Courtney, Joseph Michael, and Michael Robert Gryk. “Pulse, Parse, and Ponder: Using Invisible XML to Dissect a Scientific Domain Specific
Language.” Presented at Balisage: The Markup Conference 2024, Washington, DC, July 29 - August 2, 2024. In Proceedings of Balisage: The Markup Conference 2024. Balisage Series on Markup Technologies, vol. 29 (2024). https://doi.org/10.4242/BalisageVol29.Courtney01.
Balisage: The Markup Conference 2024 July 29 - August 2, 2024
Balisage Paper: Pulse, Parse, and Ponder
Using Invisible XML to Dissect a Scientific Domain Specific Language
Joseph Michael Courtney
Postdoctoral Fellow
Department of Molecular Biology and Biophysics, UCONN Health (US)
Dr. Michael R. Gryk is Associate Professor of Molecular Biology and Biophysics
at UCONN Health. At UCONN, Michael co-leads a technical research and discovery
component of the NMRbox BTRR Center, the mission of which is to foster the
computational reproducibility and scientific data re-use of bioNMR data. Michael
is also the associate director of the BioMagResBank, the international
repository for bioNMR research data. He is also a doctoral student at the School
of Information Sciences at the University of Illinois, Urbana-Champaign, where
his broad research interests are in provenance, workflows, digital curation and
preservation, reproducibility, and scientific data re-use. Michael is also a
participant of the W3C Invisible Markup group.
This paper explores the application of Invisible XML (iXML) to parse the Bruker
Pulse Programming Language, a domain specific language for controlling Nuclear
Magnetic Resonance (NMR) spectrometers. Making the specialized file formats and
programming languages used in many scientific fields more accessible and
interpretable could help to improve scientific reproducibility and utility. The
development of a grammar for Bruker pulse code, simultaneously facilitates easier
and more automated comparison and analysis of NMR experiments and serves as a test
bed for the relatively young iXML approach to parsing. We discuss the challenges
faced and solutions developed for applying iXML to this problem.
Nuclear Magnetic Resonance (NMR) spectroscopy is a powerful analytical technique that
capitalizes on the magnetic properties of certain atomic nuclei Cavanagh, et al, 1996.
At its core, NMR involves placing a material sample in a strong external magnetic
field,
exciting it with radio-frequency (RF) pulses, and detecting the resulting signal as
the
nuclei in the material relax. This phenomenon is the basis for the diagnostic technique
of Magnetic Resonance Imaging (MRI) which is a useful complement to X-ray devices,
as
MRI has good contrast for soft tissues.
A typical NMR (or MRI) experiment involves repeatedly exciting the nuclei in the
sample with a complex sequence of tens to hundreds of pulses at multiple frequencies.
Each time the so-called pulse sequence is applied to the sample (called a “scan”),
it is
done with slightly different parameters, such as durations of delays and the lengths,
powers, and phases of pulses. By analyzing how the resulting signals vary with those
parameters, a scientist can determine information about the chemical bonding and spatial
organization of the molecules in the samples.
The design and description of those pulse sequences is very complex; enumeration of
the thousands to millions of parameter values for each experiment would be prohibitively
costly in time and effort. To facilitate pulse sequence design and specification,
several custom programming languages have been devised.
Pulse programs act as both a description of an experiment procedure and, when combined
with a parameter file for a particular execution, a proxy record of the exact sequence
of
pulses and data measurements that produced a particular a data file. Currently the
most
common language used for writing these pulse programs is the Bruker[1] pulse programming
language, which has been developed over several decades to support the operation of
Bruker-manufactured NMR spectrometers.
A standardized, structured representation of pulse code would enable new capabilities
and make others substantially faster. Currently, ensuring consistency between pulse
sequences described in scientific publications and their practical execution on
spectrometers necessitates substantial expertise. Experts are required to meticulously
compare textual descriptions with the actual pulse code to verify that the experiment
functions as expected. This task is inherently prone to inaccuracies and is a
considerable demand on time. Processing pulse code into structured data that can then
be
analyzed and transformed in a uniform manner would enable automatic comparison of
different versions of an experiment, conversion of pulse code for use with experiment
simulators, automatic determination of reasonable data processing parameters, annotation
of the data for each scan with the exact RF that produced it, and could be the first
step towards more efficient and partially automated authoring of pulse code.
To perform the parsing of Bruker pulse code, we chose to use Invisible XML Pemberton, 2021. The Invisible XML (iXML) specification describes an extended
Backus-Naur Form (EBNF) syntax for specifying context-free grammars and specifies
how a
parameterized parser should take an input file and an input grammar and produce an
annotated parse tree in XML format. Notably, iXML parsers are single-pass and do not
perform lexical analysis before parsing. This approach has the advantage that the
complete specification for the language and the details of the parse tree output format
can be specified in a single file. However, it sacrifices the known advantages of
the
separation of lexical analysis and parsing that have been identified in compiler
construction.
An important detail of the iXML specification is its handling of ambiguity in parse
trees Tovey Walsh, 2023. Version 1.0 of the iXML specification requires
that compliant parsers report if the parse of an input file is ambiguous; however,
they
are not required to return all possible parse trees and the specification does not
specify how a single parse tree should be chosen from the possibilities. iXML compliant
parsers are insensitive to the order of production rules in a grammar, which is used
in
some parsers to implicitly define precedence. However, pragmas have been introduced
by
Hillman et al.Hillman, 2022 as a mechanism for
imparting extra information to the parser. These pragmas can be used to indicate
priorities among ambiguous parsing options, providing a nuanced control over the parsing
process; but, at present, pragmas are not standardized and are implementation-specific
Tovey Walsh, 2023.
In this work, we will detail the Bruker Pulse Programming language, our approach to
writing a grammar to parse it in iXML, and an assessment of iXML for use in this case.
