Motivation
XSLT version 3 introduces the accumulator, a special and elegant way you can associate data with nodes of a tree and retrieve that data as needed. To incorporate an accumulator into your XSLT stylesheet, you design the data association logic to serve your needs, implement the design using one or more accumulator rules, and retrieve the data wherever you need it using dedicated accumulator functions. At some point in your work, you will likely want to examine or debug the accumulator's behavior, checking interactively that your implementation matches the design you intended. If your XSLT code is significant or long-lasting, you might want to write tests that check the behavior in an automated way. The debugging and testing techniques you might use for accumulators are a little different from techniques you use for templates and functions. My purpose here is to make debugging and testing accumulators easier for you, so you can use accumulators more efficiently and effectively.
Background About Accumulators
If XSLT accumulators are new to you, first pause to consider the word "accumulator." This word suggests the XSLT accumulator's capability of computing a value progressively, especially during streamed processing of an XML tree that may be too large to fit in memory. In some cases, "accumulate" aptly describes the task the accumulator performs. However, try not to take the word "accumulator" too literally, because some XSLT accumulators, instead of collecting more and more things, behave more like a:
-
Counter, potentially resettable at relevant spots in the tree
-
Stack or queue, which can add and remove items
-
Tracker of some kind of state, based on patterns of interest
Keeping your mind open to these other roles can help you identify when an accumulator is a good fit for a problem you need to solve. Remembering that the feature's name describes only a subset of functionality is similar to how you remember that XSLT "stylesheets" can perform many useful tasks unrelated to styling.
When you first hear that an accumulator associates user-defined data with nodes, you might think it is like calling a user-defined function on nodes to compute and retrieve data. While you can use accumulators in that manner, accumulators also have some distinctive capabilities. Let's look at them.
Inertia
Suppose you're scanning the body of an HTML document from top to bottom and for
any paragraph, you want to retrieve its section depth — that is, the level of the
nearest heading that the paragraph is underneath. When you see an
<h1> element, you know that everything afterward is at depth 1
until you reach an <h2> element, at which point everything afterward
is at depth 2, and so on. The headings are significant because that's where the
depth value might change. In between headings, the depth stays the same.
Figure 1: HTML Body with Paragraphs Indicating Their Section Depth
<body>
<h1>HEADING LEVEL 1</h1>
<p>Depth = 1</p>
<div>
<p>Depth = 1</p>
</div>
<h2>HEADING LEVEL 2</h2>
<p>Depth = 2</p>
<h2>HEADING LEVEL 2</h2>
<p>Depth = 2</p>
</body>The dedicated functions that retrieve data from an accumulator natively know how to find and return the last computed value. If you implement the depth computation using an accumulator, you don't have to write code to traverse the document in reverse document order, in search of prior headings. Your accumulator declaration concisely focuses on the headings alone. The accumulator value remains unchanged until a heading triggers a match against one of the accumulator rules.
Figure 2: Accumulator Declaration for Three Heading Depth Levels
<xsl:accumulator name="heading-depth" as="xs:integer" initial-value="0"> <xsl:accumulator-rule match="h1" select="1"/> <xsl:accumulator-rule match="h2" select="2"/> <xsl:accumulator-rule match="h3" select="3"/> </xsl:accumulator>
The XSLT code snippet above declares an accumulator that associates the heading
level with each heading element up to <h3>. In the thought
experiment where you're scanning the sample HTML body shown, when you see an
<h1> element, the match="h1" accumulator rule in
XSLT says the accumulator value is 1. When you see the next HTML
paragraph and the one after that, inertia says the heading depth is the most recent
accumulator value, which is 1. The XSLT code snippet has no accumulator
rule with match="p" that says to keep using the last value, because
that behavior comes for free.
Also, notice that this example expresses accumulator rules for heading elements while retrieving the depth value at paragraph elements. The nodes where you explicitly compute associated data don't have to be the same as the nodes for which you want to retrieve data. Thanks to the implicit inertia behavior, you can retrieve the data for any context node (except that the accumulator does not associate values with attribute nodes or namespace nodes).
Running Counts and Accumulation
Not only can you access the last computed value, but you can also use it to
compute a new value. Within an accumulator rule, you can reference the special
variable named $value, which stores the latest value of the accumulator
before the rule recomputes the value. This capability is useful if you want to
compute a running total of HTML headings seen so far, up to any given context
paragraph.
Figure 3: Accumulator Declaration for Counting Headings
<xsl:accumulator name="heading-count" as="xs:integer" initial-value="0">
<xsl:accumulator-rule match="h1 | h2 | h3">
<xsl:sequence select="$value + 1"/>
</xsl:accumulator-rule>
</xsl:accumulator>More generally, the $value variable helps you implement running
statistics or accumulate data in a stack or queue. The $value variable
can also be handy for debugging using XSLT
Messages.
Note
In this example, the computation of new accumulator value in
<xsl:accumulator-rule> uses a child
<xsl:sequence> element rather than a select
attribute. Both ways work, but we will see in XSLT
Messages that using a child element here is a bit more
debugging-friendly.
Start/End Distinction in Accumulator Rules
To illustrate another important feature of accumulators, imagine writing XSLT to style an XML document that includes some content that should be kept internal only, such as author remarks and content intended for a future release. You must not only suppress the internal content from the main flow but also ignore this content while generating things like tables of content or lists of cited bibliographic entries. Content might even be internal-only for multiple reasons, such as an author remark nested inside a future-release subsection.
Let's design an accumulator that tells us when a particular XML element is
internal-only due to its own markup or its ancestry. For this example, suppose the
author remarks use an XML element named <remark> and the
future-release content is any element that has an attribute
condition="future".
