Balisage Paper: Clean SOAP
Evaluating AI-based Structured Document Generation in a Medical Context
Paul Prescod
Staff Engineer
Elation Health
Paul Prescod has more than 20 years of software design and development
experience, spanning enterprise software, document processing, healthcare, and
even games. His early contributions to the field include advising on the design
of XML at the World Wide Web Consortium and authoring “The XML Handbook.” During
this period, he played a key role in popularizing the REST Architectural Style
and advised organizations on integrating it into their web services stack.
At Elation Health, Paul is dedicated to applying AI to reduce documentation
burnout for primary care physicians.
Phill Tornroth
VP, Technical Strategy
Elation Health
As one of Elation Health’s earliest and longest-tenured employees, Phill
Tornroth has, in the words of Forbes Magazine, “quietly built a leading
electronic health record for primary care physicians” in close collaboration
with Elation’s co-founders, Kyna and Conan Fong. Phill is passionate about using
disruptive technology to reduce the documentation burden for PCPs. Since his
first “physician shadowing” in 2010, Phill’s approach has always been to
frequently engage with doctors and express empathy through engineering and
leadership through listening.
In his current role as VP, Phill leads Elation’s strategy to find safe,
effective, and ethical ways to adapt AI for this purpose.
Copyright 2024, Elation Health. Republished with permission.
Abstract
Healthcare systems worldwide face a crisis: there are far too few Primary Care
Physicians (PCPs), and they are severely overworked. Modern Electronic Health
Records (EHR) systems, while solving critical issues with paper-based records, have
significantly increased the burden of medical case documentation. An “AI Scribe” is
an artificial intelligence system designed to streamline clinical documentation by
automatically generating “doctor visit notes,” which all physicians must produce
following a patient visit. AI Scribe systems leverage natural language processing
(NLP) and machine learning to interpret and document patient encounters in a format
called SOAP (Subjective, Objective, Assessment, Plan). However, implementing AI in
medical documentation raises multiple risks, including hallucinations, critical
detail omissions, misclassifications, narrative quality and organization issues,
security and privacy concerns, bias and discrimination, and legal and ethical
challenges. Automated testing of AI-generated SOAP Notes is essential but poses its
own challenges. Using Large Language Models to test the output of other Large
Language Models can automate and scale semantic and contextual SOAP testing. The
critical questions are: what can we test successfully, and how do we avoid an
infinite regress of validators?
Table of Contents
- Context: The Documentation-effort Crisis in PCP Healthcare
-
- The Risks to Quality
- AI Scribe and SOAP Notes
- Correctness in a Stochastic System
-
- Evaluating Transcription and Transcript Cleanup
- Automating Textual Quality Assessment
- Dealing with Ambiguity
- Meta-Validation
- The Role of Human Expertise
- Results
- Related Work
- Conclusions
Context: The Documentation-effort Crisis in PCP Healthcare
Healthcare systems around the world are in crisis due to a shortage of Primary Care
Physicians (PCPs). This shortage has well-documented negative effects on health outcomes
and systemic costs.
There are many reasons for the PCP shortage, and not all of them are related to
technology or can be fixed by it. However, some issues do relate to technology. One
doctor characterizes the medical documentation situation as follows:
😢 “I just want to take care of people. That’s my job. I’m good at it. But
Electronic Health Records Systems reduce the number of people that I can serve.
Electronic medical records have changed me and my entire profession. Not in a good
way. Before EHR, I saw 24 patients in a 12-hour day. Now I can only see 10 patients,
and I still work 12-hour days. Six hours to spend with patients and then six hours
documenting BS that has no impact on their care.”
— Guy Culpepper, MD, on
LinkedIn
The Markup Technologies community has been at the forefront of promoting the use of
digital record-keeping technologies, and rightly so. The old way of data management
was
disastrous. Previously, vital patient information was trapped in single-location paper
files inaccessible to other providers. That was no way to run a life-or-death
information system in the 21st century.
However, we must now reverse the negative trend in documentation effort. Our North
Star should be that doctors view medical documentation management systems the way
programmers view version control systems or accountants view spreadsheets: as powerful
tools assisting them in getting their job done, rather than corporate and
regulatory-imposed obstacles to patient care.
