.
Every time, the iteration completes, the addWrapper($nodes, $prevValidName, $wrapStart, $end) function is called to flush
any buffer. In this case, the buffer is non-empty ($wrapStart > 0) so the function encloses the node sequence in a tbody wrapper element. The tbody element is then processed by an xsl:apply-templates call which in turn invokes the iterator again, but this time in the tbody insertion mode.
Insertion Mode: tbody
The iterator processes the same nodes again, but this time in the tbody
mode. The expected name for the first element is tr, the same as that of the first element, we therefore do not need to buffer (buffer
state: no
), but instead apply templates to this element. This invokes a recursive call on the
iterator with the tr insertion mode which completes without any further buffering. The tbody
insertion mode is then returned to as the recursive call completes.
The next three iterator nodes are td elements, not the expected tr element for this mode, so the buffer state reflects this as: start
, continue
and continue
. The next node is however a tr element which must be emitted. First however the addWrapper() call is made to flush the buffer (buffer state: end
), wrapping the td elements in a tr element which is then processed in the tr
insertion mode. The process then continues with no further buffering and consequent
element wrapping required.
Example 2 - Too Deep
: <tbody> element within a <tbody> element
XSLT Behaviour
We can now look at an example of the too deep
case. Here, a problem <tbody> element in the input XML is nested within the first <tbody> element. The problem <tbody> element is followed by a <tr> element that also requires special treatment.
Figure 4: The input and output XML documents for Example 2
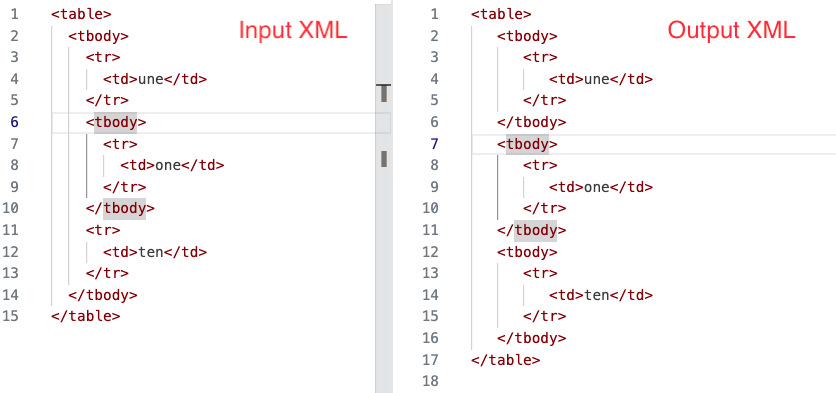
A view of the input XML (left) and output XML (right) for Example 2.
In this example, the problem <tbody> element is highlighted in the output XML shown above on the right. The <tbody> element that was too deep in the input XML (being enclosed within another <tbody> element) has been hoisted
outside of its parent <tbody> element so it is now a child of the <table> element.
The <tr> element following the problem <tbody> element is hoisted at the same time - inline with the processing model. However,
because it is then processed in the in table
insertion mode, a <tbody> element is added to enclose the <tr> element.
XSLT Execution
The xsl:message output for Example 2 (see Figure 5) helps explain the code flow in the too deep
scenario.
Figure 5: Tracing execution of Example 2

Screenshot of the output from xsl:message instructions within the XSLT after running Example 2.
In the terminal output for Example 2 (see Figure 5), all nodes are processed normally, with a buffer state of no
up until the problem <tbody> element is encountered, then the state changes to hoist
and an xsl:break instruction terminates the iteration for the tbody mode.
After the main template calls fixupChildNodes() it checks for any deltaxml:hoist element in the returned hoist sequence. All nodes before the hoist element are copied
into the current element. Nodes inside the hoist element (and any following nodes)
are stripped of any hoist element wrappers and copied outside the current element
as following siblings. The xsl:message output from the template starting with Insert in tbody...
tells us which nodes are inserted and which nodes are hoisted. In this example, the
first tr element is copied into the current tbody element but the inner tbody element and following tr element are (after unwrapping) processed again by a call to fixupChildNodes() but with the table insertion mode. The tbody element and its descendant tr and td elements are processed with no drama. The tr element that follows the tbody element however is invalid in the table insertion mode and the buffer state changes to start
and hence it is wrapped in a tbody element.