Figure 4: Sample XML with Internal-Only Content
<section>
<title>Sample Title</title>
<remark>Ready for release</remark>
<para>Sample external content</para>
<section condition="future">
<title>Sample Subsection Title</title>
<remark>For next year, maybe</remark>
<para>Additional content</para>
</section>
</section>Imagine a television news program whose scrolling chyron shows the serialized XML content shown above. The significant points as far as internal-only status goes are:
-
Start tags of either
<remark>or any element withcondition="future". When you see such start tags, an internal-only region begins or deepens. -
End tags of either
<remark>or any element withcondition="future". When you see such end tags, an internal-only region ends or becomes shallower. At this point, you have already seen all the element's descendants, an observation whose relevance will appear soon.
These significant points become the focus of our accumulator rules. The
<xsl:accumulator-rule> element supports an attribute named
phase. This attribute enables you to construct different
accumulator values based on whether the XSLT engine traversing the tree has first
reached the node before visiting its descendants or is revisiting the node after
visiting all its descendants. In this way, a node has two accumulator values, not
one, even if the node has no descendants. The values of phase are
"start" (default) and "end". The distinction is
exactly what we need for the accumulator in this example. Here are two
approaches:
-
The
internal-depthaccumulator records the depth of internal-only regions. For instance, this accumulator associates the integer value2with the text node having content "For next year, maybe", and the nonzero value indicates that this text node is internal-only. The text node having content "Additional content" is associated with the value1, which is also nonzero and indicates internal-only status. By contrast, the text node having content "Sample external content" is associated with the value0.Figure 5: Accumulator Declaration for Depth of Internal-Only Content
<xsl:accumulator name="internal-depth" as="xs:integer" initial-value="0"> <xsl:accumulator-rule phase="start" match="remark | *[@condition='future']"> <!-- Start: Increment depth --> <xsl:sequence select="$value + 1"/> </xsl:accumulator-rule> <xsl:accumulator-rule phase="end" match="remark | *[@condition='future']"> <!-- End: Decrement depth --> <xsl:sequence select="$value - 1"/> </xsl:accumulator-rule> </xsl:accumulator> -
The
internal-elemaccumulator behaves like a stack, recording sequences of internal-only element names (with the most recent at the beginning). For instance, this accumulator associates the sequence('remark', 'section')with the text node having content "For next year, maybe", and the nonempty value indicates that this text node is internal-only.Recording element names might seem like overkill, but it depends on the situation. The additional information beyond depth could be helpful for debugging, testing, or hypothetical downstream processing that depends on the specific reason why a node is internal-only.
Figure 6: Accumulator Declaration for Names of Internal-Only Elements
<xsl:accumulator name="internal-elem" as="xs:string*" initial-value="()"> <xsl:accumulator-rule phase="start" match="remark | *[@condition='future']"> <!-- Start: Push element name on head of stack --> <xsl:sequence select="(name(.), $value)"/> </xsl:accumulator-rule> <xsl:accumulator-rule phase="end" match="remark | *[@condition='future']"> <!-- End: Pop first item from stack --> <xsl:sequence select="tail($value)"/> </xsl:accumulator-rule> </xsl:accumulator>
Before/After Distinction in Accumulator Functions
So far, we have glossed over the mechanism for retrieving the accumulator value
associated with a particular node. XSLT 3.0 defines functions that return the value
that a specified accumulator associates with the context node. Just as accumulator
rules distinguish between the situations before and after the XSLT processor has
visited descendants when assigning accumulator values, the retrieval capabilities
distinguish when retrieving accumulator values. That is why XSLT 3.0 provides not
one accumulator function but two: accumulator-before and
accumulator-after. For instance, in the preceding section's
examples,
-
/section/remark/accumulator-before('internal-depth')returns1because thephase="start"rule has just incremented the accumulator value. -
/section/remark/accumulator-after('internal-depth')returns0because thephase="end"rule has just decremented the accumulator value. -
Both functions return the same value if the context node is
/section/para. Neither this element nor its descendants match any accumulator rule in the'internal-depth'accumulator declaration. As a result, inertia preserves the accumulator value while the processor visits this element, its descendants, and this element again. -
Both functions return the same value if the context node is a text node. A text node has no descendants, and text nodes do not match any accumulator rule in the
'internal-depth'accumulator declaration. Therefore, inertia preserves the accumulator value while the processor visits a given text node twice.
The before/after distinction in the two accumulator functions does not always correspond to start/end phases in accumulator rules; the point is how the context node and its descendants relate to the accumulator rules. For instance, the XSLT 3.0 specification includes the following accumulator example that counts words [XSLT].
Figure 7: Keep a Word Count, from XSLT Specification
<xsl:accumulator name="word-count"
as="xs:integer"
initial-value="0">
<xsl:accumulator-rule match="text()"
select="$value + count(tokenize(.))"/>
</xsl:accumulator>If such an accumulator operates on an HTML document,
/html/accumulator-before('word-count') returns zero because no text
nodes have been visited yet. By contrast,
/html/accumulator-after('word-count') returns the total number of
words in the HTML document because all text nodes containing words have been
visited.
Preventing Bugs
From the last section, you know that an accumulator associates data with tree nodes before and after visiting their descendants, and it holds the last data value until the next visit to a node that matches an accumulator rule. Now, let's start to look at ways you can use accumulators productively and avoid mistakes. It's better to prevent a mistake than to discover, diagnose, and fix it. This section contains tips for preventing accumulator-related bugs.
