Sperberg-McQueen, C. M. “From Word to XML via iXML: a Word-first XML workflow in the TLRR 2e project.” Presented at Balisage: The Markup Conference 2024, Washington, DC, July 29 - August 2, 2024. In Proceedings of Balisage: The Markup Conference 2024. Balisage Series on Markup Technologies, vol. 29 (2024). https://doi.org/10.4242/BalisageVol29.Sperberg-McQueen01.
Balisage: The Markup Conference 2024 July 29 - August 2, 2024
Balisage Paper: From Word to XML via iXML
a Word-first XML workflow in the TLRR 2e project
C. M. Sperberg-McQueen
Founder and principal
Black Mesa Technologies LLC
C. M. Sperberg-McQueen is the founder and principal of
Black Mesa Technologies, a consultancy specializing in helping
people use XML technologies.
He served as editor in chief of the TEI Guidelines from
1988 to 2000, and has also served as co-editor of the World
Wide Web Consortium’s XML 1.0 and XML Schema 1.1
specifications.
In a rebooted project to produce a second edition of
Michael Alexander’s reference work Trials in the Late
Roman Republic, 149 BC to 50 BC, revisions arrive
from the editors in Microsoft Word documents. Invisible XML
grammars are used to identify and mark up the fields of each
trial record, the macrostructure formed by groups of fields, and
the microstructure of information units within field values,
such as references to ancient authors. For many structures to
be identified, an Invisible XML description of the pattern is
more compact and easier to understand than the equivalent in
XSLT or XQuery; the tradeoff is that processing XML input with
invisible XML entails a certain amount of overhead.
Trials in the late Roman Republic, 149 BC to 50
BC (Alexander 1990)
is, in the words of its author, a tabulation of “the known legal facts
pertaining to the 391 trials and possible trials, criminal and civil,
which date from the last century of the Roman Republic, and about
which some information has survived.” For each trial, the book
records (if known) the date, the charge or claim made, the defendant,
their advocate(s), the prosecutor(s) or plaintiff(s), the presiding
magistrate, the jurors, the witnesses, other individuals involved in
the case, the verdict, and other salient information.
The TLRR2e project is creating a second edition of this reference
work, to be published online. An earlier effort in this direction
(here called TLRR2) was reported on by Sperberg-McQueen 2016 but bore no fruit;
TLRR2e is a reboot of the effort with new editors.
The material consists of a series of distinct trial records and so
invites treatment as a database. The information is fragmentary and
highly variable in structure, which further suggests an XML database
rather than a relational one.
This paper describes the workflow being developed for the project,
with special emphasis on the use of invisible XML to assist the
transformation from Microsoft Word to a conventional semantically rich
XML vocabulary. The historians editing the second edition start with
a copy of the first edition which has been transformed into Word
format, make their changes, and submit them to the technical staff in
batches of a few tens of trials for processing. The technical staff
(that is, the author) is then responsible for transforming the
material into XML suitable for querying and display.
The work is performed in several stages, each of which may involve
multiple steps:
An XML document in WordML is extracted from the Word file.
An XSLT stylesheet transforms it into a rudimentary XML in a more
conventional XML style, preserving paragraph breaks, boldface, and
italics, but discarding other information in the Word file since it
carries no meaning in these files.
For simplicity, this form is called RXML (for ‘rudimentary XML’).
An invisible-XML processor then parses the RXML data using a series of
grammars which describe the organization of the material in ever finer
detail, ending with XML in which trial records are represented as
trial elements containing a flat sequence of fields with
element names like date, charge,
defendant, and so on.
The output of this process, with trials and data fields explicitly
marked and labeled, we’ll call FXML (for ‘fielded XML’).
Another invisible-XML grammar describes the macro structure of a
trial record; the macro structure groups fields into larger
structures so that (for example) a defendant and the defendant’s
advocate and witnesses are in one group, and the plaintiff and the
plaintiff’s advocates are in a different group.
An iXML processor reads the FXML using this grammar and produces a
form we’ll call ‘macro XML’ (MXML).