An “AI Scribe” refers to an artificial intelligence system designed to assist
healthcare professionals by automatically generating “visit notes” in the SOAP
(Subjective, Objective, Assesssment, Plan) format. These systems leverage natural
language processing (NLP) and machine learning to interpret and document patient
encounters, thereby streamlining the process of clinical documentation. The AI Scribe
“listens in” to a doctor-patient interaction (with dual consent!) and automatically
generates the documentation that the doctor would usually type up on evenings and
weekends.
One doctor’s transformative experience with AI Scribes was described in the Canadian
news:
During the summer of 2023, Dr. Rosemary Lall, a family physician working at a
bustling medical clinic in Scarborough, hit her breaking point.
“I lost all my joy of work,” Lall told Global News. “I was coming into work really
dreading the day.”
The administrative burden would often take her up to two hours per day. Ontario’s
Medical Association has estimated family doctors spend 19 hours per week on
administrative tasks, including four hours spent writing notes or completing forms
for patients.
The solution, Lall said, was new artificial intelligence note-taking apps that are
designed to mimic doctor’s notes and reduce the amount of paperwork a physician
would have to manually compile.
…
Lall said the true benefit comes after the appointment when the AI Scribe compiles
the information into a so-called SOAP note, a standard requirement for family
physicians as prescribed by the College of Physicians and Surgeons of Ontario.
If the physician is unhappy with the note, Lall said, they can ask the AI model to
regenerate the information or add more detail to any one of the categories. While
the tool has some imperfections, she said, the improvements have been noticeable
over the 10 months since she began using it.
“I really feel this should be the next gold standard for all of our doctors. It
decreases the cognitive load you feel at the end of the day,” she said.
Lall said that after 29 years as a family physician, last Christmas was the first
celebration that wasn’t interrupted by the need to update patient notes thanks to
the AI notetaking software.
“For me, this has changed things,” Lall said. “It’s made me really happy.”
This is far from a unique case. When Kaiser Permenante rolled out AI Scribe, thousands
of doctors voluntarily enrolled and one said: “I use it for every visit I can and
it is
making my notes more concise and my visits better. I know I’m gushing, but this has
been
the biggest game changer for me.”
Dr. Lall’s work on notes every Christmas is an extreme case of what many physicians
call “Pajama time”.
This is the time that they spend after their kids are in bed where they try to complete
the paperwork that they could not fit into the normal work day. Beyond the distressing
implications from the point of view of work-life balance, what does it mean for health
delivery quality if doctors are writing up their notes from memory, hours after the
visit?
Although most readers likely have deep compassion for the challenging situation of
these doctors, it is also appropriate to be concerned about the substantial risks
posed
by a naive implementation of AI into the medical documentation generation system.
The Risks to Quality
As described earlier, AI Scribe is a rapidly evolving product category that
consists of tools that are authorized to listen into a patient/doctor conversation
and generate a “Visit Note” in the SOAP format.
SOAP is a loose format for Physician Visit Notes which was developed by Dr.
Lawrence Weed in the 1960's at the University of Vermont. Lawrence Weed explained
his zeal for organized records like this:
“We really aren’t taking care of records — we’re taking care of people. And
we’re trying to get across the idea that this record cannot be separated from
the caring of that patient. This is not something [distinct]: the practice of
medicine over here and the record over here. This is the practice of medicine.
It’s intertwined with it. It determines what you do in the long run. You’re a
victim of it or you’re a triumph because of it. The human mind simply cannot
carry all the information about all the patients in the practice without error.
And so the record becomes part of your practice.”
While AI Scribes offer significant advantages in the automation of SOAP note
generation, several risks are associated with potential mistakes they could make.
These risks can impact patient care, data integrity, legal compliance, and
reimbursement. Key risks include:
-
Incorrect Data Entry:
-
Misinterpretation of Information: The AI Scribe might
misunderstand or misinterpret the patient’s statements or clinical
data, leading to inaccurate documentation.
-
Hallucination:
Generative AIs are prone to creating and injecting non-factual
information to overcome uncertainty when completing the wrong word.
-
Incomplete Documentation:
-
Omission of Critical Information: The AI might fail to capture
important details such as key symptoms, relevant medical history, or
specific findings from the physical examination.
-
Lack of Context: Missing contextual information can lead to
incomplete or ambiguous notes, which can affect clinical
decision-making.
-
Bias and Discrimination:
-
Algorithmic Bias: If the AI Scribe's algorithms are biased, they
might systematically produce notes that reflect or reinforce
existing healthcare disparities.
-
Inconsistent Documentation: AI systems might perform
inconsistently across different patient populations or clinical
settings, leading to unequal quality of care.