The Bruker Pulse Programming Language
The development of the Bruker pulse programming language has spanned multiple
decades, several generations of hardware, and bears the marks of diverse and often
competing forces driving its evolution. As it exists today, it is composed of three
distinct sub-languages: the macro language, the relation language, and the core
language. Unfortunately, the implementation of the language is proprietary, and a
publicly-available specification does not exist. Furthermore, the differences
between versions are not well-documented. Bruker does provide a pulse programming
manual, but it is incomplete TopSpin Manual, 2022. Because of this,
development of a grammar was necessarily manual, based on example code, and
developed iteratively through trial and error.
The macro language is a subset of the C preprocessor language Stallman & Weinberg, 2016. It can be used to modify the source code of the program
before compilation. However, customary usage is limited to the definition of simple
replacement macros and conditional inclusion/exclusion. Because of that, in almost
all existing code, replacement macros can be treated like a kind of function call
and conditional inclusion can be treated as a standard conditional statement. As an
example, the following macro defined in the TopSpin 4 standard library file
De.incl, expands into a command sequence containing the two macro arguments.
#define ACQ_START1(phref1,phrec1) (de adc1 phrec1 syrec1) (1u 1u phref1:r):f1
The relation language is a mathematically focused subset of C, which retains the
basic arithmetic, logic, and comparison operators, along with if - else
and while statements for control flow Kernighan & Ritchie, 2002.
Relations are restricted to a single line, though this restriction is eased in
severity by the use of semicolons. When included in a pulse program, relations must
be enclosed in double-quotes. Relations can act both as a series of statements,
where their effects are restricted to modifying the values of parameters, or as
Boolean-valued expression that can be used as conditions in core language
conditional statements. Here is a typical relation used in the pulse program
"na_hpdino19", included with TopSpin 4, to calculate the duration of the delay
d0 from other relevant parameters. This type of relation is very common due
to the need to adjust alignment of various pulse sequence elements.
"d0=in0/2-larger(p2,p4)/2-p21*2/3.1416"
The core language is imperative and static-typed. Statements consist of a single
"principal" command followed by a series of zero or more "subordinate" commands.
Because it is common to require the pulses on different channels to move relative
to
each other, potentially switching execution order, parallel execution is built into
the language at a very low level. Multiple statements can be placed on one line and
can be grouped with parentheses. Within each set of parentheses, statements are
executed sequentially. If multiple parenthetical statements are placed on a single
line, they are executed in parallel, and the next line is not executed until the
group with the longest duration is finished. Newlines within parentheses are
ignored. The following line of core language code demonstrates a sequence of
commands. This line instructs the spectrometer to execute a delay of duration
D0, followed by a pulse with length P1 and phase PH1,
and then a delay of duration D0.
d0 p1 ph1 d0
A Bruker pulse program is organized into multiple sections, setup, experiment, and
phase cycle definitions. The following is annotated source code for the hCC.cp
pulse sequence included with TopSpin 4. Non-informative lines have been elided and
indicated with ellipses. Comments are indicated with semicolons.
#include <CHN_defs.incl>
#include <trigg.incl>
; declarations of user-defined commands
define delay ONTIME
define loopcounter T1evo
define pulse mixing
; relations evaluated at compile time
"mixing=(l1*TauR)"
"acqt0=-(p1*2/3.1416)-0.5u"
…
; macro language conditional inclusion
#ifdef CDC
"T1evo=larger(td1,cnst30)"
"d30=T1evo*(in30+2u)"
#endif
; end of setup section
Prepare, ze ; start of experiment section, line labeled as "Prepare"
; relations evaluated at run time
"d30=d30/2"
"ONTIME=aq+d0+d30+p15"
; conditional inclusion of pulse sequence commands
#ifndef lacq
#include <acq_prot.incl>
#include <ONTIME_prot.incl>
#endif
…
Start, 30m do:H ; Line is labeled "Start".
; with 30 millisecond delay, during which
; the "do" command is executed on channel H
d1
trigg
1u fq=0.0:H
; core-language conditional statement, with relation
; as the condition
if "l0>0" {
"d51=d0-2u"
}
(p3 pl2 ph1):H ; execute pulse of length P3, at power level PL2, with phase PH1, on channel H
(p15:sp41 ph2):C (p15:sp40 ph0):H ; simultaniously execute pulses on channels C and H
…
(mixing ph20 pl14):H ; execution of user-defined pulse "mixing"
(p1 pl1 ph4):C (0.5u pl12):H
0.5u cpds2:H
gosc ph31 ; cause the receiver to start measurement, with phase PH31, into a buffer
1m do:H
lo to Start times ns ; statement causing program execution to jump to the line labeld "Start"
; mc macro which writes buffered data to file #0, calculates changes to several parameters, and jumps execution to the line labeled "Start", among other actions.
30m mc #0 to Start
F1PH(calph(ph3, -90), caldel(d0, +in0) & caldel(d30, -in30) & calclc(l0, 1))
HaltAcqu, 1m
Exit ; end of experiment section
; start of phase cycle definitions
ph2 = {0}*8 {2}*8 ; phase cycle definition using condensed syntax
ph3 = 1 1 3 3 ; phase cycle definition using literal syntax
ph31= 2 0 1 3 0 2 3 1
0 2 3 1 2 0 1 3
The setup section is defined as everything before the line containing the "ze"
command and typically consists of include statements, macro definitions for common
patterns, custom command declarations, and relations to calculate parameters needed
for execution. Everything in the setup section is evaluated at compile time and any
values assigned to parameters in the setup relations override the values of those
parameters in the external parameter file.
The experiment section is a sequence of lines from the line containing "ze" to the
line containing "exit", inclusive. Lines can be labeled with a number or an
alphanumeric identifier. Inside the experiment section, core language code is
allowed. This section is used to describe the elements of the pulse sequence, how
their parameters change during the experiment, how different channels are
synchronized, and how signal is measured and stored in memory.
The phase cycle definitions at the end of the file are specified in a special
pattern syntax that makes it easier to express the repetitive and sometimes fractal
nature of the sequences.