When Not to Use an Accumulator
One potential mistake that's best to detect as early as possible is trying to use an accumulator when it's not suitable for the situation. For example:
-
Inspired by an accumulator's counting behavior, you might try to make an accumulator count how many times your XSLT code processes a certain XML element. However, that would be a design mistake, because the tree traversal for accumulator computations is not the same as how templates or functions access the tree. An accumulator can say, "This is the third title I've seen so far in this document" but not, "This is the third time I've seen this title so far during processing: once when creating the table of contents, once when rendering the heading, and once when rendering a hyperlink that points here."
-
Suppose the original document order is not that significant in an XML document you are processing, such as when the XSLT sorts subsections of a topic. An accumulator might be a good fit either for a task unaffected by the sorting or if the accumulator operates on nodes of an already-sorted tree. On the other hand, you might decide that storing a sorted tree would add too much complexity and a non-accumulator solution would be better.
-
Suppose you are processing documents that can refer to other documents, and you need to track the document URIs as you follow the references. Inspired by mentions of accumulators that implement stacks, you might try to use an accumulator to track the URIs. However, if "following" the references means applying XSLT to the referenced documents using the XPath
transformfunction, an accumulator might not be a suitable solution. I am not aware of a capability for passing an accumulator and its values across an XSLT stylesheet boundary via thetransformfunction. The case where I saw this situation implemented the stack using a tunnel parameter instead of an accumulator.This situation contrasts with one that came up on an XSL mailing list recently, where a user wanted to accumulate data across topics referenced by a DITA map [M]. This situation used
docrather thantransformto access the referenced documents, and an accumulator worked fine because it was crossing a tree boundary, not an XSLT stylesheet boundary. -
An accumulator might not be a good substitute for a user-defined function on attribute nodes, because accumulators do not associate values with attribute nodes. If you consider the desired behavior in terms of element nodes, you can judge whether an accumulator that matches element nodes and computes its value related to an element's attributes has any advantages in clarity or functionality compared to an ordinary function.
Avoiding Coding Mistakes
Suppose you've determined that an accumulator is a suitable solution to your problem, and you're ready to start coding it. The following list can help you avoid potential coding errors:
-
As you think about the match patterns for which you will create accumulator rules, think about how the patterns might occur in the actual trees you need to process. Plan for potential interactions among patterns:
-
Avoid ambiguous rule matches. If a node matches multiple patterns, using separate accumulator rules for them will lead to a warning about the ambiguous rule match, and the accumulator rule that the processor applies may or may not be what you want. Avoiding ambiguous rule matches is why the
'internal-depth'example in Figure 5 uses the same accumulator rule for both<remark>elements and elements having thecondition="future"attribute.Note
Accumulator rules do not support a
priorityattribute, as template rules do. -
Consider nesting. If a node can match a pattern in a nested arrangement, think through the possibilities and eventually try them first-hand, to make sure your design is sound. In the
'internal-depth'example, the potential for nested internal-only patterns is why the accumulator computes the numeric depth instead of returning a Boolean value (i.e., a node is or is not internal-only).
-
-
If your design requires resetting the accumulator value in some way or shedding data that was accumulated earlier in the traversal, remember to implement the reset and do it correctly for your situation. For a resettable counter, consider whether you should reset the value to zero or decrement it by one. For a stack, consider whether you should empty the stack or remove one value from the beginning or the end.
-
Make sure your accumulator is applicable to the tree where you want to attach the data. Details of your situation determine whether the applicability comes for free, and the rules are in the Applicability of Accumulators section of the XSLT 3.0 specification. Sometimes, you need to add a
use-accumulatorsattribute that lists either accumulator names or the token#all. For example,<xsl:mode use-accumulators="#all"/>makes all accumulators applicable to documents containing nodes in the initial match selection.
Debugging Techniques
Suppose you've created an accumulator and you need some visibility into its behavior. Maybe you want to check that your in-progress work is on the right track. Maybe you have all the pieces in place, but something doesn't work as expected.
Choose a tree that you'd like to have the accumulator associate data with, such as a sample document or a tree whose transformation exhibits a problem. While accumulators can operate on trees that aren't rooted at document nodes, some debugging techniques are more straightforward if the tree is captured in an XML file.
This section describes the following approaches to debugging or viewing values of your accumulator:
XPath Watch in the Oxygen Debugger
In Oxygen XML Editor, the XSLT debugger provides visibility into many aspects of
an evolving transformation, including the execution stack and variables. This
debugger can show you accumulator values, too (at least for non-streaming
transformations). After you select XML and XSLT files for the debugging
configuration, place one or more breakpoints at templates, functions, their
contents, or lines in the source document. Remember, though, that the XSLT
processor's tree traversal aimed at computing accumulator values is not the same as
the process of evaluating templates and functions. Placing an Oxygen debugger
breakpoint at or within <xsl:accumulator> is not particularly useful.[1]
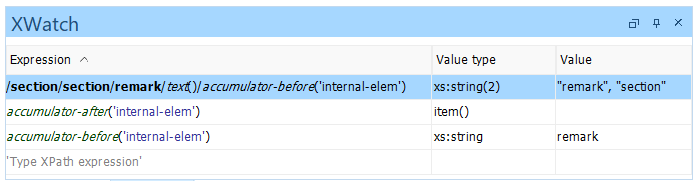
What is useful for viewing accumulator values is the XPath Watch (XWatch) view in the Oxygen debugger [XW]. Here are two approaches you can use separately or together:
-
Watch the expressions
accumulator-before(...)andaccumulator-after(...), providing the name of your accumulator as the input argument to these functions. When the transformation is paused at a breakpoint, the XWatch pane shows the accumulator values at the context node. You can also select a row in the XWatch pane and view the value in a tree format, in the Nodes/Values Set pane. As you step through the transformation and the context node changes, the XWatch pane changes the values it shows because the accumulator functions operate at the context node. -
Watch an expression that explicitly sets the context node, such as
//body/h1[1]/accumulator-before('word-count'). This approach enables you to zero in on any node of interest, and it works at any XSLT breakpoint that the execution reaches, even if the node of interest hasn't yet become the context node for any template. To see multiple nodes' accumulator values together, you can use multiple rows in the XWatch view or specify a path that yields a node sequence of any length (e.g., remove the[1]predicate in the last expression).