-
Narrative and Presentation quality issues:
-
Logical Narrative: The AI might generate notes that lack a
coherent narrative, making it difficult for healthcare providers to
follow the patient's story or understand the clinical context.
-
Logical Order: Information might be presented in a disorganized
manner, disrupting the logical flow of the SOAP note and
complicating the interpretation of clinical data.
-
Voice and Tone: Does the output sound natural and in accordance
with medical best practices
-
Technical Issues:
-
Software Bugs: Technical glitches or software bugs can lead to
erroneous data entry or loss of information.
-
Integration Problems: Issues with integrating the AI Scribe with
other Electronic Health Record (EHR) systems can result in data
mismatches or duplications.
-
Privacy and Security Concerns:
-
Data Breaches: As with any digital system, there is a risk of data
breaches which could expose sensitive patient information.
-
Unauthorized Access: Improper access controls could allow
unauthorized individuals to view or alter patient records.
-
Legal and Ethical Issues:
-
Liability: Incorrect notes could result in legal action against
healthcare providers or institutions if the errors lead to patient
harm.
-
Ethical Concerns: There may be ethical issues around the reliance
on AI for clinical documentation, especially if it impacts the
quality of patient-provider interactions.
This paper is focused on the first four issues, although Elation Health takes all
seven very seriously. Contracts prevent us from publishing evaluation results for
specific Note Generation models, but this paper describes our evaluation mechanism
for these factors.
AI Scribe and SOAP Notes
Having established the stakes, let us turn to the problem. Given an audio
trasnscript for an input text like this (from the ACI-Bench corpus):
hey brandon you know glad to see you in here today i see on your chart that you're experiencing some neck pain could you tell me a bit about what happened
yeah i was in a car crash
wow okay when was that
well which car crash
okay so multiple car crashes alright so let's see if we can how many let's start
my therapist said well my well actually my mother said i should go see the therapist and the therapist said i should see the lawyer but my neck's hurting
okay so i'm glad that you know you're getting some advice and so let's let's talk about this neck pain how many car crashes have we had recently
well the ones that are my fault or all of them
all of them
i was fine after the second crash although i was in therapy for a few months and then after the third crash i had surgery but i was fine until this crash
okay the most recent crash when was that
that's when i was coming home from the pain clinic because my neck hurt and my back hurt but that was in february
okay alright so we had a car crash in february
what year it was which february it was
okay so let's let's try with this one see what happens hopefully you remember i need you to start writing down these car crashes that this is becoming a thing but you know it's okay so let's let's say maybe you had a
you're not judging me are you
no there's no judgment here whatsoever i want to make sure that i'm giving you the best advice possible and in order to do that i need the most information that you can provide me makes sense
yes
alright so we're gon na say hope maybe that you had a car crash and we can verify this in february of this year and you've been experiencing some neck pain since then right
yes
okay alright on a scale of one to ten what ten is your arm is being cut off by a chainsaw severe how bad is your pain
twelve
okay terrible pain now i know you mentioned you had previous car crashes and you've been to therapy has anyone prescribed you any medication it's you said you went to a pain clinic yes
well they had prescribed it recently i was i was on fentanyl
oh
i haven't gotten a prescription for several weeks
okay alright and so we will be able to check on that when you take your medication so before you take your medication rather like are you able to move like are you experiencing any stiffness
…
We would like an output like this:
CHIEF COMPLAINT
Neck pain.
HISTORY OF PRESENT ILLNESS
Brandon Green is a 46-year-old male who presents to the clinic today for the
evaluation of neck pain. His pain began when he was involved in a motor vehicle
accident in 02/2022 when he was on his way home from a pain clinic. The patient
notes that he has been in 4 motor vehicle accidents; however, he notes that he was
fine after the first two accidents, but the third motor vehicle accident is when his
neck and back pain began. He states that he was in therapy following the second
accident and had surgery after his third accident. The patient was seen at a pain
clinic secondary to neck and back pain. He was prescribed fentanyl; however, he has
not received a prescription for several weeks. Today, he reports that his pain is a
12 out of 10. He describes his pain as sharp and incapacitating with stiffness and
pain. The patient also reports headaches, occasional dizziness. He denies any recent
visual disturbances. He also reports numbness in his left arm and right leg. The
patient also reports spasms throughout his body. He states that he has been
experiencing fatigue since the accident. He notes that he is unable to work with
this much pain.