Within the macro XML, many fields contain micro-structures that need
to be identified and marked up: names of people, references to
ancient sources, bibliographic references to modern scholarship,
hyperlinks to other trials, and so on.
For each of these, invisible XML grammars will be written to
identify the micro-structures and capture them with XML markup.
The reader may correctly observe that all of these transforms could
also be done without iXML, by writing a pipeline of XSLT or XQuery
transformations. The author is well aware of this, having processed
the data from the first edition of the work in precisely that way.
Invisible XML grammars often allow us to describe the patterns to be
recognized more simply and cleanly, although applying iXML grammars to
XML, and especially to XML with mixed content, poses some challenges
which will be mentioned here and there in the paper.
2. The starting point: TLRR in Word
format
The editors have chosen to do their work in Word, keeping the
layout and field labeling (that is, the presentational markup) of the
first edition.
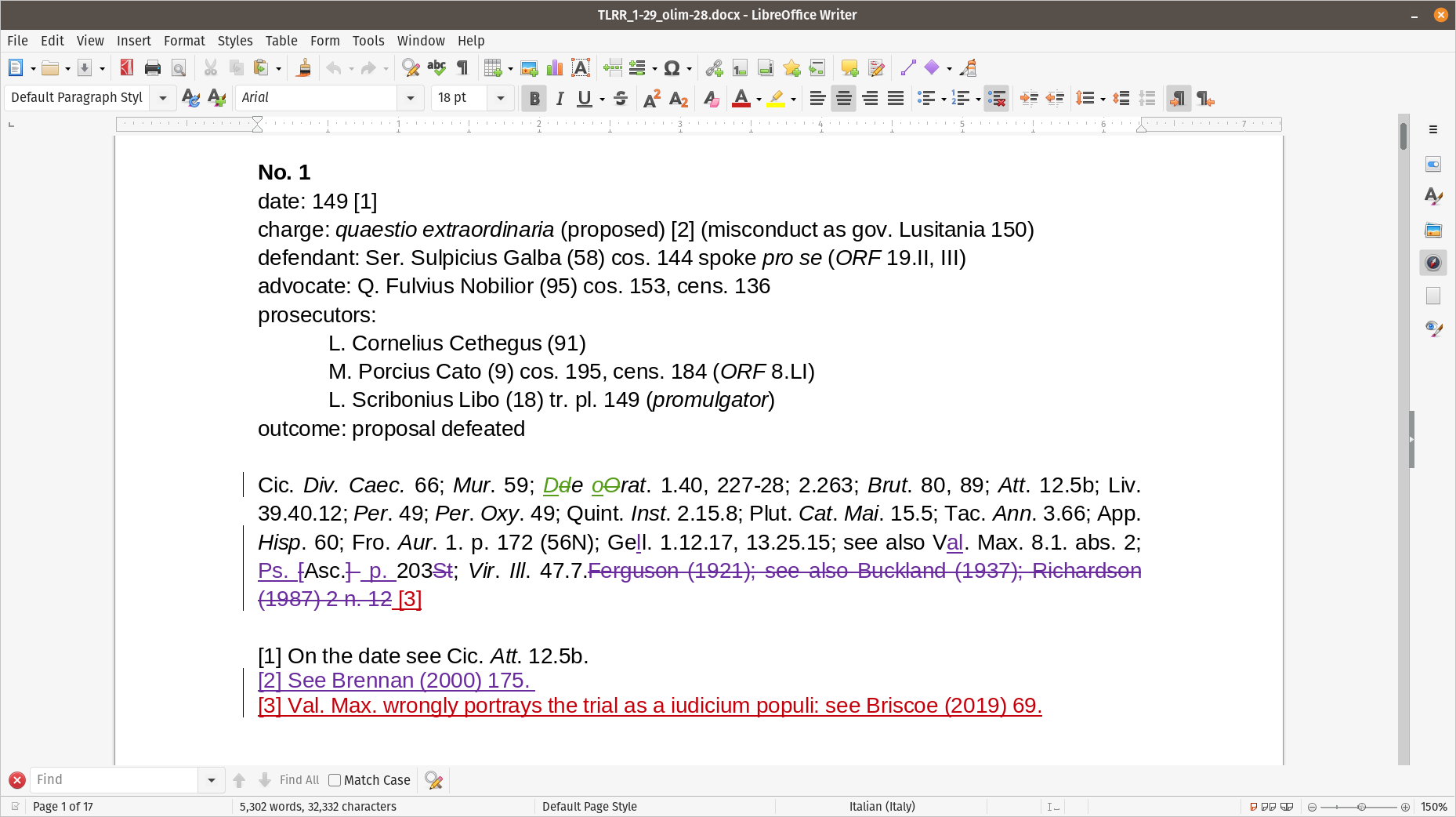
The following image shows the record for the first trial in
Libre Office Writer, with changes from the first edition marked. The
color coding provided by the word processor shows which editor made
which changes.