The next screen captures illustrate panes of the Oxygen debugger when paused at an
XSLT breakpoint. At this breakpoint, the first <remark> element in
the XML source document is the context node. In the XWatch pane, the first row shows
the accumulator's value at the subsection remark's text content. The second and
third rows shows the accumulator's values at the context node (first
<remark> element) after and before, respectively, the
accumulator's document traversal has reached the context node's descendants.
Figure 8: XSLT Stylesheet with Breakpoint

Figure 9: XML Source Document
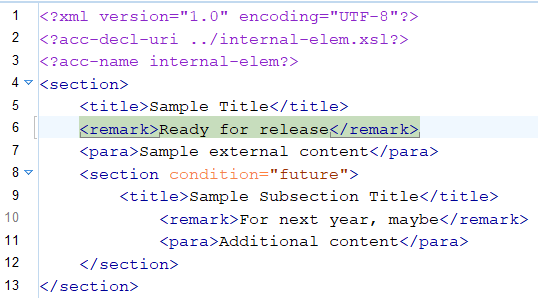
Figure 10: XWatch Pane
Trace from Saxon (PE or EE)
If you have a license for Saxon-PE or Saxon-EE, you can configure your accumulator
to emit trace messages during the transformation, whenever the value changes. Each
message includes the accumulator name, the word BEFORE or AFTER, an XPath expression
for the node that matched the accumulator rule, and the new value of the accumulator
for that node. To configure your code in this way, modify the
<xsl:accumulator> element by setting the
saxon:trace attribute to the value 1,
true, or yes [S]. Remember to
declare the namespace of this attribute,
xmlns:saxon="http://saxon.sf.net/". (Consider including the prefix
in the value of an exclude-result-prefixes attribute of
<xsl:stylesheet>.)
Figure 11: Saxon Trace Configuration
<xsl:accumulator name="..." initial-value="..."
saxon:trace="yes" xmlns:saxon="http://saxon.sf.net/">
...
</xsl:accumulator>Sample output looks like the following.
Figure 12: Sample of Saxon Trace Messages
internal-elem BEFORE /section/remark[1]: "remark"
internal-elem AFTER /section/remark[1]: ()
internal-elem BEFORE /section/section[1]: "section"
internal-elem BEFORE /section/section[1]/remark[1]: ("remark", "section")
internal-elem AFTER /section/section[1]/remark[1]: "section"
internal-elem AFTER /section/section[1]: ()Report of Accumulator Values
An option similar to trace messages is to create a report of accumulator values
associated with a tree. The xslt-accumulator-tools repository on
GitHub, which I created to complement this paper, includes an accumulator report
generator named acc-reporter.xsl [G]. The rest of
this section is about this report generator, although you can always write your own
XSLT code to produce a custom-designed report.
The premise underlying acc-reporter.xsl is that you have some
accumulator declaration in an XSLT file, have one or more documents in XML files,
and want to see the values the accumulator associates with the nodes in the
documents.
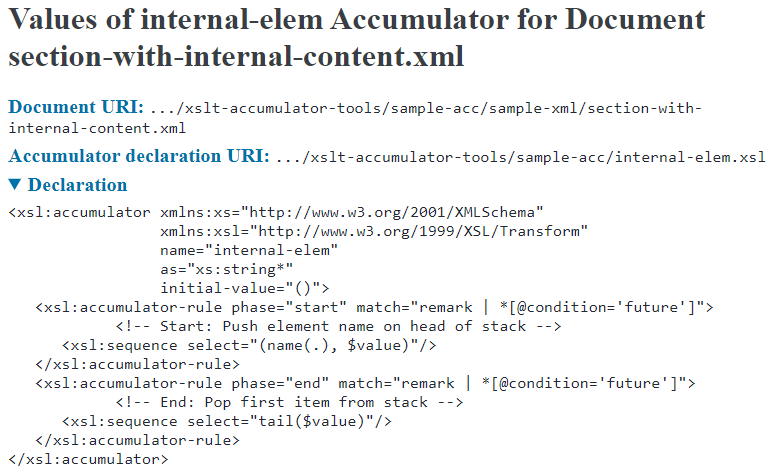
For a given accumulator and XML document, this tool produces an HTML report having two sections. The first section lists the following background information, for traceability:
-
URI of the XML document.
-
URI of the XSLT file containing the accumulator declaration.
-
Code in the
<xsl:accumulator>element. Recording this code in the HTML report can be useful if you iteratively generate reports while modifying your accumulator definition in the XSLT file.