REVIEW OF SYSTEMS
Constitutional: Reports fatigue.
Eyes: Denies any recent visual disturbances.
Musculoskeletal: Reports neck and back pain, and occasional swelling and bruising
of the neck.
Neurological: Reports headaches, dizziness, spasms, and numbness.
PHYSICAL EXAM
SKIN: No lacerations.
MSK: Examination of the cervical spine: Pain on palpation on the bony process and
muscle. Moderate ROM. No bruising or edema noted.
RESULTS
X-rays of the neck reveal no fractures.
ASSESSMENT
Neck sprain.
PLAN
After reviewing the patient's examination and radiographic findings today, I have
had a lengthy discussion with the patient in regards to his current symptoms. I have
explained to him that his x-rays did not reveal any signs of a fracture. I
recommended an MRI for further evaluation. I have also prescribed the patient
Robaxin 1500 mg every 6 to 8 hours to treat his pain. I have also advised him to
utilize ice, a heating pad, IcyHot, or Biofreeze on his neck as needed. I have also
provided him with a home exercise program to work on his range of motion. I advised
the patient that he will not be able to work until we have the MRI results.
INSTRUCTIONS
The patient will follow up with me after his MRI for results.
Or…depending on the physician’s tastes, perhaps like this:
CHIEF COMPLAINT
Patient is experiencing neck pain.
HISTORY OF PRESENT ILLNESS
* Motor Vehicle Accident (MVA) - February 2023 (V43.52XA)
- Most recent car crash was in February of this year.
- Patient reports fatigue since the accident.
* Pain (R52)
- Patient rates pain as 12 out of 10.
- Patient experiences stiffness and sharp, incapacitating pain.
- Patient reports it really hurts to bend neck forward and backward.
* Headaches (R51)
- Patient reports headaches, occasional dizziness, and numbness in the left arm
and right leg.
* Muscle Spasms (M62.838)
- Patient reports muscle spasms.
ASSESSMENT AND PLAN
* Neck Sprain (ICD10: S13.4XXA)
- Doctor's assessment is neck sprain.
- Doctor orders an MRI for a more thorough image.
- Doctor prescribes Robaxin, 1500 mg every 6-8 hours.
- Doctor suggests using a heat pad or biofreeze if Robaxin is not effective.
- Doctor plans to refer patient to physical therapy and pain medicine for
possible local injections.
PAST HISTORY
Patient was in multiple car crashes.
CURRENT MEDICATIONS
Patient was previously prescribed fentanyl but has not had a prescription for
several weeks.
PHYSICAL EXAM
Neck: Pain on palpation both on the bony process and on the muscle. Patient has
moderate range of movement in the neck.
Skin: No bruising, swelling, or lacerations observed during the exam.
DATA REVIEWED
X-ray shows no fracture.
PATIENT INSTRUCTIONS
* Doctor advises using ice for bruising and swelling.
* Doctor provides exercises to improve neck movement.
* Patient will be given time off work until MRI results are available.
Can an automated system achieve such a task? And can we be confident enough in it
to trust it with patient transcripts?
Correctness in a Stochastic System
For many reasons, the behaviour of AIs is not as predictable as traditional imperative
software systems. Stochasticity (randomness) is built into their design. They are
black
boxes with billions or trillions of parameters. They are sensitive to floating point
rounding errors. They utilize randomness in their token selection. They are constantly
evolving as corporations upgrade or streamline their models.
As in other parts of computing, when a system grows to the point that we cannot rely
on our intuition nor formal methods, we must use testing.
In traditional software, there are two types of testing: manual and automated.
Similarly, in testing the output of generative AIs, there are two types of testing.
“Vibes checking” is the lowest standard, where humans eyeball outputs to validate
that
they “look right”. Sometimes in software development this is called “smoke testing”.
More formalized types of human-in-the-loop testing are good for identifying certain
kinds of problems, just as structured Quality Assurance testing is appropriate with
other software.
At some point, however, you may decide that you want to check 1000 generated SOAP
notes against 1000 transcripts to validate that not a single incorrect assertion
(“hallucination”) was introduced. And you might want to do it on a daily, weekly or
monthly basis.
At that point, you are either going to need a very large number of humans, who have
an
enormous amount of time and a gigantic budget, or you will need an automated solution.