Taken together, the Bruker programming language is a complex mixture of different
language constructs and patterns that presents a significant challenge for a grammar
author.
Approach to Grammar Construction
The lack of specification and incompleteness of available documentation meant that
the
grammar had to be inferred from example, but because automated inference of context-free
grammars form examples is impractical, the grammar had to be constructed through a
combination of intuition and trial and error. Initial rules were written according
to
guidelines in Bruker documentation, but unspecified behavior had to be determined
from
example code. To assist with development and testing, a corpus of test code was compiled
from multiple sources including published pulse programs, pulse programs uploaded
to the
BioMagResBank Ulrich, et al., 2008, code shared on the websites of NMR
researchers, and examples available on Github (https://github.com). Together this
constitutes approximately 350,000 lines of pulse code spread across about 2000 files.
Because a pulse program is both a procedure and an experimental record, it is
beneficial to capture as much information as possible in the parse tree by exploiting
knowledge about customary usage. However, when command types and other information
cannot be determined with a context-free grammar, it is still worthwhile to include
every token in the parse tree with as much specificity as possible. Our approach is
inspired by other work such as SuperC Gazillo & Grimm, 2012, which, among other
strategies, parses C preprocessor directives and C code together by adding rules that
capture patterns of customary usage of macros but includes base cases for code that
requires context-sensitivity or other information. This approach amounts to adding
special cases to the grammar that do not change the language it recognizes, but infers
additional semantic information which is included in the resulting parse tree.
Challenges Faced
Parsing Multiple Distinct Sublanguages
We encountered distinct challenges stemming from the interplay of the three
constituent sub-languages. The three languages exhibit significant overlap yet are
mutually incompatible and serve distinct functional roles within a pulse program.
This duality poses substantial challenges in the context of rule inference for
grammar development, especially when considering the constraints of iXML grammars.
For instance, all three languages have arithmetic and logical expressions along with
conditional statements. However, the three languages do not support the same sets
of
operators. For instance, relation expressions support bitwise and logical operators,
but in the core language the pipe character (“|”) and the caret character (“^”) are
reserved for turning on and off pins on a peripheral connector and cannot be used
with integers. For comparison, here are conditional statements in the macro
language,
As an extra complication, relations can be used as conditions in core language
conditional statements.
if "l0 % 2 == 1" {
...
}
Another area of difficulty is the ability to use arbitrary core statements and
expressions as arguments to macros. While there are a small number of customary uses
that can be identified, the lack of constraints on macro arguments makes inferring
grammatical rules constraining them difficult. For example, here are typical
invocations of the macros F1I and F1PH.
The arguments of F1I include core-language commands modified by arithmetic
operations. The invocation of F1PH demonstrates a construct for passing multiple
core commands in a single argument. Note that the ampersand is used here as a
separator, not as a logical or bitwise operator. Parsing macro and subroutine
invocations is further complicated by the existence of the following construct,
d12 fq=cnst18(bf ppm):f1
which uses a postfix parenthetical notation to adjust the interpretation of the
parameter cnst18. Also note that the fq=... does not set
the value of a parameter named "fq" but instead sets the frequency of the channel
specified by ":f1".
Context Sensitive Elements
Because iXML specifies a "scannerless" or single pass parsing procedure, it has no
distinct lexical analysis phase Hillman, et al., 2022. Lexical analysis is
typically used to distinguish between keywords and identifiers and process variable
declarations to associate their identifiers with types, among other tasks Grune & Jacobs, 2008. This separation into two phases allows simple
context-sensitivity by grouping characters into tokens annotated with additional
information that can then be parsed with a context-free grammar. However, applying
iXML in the most straight-forward way leaves type information for user-defined
variables inaccessible to the parser, and that structure cannot be encoded in the
output XML. For the Bruker pulse programming language, this causes difficulties with
determining the association of principal and subordinate commands and with the
disambiguation of reserved keywords, predefined commands, and user-defined commands.
Statement Structure Type Dependence
Commands in the core language are represented by bare identifiers and take no
explicit parameters. However, subordinate commands placed after a principal
command (in its shadow) will start execution at the same time as the principal
command and may affect its execution. For example, a pulse command (e.g.,
p1) is a principal command but pulse phase (e.g., ph2) and
power (e.g., pl3) commands are subordinate. If they are executed
together as a single statement, p1 ph2 pl3, then the spectrometer
will execute the pulse with duration, phase, and power set to the values
P[1], PH[2] and PL[3], respectively. The phase
and power levels will remain at those values until changed by other commands.
Because the association of subordinate commands with principal commands is
dependent upon their types, their grouping cannot always be determined by the
parser. For built-in or predefined commands, the type-dependence of the command
combinations can be encoded in the grammar. However, for user-defined commands,
this type-dependence cannot be captured in a context-free grammar.
In the preceding listing showing selected lines from hCC.cp, a
user-defined command is declared, by the statement define pulse mixing.
The duration of the pulse mixing is modified in a relation,
mixing=(l1*TauR). mixing is then invoked just like a
predefined command with mixing ph20 pl14. Here, its execution is
modified by the subordinate commands "ph20" and "pl14", as well as the ":H"
channel selection. Without knowledge that "mixing" is a pulse, from earlier in
the program, it is impossible to determine whether "mixing" is a pulse or a
delay. If the source code is assumed to be syntactically valid, it is possible
to infer that mixing is a principal command, but whether ph20 and
pl14 are valid subordinate commands for mixing cannot be
determined.
This difficulty in parsing mildly context-sensitive code with iXML could be
addressed with the "lexer hack" that is used, for example, in parsing C. In this
context, the lexer hack would involve parsing the user-defined commands, and
then including them in a modified grammar for parsing the code as if they were
part of the language definition. To accomplish that, it is necessary to be able
to generate production rules to identify words in a given list, a potential
solution to which is discussed next.