XSLT Implementation Detail
The XSLT implementation is probably less interesting than the design and the execution flow. However, for completeness, in this section we will have a brief look at the code. The three main code parts were touched on earlier, these have the XSLT declarations:
-
<xsl:template mode="inTable"... -
<xsl:function name="fn:fixupChildNodes"... -
<xsl:function name="fn:addWrapper"...
The XSLT Template (inTable
mode)
This template's match pattern ensures a match for elements identified as a container
element in the table content model. The responsibility of the template is to first
process all child nodes, calling fixupChildNodes(). It then determines the position of the first 'hoist' element ($firstHoistPosition) in the fixed nodes. All child nodes up to the hoist position are
added as children of the context element. Child nodes following the hoist position
are firstly unwrapped of any hoist-element wrappers, then processed for the required
parent of the context element, and finally they are added as following siblings to
the context element.
The XSLT code for this template is shown below. Calls to the principal function fixupChildNodes() (described later in this section) are highlighted in bold.
<xsl:template match="*[local-name() = $tableElementNames]" mode="inTable">
<xsl:variable name="fixedChildNodes" as="node()*"
select="fn:fixupChildNodes(local-name(), node())"/>
<xsl:variable name="firstHoistPosition" as="xs:integer"
select="fn:firstHoistPosition($fixedChildNodes)"/>
<xsl:choose>
<xsl:when test="$firstHoistPosition gt 0">
<xsl:variable name="parentName" as="xs:string"
select="(fn:reverseMapLookup(local-name(), $expectedChildren),'')[1]"/>
<xsl:variable name="hoistElementsForParent" as="node()*">
<xsl:apply-templates
select="subsequence($fixedChildNodes, $firstHoistPosition)"
mode="stripHoistWrapper"/>
</xsl:variable>
<xsl:copy>
<xsl:sequence
select="@*, subsequence($fixedChildNodes, 1, $firstHoistPosition - 1)"/>
</xsl:copy>
<xsl:sequence select="fn:fixupChildNodes($parentName, $hoistElementsForParent)"/>
</xsl:when>
<xsl:otherwise>
<xsl:copy>
<xsl:sequence select="@*, $fixedChildNodes"/>
</xsl:copy>
</xsl:otherwise>
</xsl:choose>
</xsl:template>The fixupChildNodes function
This is the main function in the XSLT that processes the nodes inside HTML table elements.
The responsibility of fixupChildNodes() is to return each node in the $parentNodes parameter in a way determined by the properties of either a preceding node in the
sequence and the insertion mode, or the node itself and the insertion mode.
Node test conditions
The main conditions that affect the state in which a node is returned for a specific insertion mode are:
-
expected element - when it is an expected element
-
descendant element - when it is an element within the content model of an expected element
-
ancestor element - when it is an element that is within the content model of an ancestor of an expected element
-
other - when it does not meet any of the above conditions
Returned state of the node
The node state returned by this function is controlled by each node test condition listed above. The list below shows the return node state for each node corresponding to the node test conditions.
-
expected element - return the input node
-
descendant element - return the input node enclosed in the expected element
-
ancestor element - return the input node and all following siblings wrapped in a
hoist
element. -
other - return the input node
Detail
While the fixupChildNodes() function appears relatively straightforward, it does a lot of work due to indirect
recursive calls via xsl:apply-templates and fn:addWrapper(). The significant function calls fn:addWrapper(), fn:calcWrapState(), and fn:findValidChild() are highlighted in bold in the code below.
The xsl:iterate instruction iterates each node passed in the function's $parentNodes parameter based on the $parentName which corresponds to an HTML table processing model insertion mode. This instruction
tracks state in the iteration with just two parameters: prevValidName and wrapStart. These parameters identify respectively the current wrapper element name (i.e. the
valid parent name) and the starting node position of a sequence of nodes in the iteration
that should be wrapped. A node sequence is wrapped as soon as we encounter a table
element that is valid or that has a different required parent element name than $prevValidName.