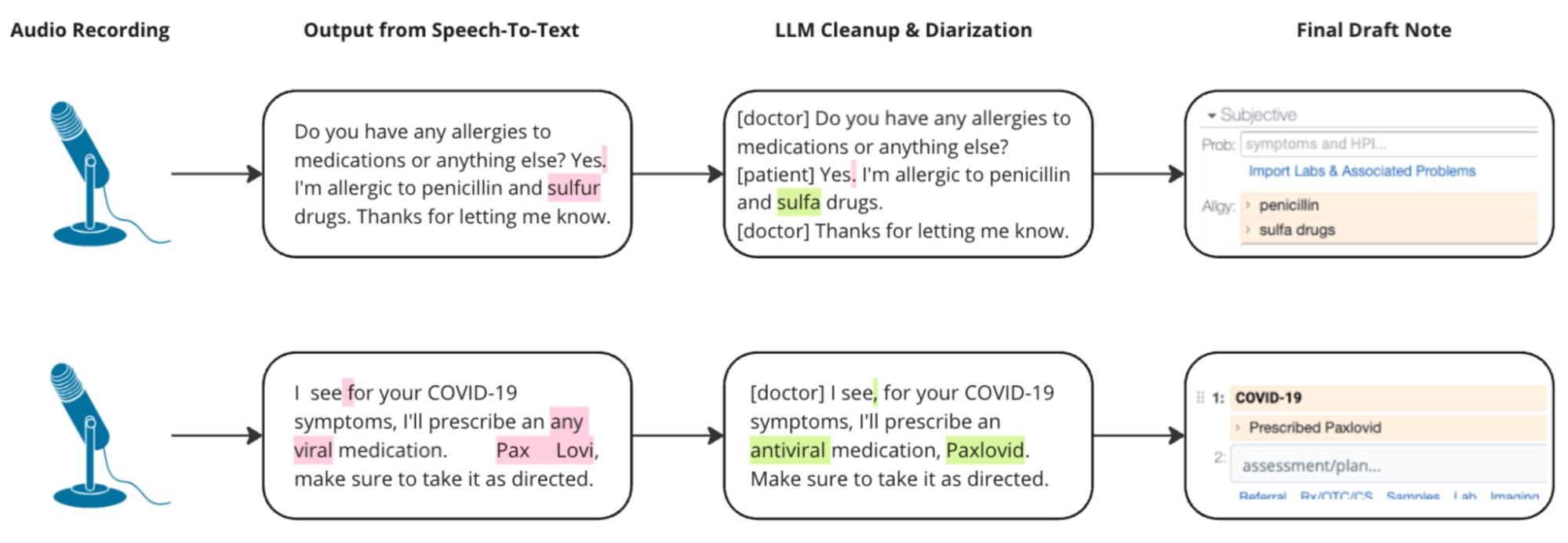
Evaluating Transcription and Transcript Cleanup
Most of these systems operate in two steps: first audio is transcribed into
textual transcripts, and then transcripts are converted into SOAP Notes. One concern
we had was that the first part of this process might make transcription errors and
that the second step would compound the errors.
Instead, we generally found the opposite - the second step would usually correct
for most errors in the first step. This is because the note generation process has
more time and more context to work than the real-time transcription process.
We also found that it is possible to inject an explicit “cleanup this transcript”
step between the audio transcription and the note generation, to improve the output
quality even more.
One particular question we had was about bias and unfairness in transcription. We
hypothesized that the system might work less effectively for doctors with strong
accents or speech impediments. Using co-workers with accents, we did an experiment
to determine whether this was a serious issue.
Early indications confirm that the transcription may bias in the form of higher
error rates for some voices, but that transcript cleanup step with a generalized
Large Language Model model not only corrects for the majority of errors but also
significantly narrows the variability in error rates across voice samples.