Figure 13: Sample Top Section
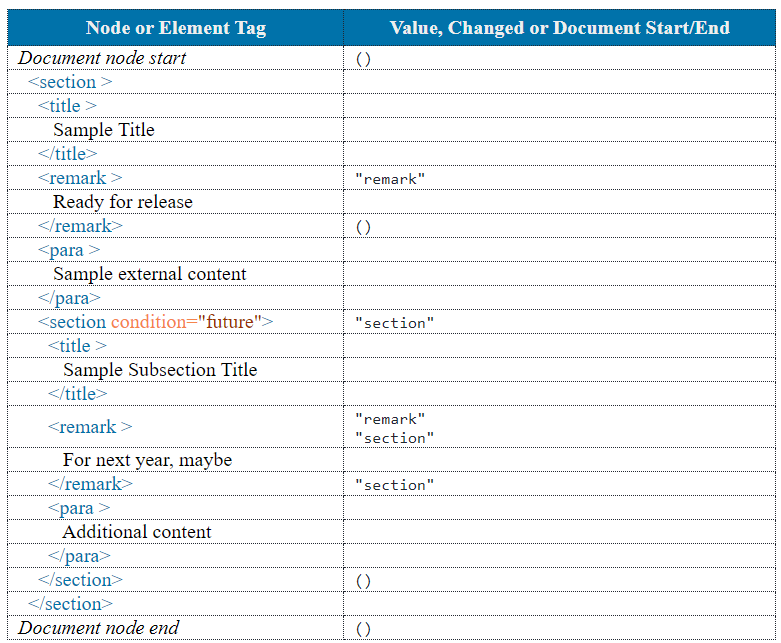
The next section is a two-column table, where:
-
The first column shows element tags and non-element nodes from the XML document. For elements, separate listings for start and end tags distinguish between the accumulator's values before and after visiting the element's descendants. Global parameters in
acc-reporter.xslenable you to control whether the report suppresses whitespace-only text nodes and at what length the report truncates content of text and comment nodes. Truncation is meant to help you focus on the nodes and values, not voluminous text content that would require you to scroll a lot. -
The second column shows associated accumulator values. To reduce clutter, the report populates this column only for the document node's values and wherever an accumulator changes its value.
Figure 14: Sample Table of Accumulator Values
For specific instructions on generating accumulator reports using a system command
or an Oxygen transformation scenario, see the xslt-accumulator-tools
GitHub repository. [G]
XSLT Messages
The <xsl:message> instruction is a common debugging approach to
get information about a transformation running outside a debugger environment. If
you want the accumulator computations themselves to produce messages, follow these
guidelines:
-
Insert
<xsl:message>as a child or other descendant of<xsl:accumulator-rule>, not as a child of<xsl:accumulator>. -
Where
<xsl:message>is inside<xsl:accumulator-rule>, the latter should contain a sequence constructor, not aselectattribute. If you wrote the accumulator rule with aselectattribute and want to insert<xsl:message>, modify the rule as in the following example.Figure 15: Original Accumulator Rule
<xsl:accumulator-rule match="*" select="newvalue"/>
Figure 16: Modified Accumulator Rule to Support XSLT Message
<xsl:accumulator-rule match="*"> <xsl:sequence select="newvalue"/> <xsl:message expand-text="1"> At {name(.)} element, old accumulator value is {$value} </xsl:message> </xsl:accumulator-rule> -
In your message content, don't call the
accumulator-beforeoraccumulator-afterfunctions to refer to the same accumulator whose declaration contains the message. If you try that, you will get an error message that says the accumulator requires access to its own value.You can, however, use
accumulator-beforeoraccumulator-afterfunctions to refer to a different accumulator. Doing so is helpful if you split a complicated computation across multiple accumulators that build on each other in a non-circular way. -
You can use the special variable named
$valuein the message content. This variable stores the value of the accumulator before evaluating the content of this accumulator rule.
As usual, you can insert <xsl:message> inside templates and
functions. Here are some tips for reporting on accumulator values in messages within
templates and functions:
-
In your message content, you can call the
accumulator-beforeandaccumulator-afterfunctions to refer to an applicable accumulator. -
In your message content, don't use the special
$valuevariable, which is accessible only within<xsl:accumulator-rule>. -
The
<xsl:message>instruction doesn't have to be in a template rule for the kind of node whose associated accumulator value you want to report. You can insert the message anywhere convenient that (a) will be reached during the transformation and (b) can assume your node of interest as the context node. (Requirement (b) is relevant for stream processing.) Within your message, you can change the context node to your node of interest and then call the accumulator function.The ability to change context at will is convenient if you want to report accumulator values for multiple tree nodes and prefer to consolidate temporary debugging code in as few locations in your XSLT stylesheet as possible.
The next code sample illustrates changing the context node and calling accumulator functions, in a non-streaming application.
Figure 17: Sample Template with Accumulator Values in Message
<xsl:template match="/" expand-text="1">
<!-- Output accumulator values in message text -->
<xsl:for-each select="//body/h1">
<xsl:message>Before descendants of h1 #{position()}: {
accumulator-before('word-count')
}
</xsl:message>
<xsl:message>After descendants of h1 #{position()}: {
accumulator-after('word-count')
}
</xsl:message>
</xsl:for-each>
<xsl:message>At end of html element: {
/html/accumulator-after('word-count')
}
</xsl:message>
<!-- Other code in this template... -->
</xsl:template>Where you place the <xsl:message> instructions can depend on your
preferences as well as your immediate goal or context in the development process.
For instance, if you have just written an accumulator declaration and want to check
that the rules are correct before using accumulator values somewhere else in the
stylesheet, you might favor messages within the accumulator rules because that's
where your attention is. On the other hand, if you are investigating a bug that
involves a particular template or function, that may be a natural place for messages
about accumulator values, variable values, and other data to aid your
investigation.