In the XSLT Execution
part of Examples 1 and 2 earlier, we saw the xsl:message output from this iterator.
Placeholders for the xsl:message instructions used for the examples are included as
XML comments in the XSLT.
<xsl:function name="fn:fixupChildNodes" as="node()*">
<xsl:param name="parentName" as="xs:string"/>
<xsl:param name="parentNodes" as="node()*"/>
<!-- xsl:message 'Insertion Mode...' -->
<xsl:iterate select="$parentNodes">
<xsl:param name="prevValidName" as="xs:string" select="''"/>
<xsl:param name="wrapStart" as="xs:integer" select="0"/>
<xsl:on-completion>
<!-- xsl:message 'completed...'' -->
<xsl:sequence select="fn:addWrapper(
$parentNodes, $prevValidName, $wrapStart, count($parentNodes) + 1)"/>
</xsl:on-completion>
<xsl:variable name="isWrapStarted" as="xs:boolean" select="$wrapStart gt 0"/>
<xsl:variable name="nodeName" as="xs:string" select="local-name()"/>
<xsl:variable name="validName" as="xs:string?"
select="fn:findValidChild($nodeName, $expectedChildren?($parentName))"/>
<xsl:variable name="state" as="map(xs:string, xs:boolean)"
select="fn:calcWrapState(., $nodeName, $validName, $prevValidName, $isWrapStarted)"/>
<!-- xsl:message 'n of z nodes...' -->
<xsl:if test="not($state?continue)">
<xsl:sequence select="
fn:addWrapper($parentNodes, $prevValidName, $wrapStart, position())"/>
</xsl:if>
<xsl:choose>
<xsl:when test="$state?hoist">
<deltaxml:hoist-nodes>
<xsl:sequence select="subsequence($parentNodes, position())"/>
</deltaxml:hoist-nodes>
<!-- xsl:message '=== break iteration ===' -->
<xsl:break/>
</xsl:when>
<xsl:when test="$state?startWrap">
<xsl:next-iteration>
<xsl:with-param name="prevValidName" select="$validName"/>
<xsl:with-param name="wrapStart" select="position()"/>
</xsl:next-iteration>
</xsl:when>
<xsl:when test="$state?endWrap">
<xsl:apply-templates select="." mode="inTable"/>
<xsl:next-iteration>
<xsl:with-param name="prevValidName" select="''"/>
<xsl:with-param name="wrapStart" select="0"/>
</xsl:next-iteration>
</xsl:when>
<xsl:otherwise>
<xsl:apply-templates select="if ($isWrapStarted) then () else ." mode="inTable"/>
</xsl:otherwise>
</xsl:choose>
</xsl:iterate>
</xsl:function>The calcWrapState function
This function is invoked from within the xsl:iterate instruction from within fixupChildNodes(). It returns the required 'wrap' state for each node iteration in . This controls
the grouping of nodes that require a 'wrapper' element or a 'hoist' container element.
The state is returned in the form of a map comprising four map entries with the keys:
startWrap, endWrap, hoist and continue, each map entry has a boolean value. The continue value is true when the state does not change for the next iteration, that is, when startWrap, endWrap and hoist are all false.
<xsl:function name="fn:calcWrapState" as="map(xs:string, xs:boolean)">
<xsl:param name="c.x" as="item()*"/>
<xsl:param name="nodeName" as="xs:string"/>
<xsl:param name="validName" as="xs:string?"/>
<xsl:param name="prevValidName" as="xs:string"/>
<xsl:param name="isWrapStarted" as="xs:boolean"/>
<xsl:variable name="isValid" as="xs:boolean"
select="($nodeName eq $validName, false())[1]"/>
<xsl:variable name="m" select="map {
'startWrap': exists($validName) and not($isValid) and
not($validName eq $prevValidName),
'endWrap': $isWrapStarted and $isValid,
'hoist': $c.x/self::element() and
empty($validName) and fn:isValidTableDescendant($nodeName)
}"/>
<xsl:sequence select="map:put(
$m, 'continue', not($m?startWrap or $m?endWrap or $m?hoist))"/>
</xsl:function>The addWrapper function
The addWrapper function is called from within the xsl:iterate instruction of the fixupChildNodes function. It is invoked each time the state of the iterator changes and when the
iterator completes. The body of this function's code is enclosed within an xsl:if instruction; causing an empty sequence to be returned unless there are nodes to wrap
($wrapStart gt 0).