Table I
| Sample |
Transcription Accuracy (No Correction) |
Transcription Accuracy after LLM Cleanup |
| WER |
MER |
WIL |
WIP |
CER |
WER |
MER |
WIL |
WIP |
CER |
| Voice 1 |
0.16 |
0.16 |
0.28 |
0.72 |
0.04 |
0.08 |
0.08 |
0.13 |
0.87 |
0.04 |
| Voice 2 |
0.17 |
0.17 |
0.29 |
0.71 |
0.04 |
0.06 |
0.06 |
0.10 |
0.90 |
0.03 |
| Voice 3 |
0.18 |
0.17 |
0.29 |
0.71 |
0.05 |
0.07 |
0.07 |
0.12 |
0.88 |
0.04 |
| Voice 4 |
0.22 |
0.21 |
0.33 |
0.67 |
0.07 |
0.08 |
0.08 |
0.14 |
0.86 |
0.05 |
| Std Dev |
0.026 |
0.022 |
0.022 |
0.022 |
0.014 |
0.010 |
0.010 |
0.017 |
0.017 |
0.008 |
| % Improvement (Avg) |
|
90.03% |
90.48% |
85.56% |
81.66% |
93.00% |
| % Reduction Std Dev |
|
63.60% |
56.82% |
22.98% |
22.98% |
42.26% |
This table compares transcription accuracy metrics before and after applying LLM
(Language Model) cleanup. The table includes multiple metrics: Word Error Rate
(WER), Match Error Rate (MER), Word Information Lost (WIL), Word Information
Preserved (WIP), and Character Error Rate (CER). Lower scores are better for every
value other than WIP.
As you can see on the left, Voice 1 (0.16), a speaker with a standard American
accent, had a dramatically lower Word Error Rate in the initial transcription than
Voice 4 (0.26), a participant who learned English as a Second Language.
Whereas after LLM cleanup, both of them had a Word Error Rate of 0.08. Voice 1 and
Voice 4 had nearly identical error rates and information preservation rates after
data cleanup. In this case, AI is a technology which reduces rather than exacerbates
inequality.
Although our sample size is small, we have consistently seen (in formal and
informal tests) that most errors were generally minor and non-consequential. We have
highlighted a couple of consequential ones in the diagram, but the vast majority are
extremely minor.
We will watch these metrics closely as we scale up the test corpus volume.
Once we are comfortable with the text transcript, we can move on to evaluating the
Note Generation aspect.
Automating Textual Quality Assessment
Our challenge in evaluating Note Generation is that the AI is not the only
stochastic factor in the system. Our gold standard notes are written (or at least
finalized) by humans, and there is a large subjective factor in their decision about
how to structure the information. Both the AI and the human reference documentor
have quite a bit of flexibility in terms of what order they state facts and even
what section of the SOAP note to put facts. This makes it difficult to use
simplistic text-similarity metrics like BLEU, and ROUGE which are common in the NLP
field for text translation tasks.
A bigger problem with these tools, however, is that they are not designed to
describe – in English – what is wrong with the output. They are designed to provide
a score, but not a reason for the score. This is a problem because we want to be
able to provide feedback to the AI developers about what is wrong with the output.
Instead of using these sorts of text-similarity metrics, what we chose to do is
automate – and scale – tests like:
-
“Is every statement in the SOAP note grounded in the transcript? If not,
which are missing?”
-
“Is every relevant fact in the transcript reflected in the SOAP note? If
not, which are extra?”
-
“Is every fact properly categorized? Does it show up in the right part of
the note? Which are not correct?”
In general, traditional imperative code is not sophisticated enough to do this, so
we need to rely on NLP tools, and Large Language Models in particular. This does
raise the question of meta-evaluation: how do we trust the tools that evaluate the
evaluator. This will be discussed in the section Meta-Validation.
Our approach to scoring is strongly influenced by and partially implemented with
the open source project called DeepEval.
For example, here is a prompt that can be used to verify if a certain fact is
grounded in the transcript:
Given the evaluation steps, return a JSON with two keys:
1) a score key ranging from 0 - 10, with 10 being that it follows the
criteria outlined in the steps and 0 being that it does not, and
2) a reason key, a reason for the given score, but DO NOT QUOTE THE
SCORE in your reason.
Please mention specific information from Input and Transcript in your reason, but
be very concise with it!
Evaluation Steps:
1. Extract the key fact from the input.
2. Search the transcript for any mention of the key fact from the input.
3. If the key fact is found anywhere in the transcript, assign a high score.
4. If the key fact is not found in the transcript, assign a low score.
Input:
Neck Pain: Patient cannot swivel neck side to side.
Transcript: hey brandon you know glad to see you in here today… the full
transcript goes here … okay okay any other questions? Not right now. Alright...
Notice how the prompt uses both a score for quantitative and programmatic purposes
and a reason for transparency and human review. Our reports make both parts
accessible to human reviewers and downstream processes.
In addition to using the score, DeepEval does some wizardry with the log
probabilities of the tokens in the output to judge how confident the Evaluator LLM
was in its scoring.