Disambiguation of Reserved Keywords, Predefined Commands, and User-defined
Commands
The core language allows for the definition of user-defined commands of
several types. Those commands are allowed to have arbitrary alphanumeric
identifiers of up to 11 characters. Reserved keywords are not valid identifiers
for user-defined commands, but the programmer is only warned against collisions
with predefined commands. Because command invocation is specified by bare
identifiers, there is nothing to distinguish reserved keywords and predefined
commands from user-defined commands other than their specific values. The
reserved keywords and predefined commands can be included in the grammar, but
user-defined command identifiers cannot be recognized except by exclusion from
the other two groups. Invisible XML does not include a facility for negative
matches or identification of keywords.
The need to distinguish between keywords and identifiers occurs in several
places. One example is that the only way to distinguish between a macro call and
a subroutine call is that subroutine calls are preceded by the keyword "subr,"
meaning that the most natural way to match a distinguish between the two is to
abandon the possibility of a macro call when "subr" is observed. This approach
is complicated by the possibility that a macro call could immediately follow a
user-defined command which is only distinguished from the keyword "subr" if the
identifier is matched with the keyword-negative match approach described above.
Another example is the manifest_append - manifest_end
construction. In a pulse program it is possible to write a block text to an
output file called a manifest by surrounding the block with the keywords
manifest_append and manifest_end. The text in that block is
unrestricted except that the string "manifest_end" must not appear in the body
of the appended text. The manifest_append and manifest_end
construct is used in the pulse sequence diffCONVEX, included in
TopSpin 4, to append experimental details to the manifest file represented as
XML.
Implementing this sort of restriction would be straightforward as a negative
match or via a regular expression. For example, the Perl-compatible regular
expression /manifest_append(.*?)manifest_end/ms matches any text
starting with "manifest_append" up to the first occurrence of "manifest_end". It
makes use of the multiline ("m") and single line ("s") flags to cause the "."
character to match any character including newlines. It also uses the "?"
modifier to the "\*" operator, which specifies zero-or-more repeats, to make it
non-greedy, meaning that it matches the shortest text that satisfies the
pattern. To replicate this behavior in iXML requires the following construction:
This sort of construction is straight-forward but cumbersome to write by hand.
Difficulty in Specifying Character Sets
The manifest_append - manifest_end example also exposes
a difficulty in specifying character sets in iXML. While a character set can be made
into an "exclusion" by prepending it with a tilde character, there is no way to
perform set operations on character sets. For instance, it may be useful to specify
that a character must be in the Unicode general category "L" containing letters but
cannot be in a small, restricted set. For example, '~["d"]' will match *any*
character other than "d," though it is unspecified whether Bruker pulse code
supports arbitrary Unicode characters. A safer way to specify that the character can
be any printable ASCII character but excluding the lower-case "d" and control
characters other than whitespace would be as [#9;#a;#d;#20-"c";"e"-"~"],
but it is substantially more opaque to anyone who is not experienced with iXML.
Strategies for Implementing Negative Matches in iXML
The problem of implementing negative matches for any rule in a context-free grammar
is
intractable because context-free languages are not closed under complement Hopcroft, et al., 2000. However, regular languages are closed under complement,
union, and intersection. Because regular languages are recognized by deterministic
finite state automata (DFSAs), it is possible to build a DFSA that recognize a string
as
a member of a regular language A unless it is also a member of regular language B,
by
using standard methods to construct the complement of the DFSA recognizing strings
in B,
and intersecting it with the DFSA that recognizes strings in A.
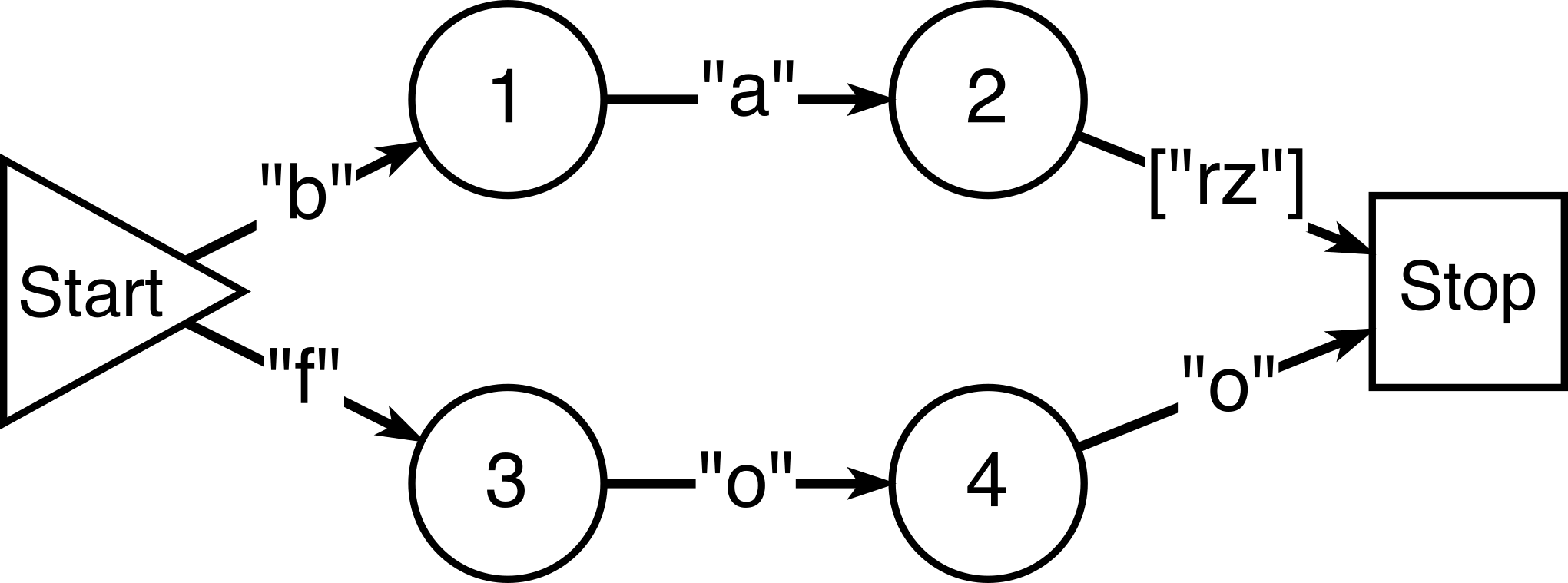
For the simplified problem of recognizing identifiers consisting of lower case Latin
letters (identifier: ["a"-"z"].) that are not the keywords "foo", "bar", or "baz"
(keyword: "foo"| ("ba",("r"|"z")).), the problem is efficiently solved by constructing
a
Deterministic *Acyclic* Finite State Automaton (DAFSA), using an algorithm described
by
Daciuk et al. Daciuk, et al., 2000, for {"foo","bar","baz"} Figure 1,
and making a few modifications:
rename the final state "keyword"
add an "identifier" state, pointed to by ε-transitions from all
"intermediate" nodes
for each intermediate node, add transitions to a new "identifier prefix"
state, for any character that would be allowed in an identifier at that position,
but is
not already accounted for by an existing outgoing transition.