This function's role is to wrap the required sequence of nodes within the required
valid element name ($validName).
The sequence of nodes to wrap is a subsequence of $parentNodes with a range as defined by the $wrapStart and $wrapStart parameters.
Immediately before returning the element wrapper, xsl:apply-templates is invoked with the new wrapper element as the context item, ensuring the child nodes
are processed with their new insertion mode, as determined by their new wrapper element.
<xsl:function name="fn:addWrapper" as="node()*">
<xsl:param name="parentNodes" as="node()*"/>
<xsl:param name="validName" as="xs:string"/>
<xsl:param name="wrapStart" as="xs:integer"/>
<xsl:param name="endPosition" as="xs:integer"/>
<xsl:if test="$wrapStart gt 0">
<xsl:variable name="firstChildName" as="xs:QName"
select="node-name($parentNodes[$wrapStart])"/>
<xsl:variable name="wrapperPrefix" select="
let $pfx := prefix-from-QName($firstChildName) return
if ($pfx) then concat($pfx, ':') else ''"/>
<xsl:variable name="sequenceLength" as="xs:integer"
select="$endPosition - $wrapStart"/>
<xsl:variable name="childNodes" as="node()*"
select="subsequence($parentNodes, $wrapStart, $sequenceLength)"/>
<xsl:variable name="nodesWithWrapperElement" as="element()">
<xsl:element name="{$wrapperPrefix || $validName}"
namespace="{namespace-uri-from-QName($firstChildName)}">
<xsl:sequence select="$childNodes"/>
</xsl:element>
</xsl:variable>
<xsl:apply-templates select="$nodesWithWrapperElement" mode="inTable"/>
</xsl:if>
</xsl:function>Project Integration
The XSLT for fixing lax HTML tables as described in this paper is now fully integrated into our XSLT pipeline. This first shipped in DeltaXML's XML Compare product in February 2023, two months prior to the time of writing. No normalizer related problems have been reported by users, but additional tests with badly fractured table structures did highlight the need for a small design change which was subsequently implemented.
Effect on the XSLT Pipeline
Internally, the most notable impact of this work for the development team is that it has barely been noticed. The XSLT originally designed for CALS tables with a much stricter schema could rely on a standard element hierarchy for HTML tables, allowing the focus to be on the detailed differences in these two table standards.
Performance
To understand the relative time taken by the HTML table normalization XSLT, we ran
the XSLT pipeline within our main product, XML compare. We generated an input XML
file especially to measure performance. The XML file contained a single HTML <table> element containing 1000 <tr> elements; with each <tr> containing 7 <td> elements.
We gathered the averaged timing metrics for each XSLT filter and the comparator in the pipeline while the XSLT pipeline was run five times. The relative timings for the most significant pipeline stages are shown in Chart 1 (Figure 6).