Testing Techniques
Debugger tools, trace messages, reports, and <xsl:message> outputs
serve useful purposes that are typically transient purposes. In production, you don't
run your transformation in a debugger and you are likely to suppress or remove code
that
makes logs unwieldy. There's nothing wrong with the transience of the debugging
techniques described earlier; you solve your immediate problem, remove extraneous
logging, and move on. At the same time, you might gain value from automated tests
that
persist even after you have finished checking an accumulator rule interactively or
fixing a bug. This section illustrates ways to test behavior of some accumulators
using
XSpec [XS], which is an open-source software product for testing XSLT,
XQuery, and Schematron code. This section assumes prior familiarity with XSpec.
Motivations for Testing Accumulators
First, let's discuss why you might want to test an accumulator in an automated way. In general, automated testing can help you maintain your code's correct behavior as you add features, fix bugs, and refactor code. The time you invest in creating automated tests pays dividends when you can change XSLT code quickly with confidence that you haven't broken anything (or that you've given the breakage careful consideration and documented it in release notes for end users, if appropriate). Unless a piece of XSLT code is trivial or has a very short life span from the start of development to the end of usage, you should consider whether and how it should have automated tests. If you're already familiar with XSpec tests for templates and functions, you might still wonder why an accumulator deserves special testing attention. Consider whether these reasons pertain to any of your accumulator code:
-
One way to begin an investigation of a bug is to write an XSpec test that reproduces the bug. Running the test repeatedly as you modify the code or insert debugging messages can help you diagnose and fix the bug efficiently. After you have fixed the bug, you might as well keep the test to guard against recurrences of the bug. This bug-fixing workflow can apply to code whether or not it involves an accumulator. When you suspect the cause of an XSLT bug is in an accumulator declaration, you might find it handy to know how to make a test that focuses on that declaration.
-
Some accumulators are complicated. Maybe you have one accumulator whose computations depend on another accumulator. Maybe your accumulator operates on XML documents that can exhibit a variety of pattern combinations, including important edge cases whose support must be maintained. Greater complexity in the accumulator is likely to provide a greater return on your test writing investment.
-
If the templates and functions that reference your accumulator are large or complicated themselves, you might like the modularity of testing the accumulator in isolation from them.
XSpec Test Importing XSLT Under Test
By default, an XSpec test of XSLT code gets compiled into a stylesheet that
imports the XSLT code you are testing. Because the import operation mingles your
XSLT code with the compiled test logic, the testing logic can access your XSLT
accumulators. If your XSpec file uses this default import mechanism (i.e., you are
not using the nondefault run-as="external" testing mechanics due to one
of the use cases described in [E]), you can use the examples in
this section.
Compared to the example in XSpec Test Running XSLT as External Transformation, the examples in this section are more concise and do not require you to augment your XSLT stylesheet by importing wrapper functions.
Dedicated Test Scenario
The first example illustrates an XSpec test file that focuses specifically on testing an XSLT accumulator.
Figure 18: Sample Dedicated XSpec Test for Accumulator, with run-as="import"
<x:description xmlns:x="http://www.jenitennison.com/xslt/xspec"
xmlns:myv="my-xspec-variables"
stylesheet="../internal-elem.xsl"
run-as="import">
<x:scenario label="Values of internal-elem accumulator">
<x:variable name="myv:tree"
href="../sample-xml/section-with-internal-content.xml"
select="/"/>
<!-- x:call satisfies XSpec compiler -->
<x:call function="true"/>
<x:expect
label="At start of subsection remark, 2 element names in stack"
test="$myv:tree/section/section/remark/accumulator-before('internal-elem')"
select="('remark', 'section')"/>
<x:expect
label="At end of subsection remark, 1 element name in stack"
test="$myv:tree/section/section/remark/accumulator-after('internal-elem')"
select="('section')"/>
<!--
Use of exactly-one() ensures that if $myv:tree yields an empty sequence
by mistake, you'll get an error instead of having the accumulator function
return empty for the wrong reason.
-->
<x:expect
label="At end of document, stack is empty"
test="exactly-one($myv:tree)/accumulator-after('internal-elem')"
select="()"/>
<!-- Variation: Boolean @test and no @select -->
<x:expect
label="At end of document, stack is empty"
test="empty(exactly-one($myv:tree)/accumulator-after('internal-elem'))"/>
</x:scenario>
</x:description>Relevant points of this sample test include the following:
-
At the top of the XSpec file, the
<x:description>element includesrun-as="import". (This setting is equivalent to omitting therun-asattribute, because"import"is the default value.) Making the compiled XSpec test import your XSLT stylesheet makes the accumulator available to your<x:expect>assertions.Note
If you specify
run-as="external", then this accumulator testing technique will not work. See XSpec Test Running XSLT as External Transformation for an alternate testing technique. For more information about external transformations in XSpec, see [E]. -
The scenario defines a tree with which you'd like the accumulator to associate data. It is convenient, though not strictly necessary, to store the tree in an XSpec variable. The name of the variable is not critical, nor is the choice to read it from a separate XML file.
<x:variable name="myv:tree" href="../sample-xml/section-with-internal-content.xml" select="/"/> -
The scenario calls a function using
<x:call>, to avoid an error from the XSpec compiler. The specific function (in this case, the standardtruefunction in XPath) and its return value are not important in this scenario. -
The scenario has
<x:expect>elements whose purpose is to check that the accumulator has the expected values at certain nodes of the tree. The label can be whatever descriptive text you want. Thetestattribute establishes a context node and calls eitheraccumulator-beforeoraccumulator-after. Theselectattribute provides the expected value of the specified accumulator function at that context node.<x:expect label="At start of subsection remark, 2 element names in stack" test="$myv:tree/section/section/remark/accumulator-before('internal-elem')" select="('remark', 'section')"/>If you prefer, you can omit the
selectattribute and write a Boolean expression in thetestattribute, as in the following variation on the check for an empty sequence.<x:expect label="At end of document, stack is empty" test="empty(exactly-one($myv:tree)/accumulator-after('internal-elem'))"/>If the expected accumulator value is a node, you can provide it as a child of the
<x:expect>element instead of using theselectattribute.If the expected accumulator value is an empty sequence, you should make sure the accumulator function is operating on a nonempty context node so the function does not return an empty sequence for the wrong reason. By applying the
exactly-oneorone-or-morefunction to the node(s) at which you want to call an accumulator function, you can rule out an empty context node.