add transitions are added for ε, and any letter, from "identifier prefix"
to "identifier" and from "identifier" back to itself.
Figure 1: Deterministic *Acyclic* Finite State Automaton.
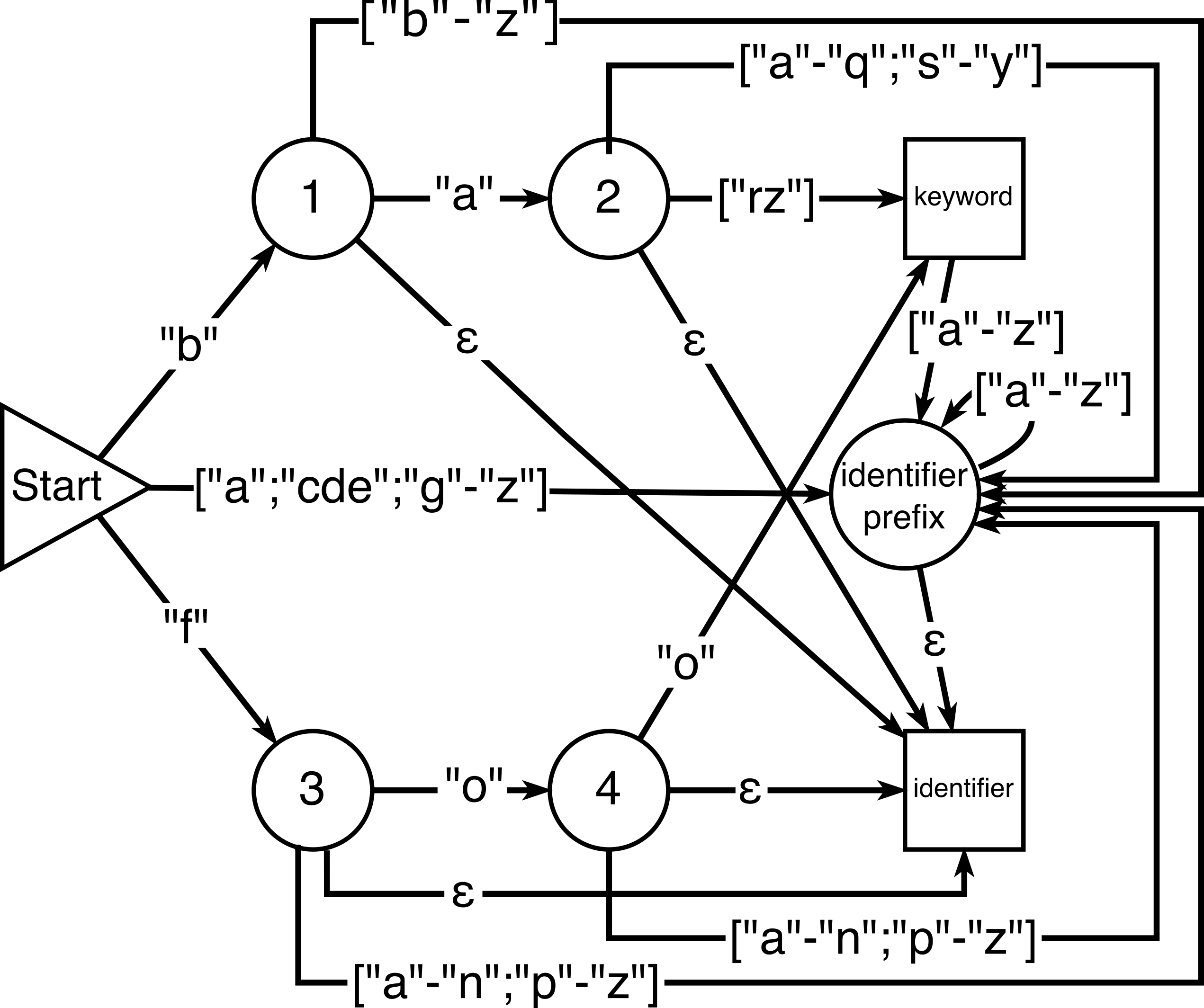
The result Figure 2 is a DFSA that is "complete" with respect to the
set of all strings that are valid keywords or identifiers, and for which keywords
end in
the "keyword" state and non-keyword identifiers end in the "identifier" state.
Figure 2: Augmented Deterministic *Acyclic* Finite State Automaton.