Chart 1 (Figure 6): Relative Timings for XSLT Pipeline Stages
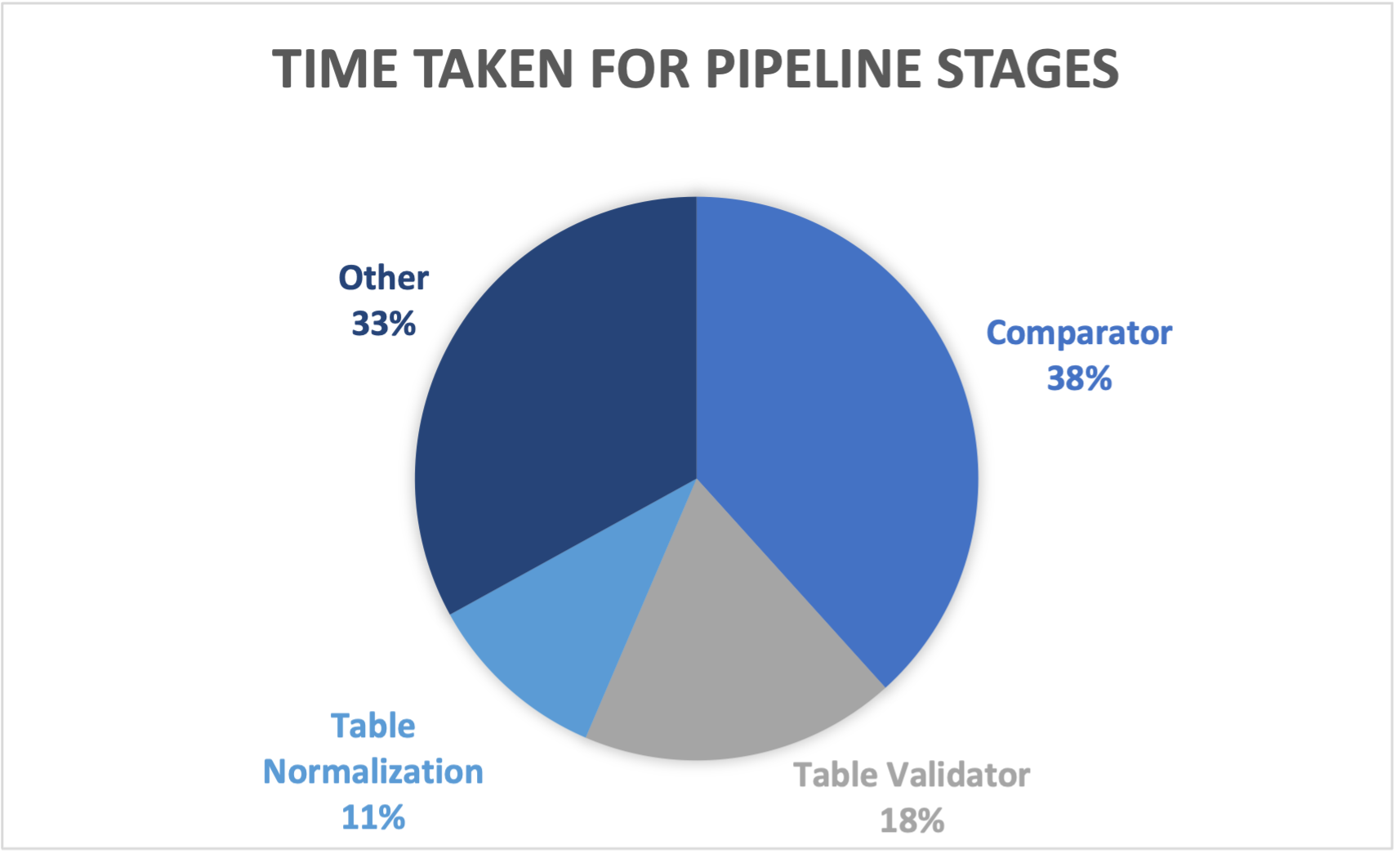
In the relative timings shown in Chart 1 (Figure 6) we can see that the HTML table normalization XSLT takes 11% of the overall time to run the whole pipeline. This compares favourably with the time take by the HTML table validation stage which takes up 18% of the pipeline time.
Our preliminary conclusion from these relative timings is that the XSLT table normalization performance is satisfactory. It does not have a significant impact on the overall performance. We have not yet tested this claim but we can also speculate that the HTML table normalization contributes to the performance of following filters by reducing their complexity.
Additional HTML Table Considerations
This paper does not cover in detail processing rules applied to HTML tables not specified in the HTML table processing model. We will however summarise these here:
-
Consistent ordering of
thead,tbodyandtfootelements -
Consolidating
colgroupandcolelements into a singlecolgroupelement -
Substitution of
spanattributes oncolgroupandcolelements -
XML element namespaces on HTML table elements are ignored
Testing
Testing was an intrinsic part of the development of the HTML table normalization XSLT. While the 26 dedicated normalizer tests (see Figure 7) represent a fraction of the large number of possible element permutations for lax HTML tables, we have a reasonable level of confidence that they cover all major cases that the normalizer was designed for. Tests are defined using the XSpec XSLT test framework to verify that the HTML table normalizer exhibits the required behaviour.