The primary tests that we currently do are:
The output is a 2x2 matrix with different Note Generation System versions and
configurations as columns and criteria like these as rows. For example, a system
might support different SOAP Note styles and we would like to compare the Generation
fidelity across all of them.
None of our testing Transcripts or SOAP notes are from real patients. They are
either authored by Elation Health or part of the ACI-Bench Dataset which was
designed specifically for doing these kinds of evaluations.
Dealing with Ambiguity
There are subtle, usually subjective, cases where humans might disagree with the
evaluator.
For example, the transcript might say:
okay so … let's wait for the mri result… and we'll see what the mri says about
what whether or not we can get you like true local injections
The Note Generator might output:
Follow up after MRI results.
The Evaluator might say that this is not explicitly stated:
Hallucination: Data Reviewed: Follow-up appointment after MRI results are available ❌
Reason: The actual output does not mention the follow-up appointment after MRI results are available.
Score: 6.0%
It is largely correct: the intent to follow up after the MRI is implied, not
stated explicitly. The Generator and Evaluator are both “trying” to be helpful, but
with different “goals”. The Generator “wants” to find something
to add to the Follow-Up section, even if it is implied rather than stated. The
Evaluator “wants” to find facts that are not explicitly grounded.
In a case like this, we would adjudicate that the evaluator is working fine, but
that the evaluation dataset needs to be tweaked to allow this particular fact to be
accepted without criticism. We are developing a sort of “exceptions” mechanism for
this.
This is one of the steps in our process which is the least scalable, at the
moment. This exception labeling does require human annotation. Perhaps by this time
next year we will have trained a third AI to adjudicate these corner cases!
One interesting note on the topic of Follow Ups. One of the few hallucinations
that we do see persistently is “Follow-up in four weeks” and we do in fact need to
watch for this and ensure it does not erroneously slip into real notes. Sometimes
the follow-up is implied, but very occasionally it really is hallucinated.
Meta-Validation
Using Large Language Models to check the output of other Large Language Models
does open up a different can of worms, however. If we cannot trust the LLMs
underlying the Note Generation tools, what makes us feel that we can trust the
tester LLMs? Quis custodiet ipsos custodes? How do we avoid an infinite regress of
validators?
What we do to evaluate the evaluators is create negative examples of tests that
should fail, due to hallucinations, missed facts and other similar factors. By
running tests of what happens if we inject false facts into SOAP notes (or delete
facts from Notes), we can evaluate whether the Evaluator would properly pick up on
those facts.
We find that Evaluator LLMs are more reliable than Soap Note Generation Systems
for the simple reason that they are doing much simpler work with much more focus.
They are generally focused on one, or a small number, of facts at a time. This
allows us to build confidence in the Evaluators faster than in the Note Generation
Systems themselves.
Conclusions
AI Scribing is a large and growing industry. It seems inevitable that it will be the
standard form of data entry for many medical specialties including Primary Care. Every
citizen has a stake in its quality and reliability.
AI Scribing offered in a Certified EHR Technology (CEHRT) most likely falls into the
regulatory category from the Office of National Coordinator for Health IT (ONC) of
Predictive Decision Support Interventions: “technology that supports decision-making
based on algorithms or models that derive relationships from training data and then
produces an output that results in prediction, classification, recommendation,
evaluation, or analysis”. As such, it is subject to certain documentation and
transparency requirements, but not any task-specific quality standard. Regulators
have
not established discrete requirements due to rapidly evolving technology functions.
The
requirements for transparency do include validity, evaluation, and regular testing,
but
the regulators do not define what constitutes sufficient testing or a passing score.
As AI in health care emerged, US Health and Human Services (HHS) established baseline
requirements which included a wide net approach to provide flexibility of CEHRT vendors
to establish AI tools with a wide range of transparency requirements applicable to
multiple technology use cases. The regulations have already begun to be refined (the
second proposed update to the HTI regulations have been released) and the ONC and
HHS
have stated the intention to refine regulations as the technology is refined and better
understood over time.
In the meantime, we as vendors must proactively evaluate our own technologies to
minimize patient risk and clinician effort. In fact, we will always want to exceed,
rather than just meet, whatever standards are imposed by regulation. To meet this
challenge, Elation Health has made large investments in both automated and human
evaluation, and plans to continue doing so.
Using this mix of automated and human evaluation we have built a feedback loop wherein
the automated tests progressively approach parity with human feedback, which allows
our
experts to focus on increasingly strict definitions of SOAP note quality.