Notice that a single scenario can check the accumulator values at multiple
nodes of the tree. You can even have a single scenario that checks accumulator
values on multiple trees (such as $myv:tree and
$myv:tree2 variables), though you might find it clearer to have
a separate scenario for each tree.
Accumulator Expectations Within Scenarios Serving Other Purposes
As an alternative to creating dedicated test scenarios for accumulators, you can check accumulator values in test scenarios that primarily serve other purposes. You might choose this approach for any of these reasons:
-
You find it natural or more maintainable to check the accumulator values near where you test the templates or functions that call
accumulator-beforeoraccumulator-after. -
The way you organize your XSpec scenarios is not meant to align with XSLT code units like templates and functions.
-
Your bug-investigation process began with some existing scenario, and you see no urgency in refactoring the XSpec test code later.
-
You want to avoid the unintuitive
<x:call function="true"/>element in the prior example, Sample Dedicated XSpec Test for Accumulator, with run-as="import".
The next example illustrates a test for a template rule that also includes checking some expected values of an accumulator.
Figure 19: Sample XSpec Test for Template Rule and Accumulator, with run-as="import"
<x:scenario label="Tests for template rule for remark element">
<x:variable name="myv:tree"
href="../sample-xml/section-with-internal-content.xml"
select="/"/>
<!-- Check result for 1st remark in document -->
<x:context select="($myv:tree//remark)[1]"/>
<x:expect
label="Result of the template rule contains text content"
test="contains($x:result, 'Ready for release')"/>
<!-- Checks for accumulator values do not rely on $x:result or the
template rule code but can be included in this scenario if desired. -->
<x:expect
label="Accumulator: At 1st remark, 1 element name in stack"
test="($myv:tree//remark)[1]/accumulator-before('internal-elem')"
select="('remark')"/>
<x:expect
label="Accumulator: At subsection remark, 2 element names in stack"
test="$myv:tree/section/section/remark/accumulator-before('internal-elem')"
select="('remark', 'section')"/>
</x:scenario>XSpec Test Running XSLT as External Transformation
When your XSpec test uses the nondefault run-as="external" option,
the compiled test logic invokes the XSLT code you are testing as an external
transformation. This mechanism has benefits, but a drawback is that your XSLT
accumulators are not directly accessible in <x:expect> elements,
while the standard accumulator functions are not directly accessible in
<x:call>. You can still test the accumulators, however, and this
section illustrates one design. The design works in the default
run-as="import" situation, too, so you retain the flexibility to
change run-as later without having to rewrite tests.
At a high level, the arrangement has these parts:
-
An XSLT module that defines thin wrappers around the standard
accumulator-beforeandaccumulator-afterfunctions. -
In your XSLT stylesheet, an instruction that imports the module containing wrapper functions.
-
In your XSpec test file, a dedicated scenario (or descendant scenario of any depth) for each expected value you want to check for your accumulator. Each scenario uses
<x:call>to call a wrapper function to retrieve an accumulator value.
Items 1 and 2 make the accumulator functions (indirectly) accessible during XSpec testing, while item 3 makes your accumulator accessible. Item 3 is less concise than the examples in XSpec Test Importing XSLT Under Test, but the underlying capabilities are analogous.
Note
If you prefer not to modify your production XSLT code, an alternative is to
introduce a separate "test harness" XSLT file that includes your production XSLT
code and imports the module containing wrapper functions. In XSpec, point the
x:description/@stylesheet attribute to the test harness rather
than your production XSLT code.
Figure 20: Architecture of XSpec and XSLT

Figure 21: Wrapper Functions Around Standard Accumulator Functions
<xsl:transform xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:xs="http://www.w3.org/2001/XMLSchema"
xmlns:at="http://github.com/galtm/xslt-accumulator-tools"
xmlns:fn="http://www.w3.org/2005/xpath-functions"
exclude-result-prefixes="#all"
version="3.0">
<!-- Wrap fn:accumulator-before and fn:accumulator-after
so they can be accessed from an XSpec external transformation
using x:call. -->
<xsl:function name="at:accumulator-before" visibility="public">
<xsl:param name="context" as="node()?"/>
<xsl:param name="name" as="xs:string"/>
<!-- If data type of $context is "node()" then XSpec with run-as="import"
cannot catch an empty context. So, allow "node?" and check for the
empty case here. -->
<xsl:if test="empty($context)">
<xsl:sequence select="error(xs:QName('at:XPTY0004'),
'An empty sequence is not allowed as the context of accumulator-before()')"/>
</xsl:if>
<xsl:sequence select="$context/fn:accumulator-before($name)"/>
</xsl:function>
<xsl:function name="at:accumulator-after" visibility="public">
<xsl:param name="context" as="node()?"/>
<xsl:param name="name" as="xs:string"/>
<xsl:if test="empty($context)">
<xsl:sequence select="error(xs:QName('at:XPTY0004'),
'An empty sequence is not allowed as the context of accumulator-before()')"/>
</xsl:if>
<xsl:sequence select="$context/fn:accumulator-after($name)"/>
</xsl:function>
</xsl:transform>Figure 22: Importing Wrapper Functions in XSLT Code Under Test
Include the following import instruction in the XSLT stylesheet that XSpec
points to, using an href path that fits your directory
arrangement.