Each test was also run manually with XSLT 4.0's proposed parse-html() function with Saxonica's SaxonJ 12.0 XSLT processor. In most cases the required behaviour
aligns with the HTML table specification, the most significant exceptions are associated
with 'foreign' elements and namespaces.
Each XSpec test scenario comprises a 'context' element containing a single HTML table, paired with an 'expect' element containing the required HTML table output. The table for each test either already conforms to the strict model or has a table element structure including different permutations of the following characteristics:
-
The case where all elements in the table element tree are already valid according to the strict content model.
-
'Foreign' elements that are not valid anywhere within the HTML table strict content model.
-
One or more elements that require zero or more wrapper elements.
-
One or more elements the require hoisting up zero or more levels in the element tree
-
A sequence of elements that, when hoisted, must be split between the immediate parent and one or more ancestor elements
-
An element ('tr') requiring a wrapper with more than one possible valid parent names ('thead','tbody','tfoot').
The separation of the HTML table content model from the processing XSLT helped with the degree of confidence on test coverage, with tests focusing on essentially three parts: content model querying, element-grouping and wrapping, and element-hoisting.
Around 200 further tests verify behaviour of the HTML table normalizer with it integrated into the pipeline. An important requirement here is that the HTML table validation filter, which immediately follows the table normalization filter in the pipeline, detects and adds markup to HTML tables with element structure that could not be fixed by the normalizer.
Figure 7: The XSpec test result summary - demonstrating 3 failed tests

The XSpec compiler xsl:message construction was optimised slightly to provide the result summary.
Lessons Learnt
Method for Understanding Recursive Code
When I started writing this paper, I revisited XSLT code I had not touched for a long
while. On first inspection I found the XSLT disarmingly simple, there are no clever
parts to decipher and no complex data-structures that hold state. The main iterator
that does the heavy-lifting maintains the state of just two primitive types, a xs:string and an xs:integer. Why then, could I not understand how the code worked at a high-level?
The answer to this question, for me at least, was the reliance on recursion in the most significant parts of the code. I was finding it difficult to follow the code execution path through the various recursive function calls.
By inserting xsl:message instructions into the fixupChildNodes() function (see placeholders for these instructions in the fixupChildNodes code section) it became possible to see the order in which nodes were processed. To help
make the xsl:message output clearer, indentation was added for each xsl:message output
line. The indentation inserted was proportional to the function recursion depth at
the position of the xsl:message instruction. The final touch was to use utility library
functions for fixed-width columns and colourization of field values in the output.
Looking now at the xsl:message output after these changes it is more evident how the code is fixing the problem nodes in the examples included in this paper.
Potential Masking of Element Wrapper Problems
Following some minor refactoring, a flaw was introduced in the grouping logic for wrapping elements; this problem was not discovered immediately because test results remained unchanged. The element 'hoisting' functionality had in fact masked the problem by hoisting invalid elements outside elements that were wrapped incorrectly by the algorithm.
If this logic flaw had not been identified from xsl:message output, as well as the performance impact, this could have caused maintenance problems
later on. To allow similar element wrapping problems to be found reliably in future
we should add new tests where element hoisting is disabled.
Revisiting HTML Table Validation
We have found that the HTML table normalization effectively makes some of our existing HTML table validation rules redundant; table validation follows HTML table normalization in the pipeline. In future we should be able to simplify the HTML table validation rules.
The Benefits of 'Deep' Code Reviews
Initial work for the XSLT normalizer was completed well outside initial time estimates for the task but within the allotted two-week sprint time we use, following the Agile methodology. At least some of the estimate overrun can be attributed to a late decision to align the normalizer behaviour more closely with the HTML table specification.
In the course of completing this paper, we have had the rare luxury of reviewing code
outside the normal time constraints afforded by the Agile methodology. There were
two main consequence from this: a small but significant design flaw (associated with
hoisted elements being distributed amongst multiple ancestors) was identified and
fixed, and secondly, the addWrapper() function was simplified considerably by always applying templates to the new wrapper
element.