A DFSA recognizing a regular language can be converted into iXML by writing production
rules for each state with alternatives for all incoming transitions, each consisting
of
the nonterminal for the state it leads from, followed by one of the symbols allowed
by
that transition. Implementing this procedure for the "foo", "bar", "baz" example,
results in the following iXML grammar:
This approach to construct rules for recognizing non-keyword identifiers
introduces an extra step in the process of authoring a grammar but is ultimtely a
minor
inconvenience once implemented. In the Bruker language grammar, it greatly decreases
the
verbosity of hand-written rules. The tension between simplicity and expressivity is
not
unique to iXML. A project with some parallels to iXML is that of XML Schema Definition
(XSD) and simpler schema languages. XSD is a comprehensive language for defining the
structure and data types of XML documents, capable of handling both simple and complex
schemas. At the same time, RELAX NG was developed to offer a different approach,
focusing on a more concise and flexible syntax. Both XSD and RELAX NG were designed
to
meet specific needs and use cases within the XML community. Invisible XML's simplicity
and generality are significant strengths that could be impacted by the inclusion of
high-level features like negative matches. Using iXML as a target for code generation
is
a possible strategy for enhancing its application to complex problems and has proved
useful in dealing with the large number of keywords present in Bruker pulse programs.
Comparison of iXML to other Parsing Tools
Parsing of text is a widely-explored area with a long history. Several approaches
have
gained popularity with various advantages and disadvantages. Traditional parser
generators like Bison Donnelly & Stallman, 2021, use grammars specified in
Backus-Naur Form (BNF) or its variants and produce parsers by generating code in various
programming languages. This automation significantly reduces development time and
produces consistently effective and efficient parsers, but it introduces rigidity
and
requires generation and compilation for each new grammar or change to an existing
grammar Aho, et al., 2006.
Parsing Expression Grammars (PEGs) effectively eliminate ambiguity in grammars by
greedily choosing the first rule that matches the text being parsed Ford, 2004.
This approach, utilized by tools like PEG.js, and by CPython for parsing Python source
code, facilitates a sometimes more intuitive handling of language constructs that
might
pose complexities for traditional BNF-based parsers. It also has the distinct advantage
of not requiring compilation, significantly speeding up grammar development. However,
its reliance on backtracking can cause lower efficiency than parsers based on Earley
or
the LR-family or parsing algorithms.
Parametrized parsers, like iXML, in contrast to parsers from hand-written or generated
parsers, take a grammar as an input alongside the text to be parsed Pemberton, 2019. This approach could sacrifice some efficiency by making it
difficult to implement certain optimizations but gains in flexibility by having a
uniform interface that is independent of the language being parsed. iXML, specifically,
takes a grammar defined in a single text file and outputs parse trees in XML, which
has
a rich ecosystem of libraries and tools that facilitate downstream use. The Tree-sitter
parser generator brings together an interesting combination of features; it has graceful
error handling, built-in support for composition, and a uniform API for interacting
with
the parse tree Brunsfeld, et al., 2024. Like iXML, Tree-sitter aims to address the
proliferation of highly customized parsers and the resulting difficulty of dealing
with
their many different interfaces, restrictions, and dependencies. As a parser generator,
Tree-sitter has a build step that takes an input grammar, specified in JavaScript,
and
generates a parser as a dependency-free library written in C, whose functions can
then
be called from many different languages. However, this approach has the disadvantage,
shared by all parser generators, that every new grammar or modification to an existing
grammar requires going through a build step that produces a separate parser. Having
a
separate library for each language causes increased space requirements and, when
Tree-sitter itself is updated, requires rebuilding every parser to take advantage
of any
new features or bug fixes. However, despite these difficulties, Tree-sitter has become
very popular, especially as a backend for providing syntax highlighting, indentation,
formatting, and other features in integrated development environments, where its fast
incremental parsing and error handling allow the parse tree to be maintained alongside
code that is being actively edited, with minimal latency. The two main advantages
that
Tree-sitter has over iXML with regards to the problems encountered in implementing
a
grammar for the Bruker Pulse Programming Language are its support for complex rules,
enabled by code generation, and its support for grammar composition.
Tree-sitter grammars are specified in JavaScript, which is then executed to produce
a
new grammar in a BNF-like JSON syntax. This design choice allows Tree-sitter to
implement complex grammatical constructs such as regular expressions, negative matches,
and priority, which are then translated into a simpler grammatical syntax. It also
means
that the grammar author has access to JavaScript to ease in the implementation of
repetitive or cumbersome grammatical rules. This approach, using a BNF-style grammar
as
the target of code generation, is one possible avenue that could be used to add higher
level features to iXML. It has the advantage of making grammar authoring easier but,
adds extra layers of complexity and latency while decreasing the readability of the
resulting grammar. However, it maintains iXML's advantages in terms of a uniform parse
tree representation and the benefits of using a single parsing program for many
languages.
Tree-sitter's approach to grammar composition could be more difficult to adapt for
use
with iXML. Tree-sitter uses "queries" implemented as S-expressions, to describe patterns
in the parse tree that should be identified and actions to perform when the patterns
are
found. Grammar composition is accomplished by writing queries that recognize where
source code of a different language, for instance a SQL query specified as a string
inside of a Python program, might be found and adds a trigger for the identified text
to
be parsed by the appropriate parser for that language.
def get_data(connection):
query = "SELECT * FROM data WHERE value > 10"
result = connection.execute(query)
return result.fetchall()
Here, if the Python parser is augmented with a rule that indicates that a string may
contain code in a different language, it could be identified as valid SQL syntax,
and
parsed as such. This sort of behavior could be implemented in iXML by adding the ability
to include grammars in other grammars, or through a pragma-based syntax. This kind
of
ability has many other applications; continuing with Python as an example, it is common
for a script to contain regular expressions, HTML, URLs, etc. Supporting grammar
composition would have the added benefits of increasing grammar modularity and
decreasing repetition.
Future Work
The ability to parse Bruker pulse code into a structured representation will enable
many applications that were previously laborious or impossible. A practical next step
would be to develop a procedure for converting the parse tree into an abstract syntax
tree (AST) to facilitate the development of an interpreter that could act as a "virtual
spectrometer". The ability to simulate code execution would allow researchers to
recreate the sequence of RF pulses and the layout of measurements in the data file
without immediate access to a spectrometer or tedious manual interpretation.