<!-- Wrapper functions make accumulator functions available
to an external transformation in XSpec -->
<xsl:import href=".../xslt-accumulator-tools/accumulator-test-tools.xsl"/>Figure 23: Sample XSpec Test for Accumulator, with run-as="external"
<x:description xmlns:x="http://www.jenitennison.com/xslt/xspec"
xmlns:myv="my-xspec-variables"
xmlns:at="http://github.com/galtm/xslt-accumulator-tools"
stylesheet="../internal-elem-wrapperfcn.xsl"
run-as="external">
<x:scenario label="Values of internal-elem accumulator">
<x:variable name="myv:tree"
href="../sample-xml/section-with-internal-content.xml"
select="/"/>
<x:scenario label="Start of subsection remark">
<x:call function="at:accumulator-before">
<x:param select="$myv:tree/section/section/remark"/>
<x:param select="'internal-elem'"/>
</x:call>
<x:expect label="2 element names in stack"
select="('remark', 'section')"/>
</x:scenario>
<x:scenario label="End of subsection remark">
<x:call function="at:accumulator-after">
<x:param select="$myv:tree/section/section/remark"/>
<x:param select="'internal-elem'"/>
</x:call>
<x:expect label="1 element name in stack"
select="('section')"/>
</x:scenario>
<x:scenario label="End of document">
<x:call function="at:accumulator-after">
<x:param select="$myv:tree"/>
<x:param select="'internal-elem'"/>
</x:call>
<x:expect label="Empty" select="()"/>
</x:scenario>
</x:scenario>
</x:description>Relevant points of this sample test include the following:
-
As in the examples in XSpec Test Importing XSLT Under Test, the scenario defines a tree with which you'd like the accumulator to associate data.
<x:variable name="myv:tree" href="../sample-xml/section-with-internal-content.xml" select="/"/> -
Each lowest-level scenario uses
<x:call>to call a wrapper function,at:accumulator-beforeorat:accumulator-after. The first function parameter is the context node whose accumulator value you want to retrieve, and the second parameter is the name of the accumulator. -
The scenario has an
<x:expect>element that checks the output of the specified accumulator function. Theselectattribute provides the expected value of the accumulator function at that context node. XSpec compares this expected value with the result of the<x:call>function call.<x:expect label="2 internal-only elements in stack" select="('remark', 'section')"/>If you prefer, you can omit the
selectattribute and write a Boolean expression in thetestattribute, as in the following variation on the check for an empty sequence.<x:expect label="Empty" test="empty($x:result)"/>
If the expected accumulator value is a node, you can provide it as content of the
<x:expect>element instead of using theselectattribute.
Conclusion
After reviewing distinctive characteristics of XSLT accumulators and looking at some examples, we explored several debugging and testing techniques for accumulators. The next table highlights some points of comparison among the techniques discussed. Notice that the short-term use cases vary, so it's helpful to be familiar with multiple techniques instead of only one.
Table I
Comparison of Debugging and Testing Techniques
| Approach | Additional Software Needed | Basic Procedure | Short-Term Use Case | Long-Term Benefit? |
|---|---|---|---|---|
| Oxygen debugger | Oxygen (Syncro Soft) | Configure debugger, breakpoints, and XPath watch expressions; run transformation interactively; analyze interim states | Explore transformation behavior in various ways, including viewing selected values of accumulator | No |
| Trace | Saxon PE or EE (Saxonica) | Set saxon:trace attribute; run transformation; analyze log
|
View values for entire tree | Maybe, if baseline logs are kept for later comparison |
| Report | XSLT Accumulator Tools, from GitHub | Configure parameters; run transformation; analyze report | View values for entire tree | Maybe, if baseline reports are kept for later comparison |
| XSLT messages | None | Insert message instructions in accumulator rules, templates, or functions; run transformation; analyze log | View selected values or identify which rules are being matched | Maybe |
| XSpec tests | XSpec, from GitHub | Write test scenarios describing expected behavior; run test; check results and analyze failures, if any | View and verify selected values | Yes |
Having more visibility into the data an XSLT accumulator associates with a tree should help XSLT/XSpec developers work with accumulators more successfully throughout the software development life cycle.
References
[E] "External Transformations," XSpec documentation, https://github.com/xspec/xspec/wiki/External-Transformation
[G] Galtman, Amanda, XSLT Accumulator Tools, https://github.com/galtm/xslt-accumulator-tools
[M] "Making a lookup structure from multiple documents," XSL-List – Open Forum on XSL, Mulberry Technologies, June 12, 2023, https://www.biglist.com/lists/lists.mulberrytech.com/xsl-list/archives/202306/msg00015.html
[S] "saxon:trace," Saxon Developer Guide, https://www.saxonica.com/html/documentation12/extensions/attributes/trace.html
[XSLT] XSL Transformations (XSLT) Version 3.0, https://www.w3.org/TR/xslt-30/
[XS] XSpec, https://github.com/xspec/xspec
[XW] "XPath Watch (XWatch) View," Oxygen XML Editor User Manual, https://www.oxygenxml.com/doc/versions/25.1/ug-editor/topics/debug-xwatch-view.html
[1] Also not useful is calling the accumulator-before or
accumulator-after function within the XPath 3.1 field in the Oxygen toolbar in the non-debugging
perspective. You'll get an error message about the function not being found,
because it is available only within an XSLT transformation, not standalone
XPath expressions.