Related Works
Grammar Driven Markup Generation
Previous research on the same concept of driving a transform using a content model can be found; an extract from a related paper's introduction:
This paper will demonstrate how an XML schema (a RELAX NG schema specifically) can be used to generate a valid instance of the schema from an invalid but well-formed XML instance. In other words, we shall normalize a well-formed XML instance so it conforms to a given schema.
— [Blažević 2010]
In contrast to the paper linked above which employed Haskell and OmniMark, the solution in this paper uses XSLT. Another significant difference is that we use a content model defined in a simple XPath map instead of the RELAX NG schema used in the linked paper.
Adapting imperative algorithms
In our paper we describe an approach for taking an imperative algorithm, as specified in the HTML table processing model, and implementing it in XSLT, a functional language. A different approach to this same problem was covered in [Sperberg-McQueen 2017].
XSLT Pipelines
In our project, the XSLT for normalising HTML tables fits within an XSLT pipeline comprising a set of distinct XSLT transform stages. This approach brings many benefits, as described in Pipelined XSLT Transformations [Nordström 2020].
Conclusion
In this paper we have looked at an example of using XSLT to transform XML from a lax
element structure to one defined by a strict content model (normalization
); demonstrating how XSLT's conventional recursive descent tree-processing can be
driven by the lax input tree structure but with the descent flow controlled by a separately
defined and stricter content model for the output.
One interesting aspect of the XSLT design is how potentially complex combinations of element 'hoisting' and 'wrapping' can be performed in (essentially) a single pass. This 'single pass' claim should be qualified by the observation that there is effectively a 'stutter' in the flow, this happens each time child nodes must be reprocessed because a change in insertion mode is required to ensure the output conforms to the content model.
We have also shown that by positioning HTML table normalization near the start of an XSLT pipeline, the following table processing XSLT (for CALS and HTML tables) benefits from processing a uniform input tree.
Lastly, our samples show that XSLT's xsl:message instruction, with formatted and colored output, can be effective for tracing and
explaining the state of recursive calls within an iterator throughout the XSLT execution.
References
[WHATWG 2023] WHATWG (Apple, Google, Mozilla, Microsoft). HTML Living Standard: Parsing HTML documents - last updated April 2023. https://html.spec.whatwg.org/multipage/parsing.html.
[Blažević 2010] Blažević, Mario. “Grammar-driven Markup Generation.” Presented at Balisage: The Markup Conference 2010, Montréal, Canada, August 3 - 6, 2010. In Proceedings of Balisage: The Markup Conference 2010. Balisage Series on Markup Technologies, vol. 5 (2010). doi:https://doi.org/10.4242/BalisageVol5.Blazevic01.
[Sperberg-McQueen 2017] Sperberg-McQueen, C. M. “Translating imperative algorithms into declarative, functional terms: towards Earley parsing in XSLT and XQuery.” Presented at Balisage: The Markup Conference 2017, Washington, DC, August 1 - 4, 2017. In Proceedings of Balisage: The Markup Conference 2017. Balisage Series on Markup Technologies, vol. 19 (2017). doi:https://doi.org/10.4242/BalisageVol19.Sperberg-McQueen01.
[La Fontaine and Francis 2022] La Fontaine, Robin, and John Francis. “The Impossible Task of Comparing CALS Tables.” Presented at Balisage: The Markup Conference 2022, Washington, DC, August 1 - 5, 2022. In Proceedings of Balisage: The Markup Conference 2022. Balisage Series on Markup Technologies, vol. 27 (2022). doi:https://doi.org/10.4242/BalisageVol27.LaFontaine01.
[Nordström 2020] Nordström, Ari. “Pipelined XSLT Transformations.” Presented at Balisage: The Markup Conference 2020, Washington, DC, July 27 - 31, 2020. In Proceedings of Balisage: The Markup Conference 2020. Balisage Series on Markup Technologies, vol. 25 (2020). doi:https://doi.org/10.4242/BalisageVol25.Nordstrom01.