Both the syntax and the customary usage of Bruker Pulse Programming Language have
evolved over its lifetime, and programming styles can vary, but the conceptual structure
of pulse sequences has remained fairly consistent. Normalizing an AST into a more
abstract representation of the pulse sequence would facilitate comparison across pulse
sequence and pulse programming language versions. A sufficiently general pulse sequence
representation could be used as a canonical representation, not just for pulse programs
for Bruker spectrometers, but for pulse code written for any current or historical
spectrometer. The ability to apply the rich ecosystem that exists around XML promises
to
greatly accelerate this and other parse tree transformations.
NMR spectroscopy, especially as applied to structural biology and metabolomics,
suffers from fragmentation and a history of limited exchange of both pulse code and
experimental data. As the rate of scientific development and publishing accelerates,
the
need for tools that help automate the comparison and interchange of ideas and techniques
becomes even more important.
Conclusions
Invisible XML proved to be an effective tool for parsing Bruker pulse code. While
it
lacks some higher-level features common to other parsing tools, its simplicity made
it
relatively easy to understand errors, and the lack of a build step made the iterative
process of editing and testing a grammar efficient . While the problem of inferring
a
grammar from examples is complex, iXML adds very little extra cognitive load to the
grammar developer. The concise syntax of iXML makes it an attractive target for code
generation, where it plays a role similar to an intermediate language in analogy to
some
compiler designs. The question of whether higher level grammar constructs should be
implemented via code generation, as pragmas, or as additions to the iXML grammar syntax
requires careful consideration. As it stands, invisible XML is simple and powerful
enough that, once it is supported and integrated more widely, it could supplant regular
expressions for many tasks, with the benefit of much greater clarity.
Scientific measurements are increasingly performed and collected using complex
computerized equipment, often controlled by proprietary software. Often, the details
of
the measurement are hidden from the experimenter and readers of resulting papers,
intentionally or not, by incomplete documentation, or by a lack of expertise in
interpretation of the configuration files and the particular measurement device. Tools
like invisible XML, that make configuration files and control programs for scientific
devices more accessible and interpretable consequently improve the accessibility,
reproducibility, and long-term usefulness of measurements and the conclusions they
support.
Acknowledgements
This research was conducted as part of the NMRbox project, supported by the U.S.
National Institutes of Health under grant number NIH/NIGMS 1P41GM111135, and as part
of
the Network for Advanced NMR, supported by the U.S. National Science Foundation under
grant number 1946970.
References
[Aho, et al., 2006] Alfred V. Aho, Monica S.
Lam, Ravi Sethi, and Jeffrey D. Ullman. Compilers: Principles, Techniques, and
Tools (2nd Edition). Addison-Wesley Longman Publishing Co., Inc., USA, 2006.
[Brunsfeld, et al., 2024] Max Brunsfeld, Andrew
Hlynskyi, Amaan Qureshi, Patrick Thomson, Josh Vera, Phil Turnbull, dundargoc, Timothy
Clem, Douglas Creager, Andrew Helwer, Rob Rix, Daumantas Kavolis, ObserverOfTime,
Hendrik van Antwerpen, Michael Davis, Ika, Tuấn-Anh Nguyễn, Amin Yahyaabadi, Stafford
Brunk, … Linda_pp. 2024. tree-sitter/tree-sitter: v0.22.2. Zenodo.
doi:https://doi.org/10.5281/zenodo.10827268
[Cavanagh, et al, 1996] John Cavanagh, Wayne J. Fairbrother, Arthur G. Palmer III, and Nicholas J. Skelton.
Protein NMR
Spectroscopy: Principles and Practice. Academic Press, 1996.
[Ford, 2004] Bryan Ford. Parsing Expression
Grammars: A Recognition-Based Syntactic Foundation.
Symposium on
Principles of Programming Languages, January 14-16, 2004, Venice, Italy. doi:https://doi.org/10.1145/982962.964011
[Gazillo & Grimm, 2012] Paul Gazzillo and
Robert Grimm. SuperC: parsing all of C by taming the preprocessor. In
Proceedings of the 33rd ACM SIGPLAN Conference on Programming Language Design
and Implementation (PLDI '12), 323–334. Association for Computing Machinery,
New York, NY, USA (2012). doi:https://doi.org/10.1145/2254064.2254103
[Hillman, 2022] Tomos Hillman, C. M.
Sperberg-McQueen, Bethan Tovey-Walsh, and Norm Tovey-Walsh. Designing for change:
Pragmas in Invisible XML as an extensibility mechanism. Presented at Balisage:
The Markup Conference 2022, Washington, DC, August 1 - 5, 2022. In Proceedings
of Balisage: The Markup Conference 2022. Balisage Series on Markup
Technologies, vol. 27 (2022).
doi:https://doi.org/10.4242/BalisageVol27.Sperberg-McQueen01
[Hillman, et al., 2022] Tomos Hillman, John
Lumley, Steven Pemberton, C. M. Sperberg-McQueen, Bethan Tovey-Walsh, and Norm
Tovey-Walsh. Invisible XML coming into focus: Status report from the community
group. Presented at Balisage: The Markup Conference 2022, Washington, DC, August
1 - 5, 2022. In Proceedings of Balisage: The Markup Conference 2022.
Balisage Series on Markup Technologies, vol. 27 (2022). doi:https://doi.org/10.4242/BalisageVol27.Eccl01
[Hopcroft, et al., 2000] John E. Hopcroft, Rajeev
Motwani, Rotwani, and Jeffrey D. Ullman. Introduction to Automata Theory,
Languages and Computability (2nd. ed.). Addison-Wesley Longman Publishing
Co., Inc., USA, 2000.
[Pemberton, 2021] Pemberton, Steven. Invisible
XML. Presented at Balisage: The Markup Conference 2013, Montréal, Canada, August
6 - 9, 2013. In Proceedings of Balisage: The Markup Conference 2013.
Balisage Series on Markup Technologies, vol. 10 (2013). doi:https://doi.org/10.4242/BalisageVol10.Pemberton01
[Pemberton, 2019] Steven Pemberton. On the
Specification of Invisible XML. Proc. XML Prague, 413-430.
2019.
[TopSpin Manual, 2022] Bruker Corporation. TopSpin - NMR Pulse Programming User Manual. 2022
[Tovey Walsh, 2023] Norm Tovey-Walsh. Ambiguity
in iXML: And How to Control It. Presented at Balisage: The Markup Conference
2023, Washington, DC, July 31 - August 4, 2023. In Proceedings of Balisage:
The Markup Conference 2023. Balisage Series on Markup Technologies, vol. 28
(2023). doi:https://doi.org/10.4242/BalisageVol28.Tovey-Walsh01
[Ulrich, et al., 2008] E.L. Ulrich, H. Akutsu,
J.F. Doreleijers, Y. Harano, Y.E. Ioannidis, J. Lin, M. Livny, S. Mading, D. Maziuk,
Z. Miller, E. Nakatani, C.F. Schulte, D.E. Tolmie, R.K. Wenger, H. Yao, and J.L.
Markley. BioMagResBank. Nucleic Acids
Research, 36, D402–D408 (2008).
doi:https://doi.org/10.1093/nar/gkm957
Alfred V. Aho, Monica S.
Lam, Ravi Sethi, and Jeffrey D. Ullman. Compilers: Principles, Techniques, and
Tools (2nd Edition). Addison-Wesley Longman Publishing Co., Inc., USA, 2006.
Max Brunsfeld, Andrew
Hlynskyi, Amaan Qureshi, Patrick Thomson, Josh Vera, Phil Turnbull, dundargoc, Timothy
Clem, Douglas Creager, Andrew Helwer, Rob Rix, Daumantas Kavolis, ObserverOfTime,
Hendrik van Antwerpen, Michael Davis, Ika, Tuấn-Anh Nguyễn, Amin Yahyaabadi, Stafford
Brunk, … Linda_pp. 2024. tree-sitter/tree-sitter: v0.22.2. Zenodo.
doi:https://doi.org/10.5281/zenodo.10827268
John Cavanagh, Wayne J. Fairbrother, Arthur G. Palmer III, and Nicholas J. Skelton.
Protein NMR
Spectroscopy: Principles and Practice. Academic Press, 1996.
Jan Daciuk, Stoyan Mihov,
Bruce W. Watson, and Richard E. Watson. Incremental Construction of Minimal Acyclic
Finite-State Automata. Computational Linguistics 2000; 26
(1): 3–16. doi:https://doi.org/10.1162/089120100561601
Paul Gazzillo and
Robert Grimm. SuperC: parsing all of C by taming the preprocessor. In
Proceedings of the 33rd ACM SIGPLAN Conference on Programming Language Design
and Implementation (PLDI '12), 323–334. Association for Computing Machinery,
New York, NY, USA (2012). doi:https://doi.org/10.1145/2254064.2254103
D. Grune and C.J.H. Jacobs. Introduction to Parsing. In: Parsing Techniques.
Monographs in Computer Science. Springer, New York, NY, 2008.
doi:https://doi.org/10.1007/978-0-387-68954-8_3
Tomos Hillman, C. M.
Sperberg-McQueen, Bethan Tovey-Walsh, and Norm Tovey-Walsh. Designing for change:
Pragmas in Invisible XML as an extensibility mechanism. Presented at Balisage:
The Markup Conference 2022, Washington, DC, August 1 - 5, 2022. In Proceedings
of Balisage: The Markup Conference 2022. Balisage Series on Markup
Technologies, vol. 27 (2022).
doi:https://doi.org/10.4242/BalisageVol27.Sperberg-McQueen01
Tomos Hillman, John
Lumley, Steven Pemberton, C. M. Sperberg-McQueen, Bethan Tovey-Walsh, and Norm
Tovey-Walsh. Invisible XML coming into focus: Status report from the community
group. Presented at Balisage: The Markup Conference 2022, Washington, DC, August
1 - 5, 2022. In Proceedings of Balisage: The Markup Conference 2022.
Balisage Series on Markup Technologies, vol. 27 (2022). doi:https://doi.org/10.4242/BalisageVol27.Eccl01
John E. Hopcroft, Rajeev
Motwani, Rotwani, and Jeffrey D. Ullman. Introduction to Automata Theory,
Languages and Computability (2nd. ed.). Addison-Wesley Longman Publishing
Co., Inc., USA, 2000.
Pemberton, Steven. Invisible
XML. Presented at Balisage: The Markup Conference 2013, Montréal, Canada, August
6 - 9, 2013. In Proceedings of Balisage: The Markup Conference 2013.
Balisage Series on Markup Technologies, vol. 10 (2013). doi:https://doi.org/10.4242/BalisageVol10.Pemberton01
Norm Tovey-Walsh. Ambiguity
in iXML: And How to Control It. Presented at Balisage: The Markup Conference
2023, Washington, DC, July 31 - August 4, 2023. In Proceedings of Balisage:
The Markup Conference 2023. Balisage Series on Markup Technologies, vol. 28
(2023). doi:https://doi.org/10.4242/BalisageVol28.Tovey-Walsh01
E.L. Ulrich, H. Akutsu,
J.F. Doreleijers, Y. Harano, Y.E. Ioannidis, J. Lin, M. Livny, S. Mading, D. Maziuk,
Z. Miller, E. Nakatani, C.F. Schulte, D.E. Tolmie, R.K. Wenger, H. Yao, and J.L.
Markley. BioMagResBank. Nucleic Acids
Research, 36, D402–D408 (2008).
doi:https://doi.org/10.1093/nar/gkm957