Figure 1
As most readers of this paper are likely to know already, Word
files with extension .docx are zipped archives with an internal file
system containing a variety of sub-files with different information
about the document. What most people will think of as the document
“itself” is in one of those files (document.xml in this case), tagged in XML using
the WordML / WordprocessingML vocabulary.
The first few lines of Trial #1 in this form are shown below.
This is not the place for a serious introduction to WordML (nor
am I competent to provide one), but some salient points should be
noted. These apply to the data received from the editors, even if (as
I have been warned by people I trust) not necessarily to all Word
documents found in the wild.
Each paragraph is tagged as a
w:p element (where w is bound to the
namespace URI
http://schemas.openxmlformats.org/wordprocessingml/2006/main)
and contains a series of text runs tagged as w:r
elements. A run is just a sequence
of zero or more characters which share the same properties; if
adjacent characters have distinct properties, they will be in
different runs, but having the same properties does not guarantee that
they will be in the same run.
Paragraph properties are recorded in a
w:pPr element which is the first child of the
w:p element; the properties of a run may (optionally)
similarly be given in a first child named w:rPr. An
italicized run, for example, has an empty w:i element as
a flag in the run properties, as may be seen in the charge field of the record shown above for the
string “quaestio
extraordinaria”. When the entire paragraph is bold,
an empty w:b element is found in the paragraph
properties.
The characters actually displayed as part of the
document occur as character data children of w:t elements
within a w:r.
For a fuller introduction to the XML form of Word, the overview
by Evan Lenz (Lenz 2004) is
useful, although in some respects now outdated by changes in the
format.
It will be noted that there is no mixed content in this format.
To put it in XPath terms: no text node has an element node as a
sibling.
When changes are marked, individual text runs are wrapped in
w:ins and w:del elements. Inside a
deletion, the text run contains not a w:t child but a
w:delText child.
In the list of ancient citations for this trial, one of the
editors has changed the reference to Cicero’s “de Orat. 1.40 227-28; 2.263” to read
“De orat. 1.40 227-28;
2.263” by deleting the d and
O and inserting D and o in
their places. The corresponding XML is shown below; whitespace has
been added to aid legibility.
In earlier work (reported in Sperberg-McQueen 2016), the author has
translated the first edition of TLRR into XML, first converting the
Waterloo Script files used to produce the camera-ready copy for the
book into XML with identical semantics, and then using a pipeline of
XSLT stylesheets to enrich the tagging. At the same time, the author
devised an XML vocabulary tailored to the information in the work and
designed to support useful searches and flexible display of results.
Here are the first few lines of trial #1 in the first edition as
represented in that vocabulary.
The challenge to be met by the workflow described here is to
get from the starting point to something resembling the tagging just
shown. (At a first approximation, the goal is to use the same
vocabulary, but there may be reasons to deviate from it.)
The salient properties of the TLRR XML format include these:
Each trial is divided into fields.
Each field is tagged with a meaningful name: trial,
date, charge, defendant, and so
on.
In the pipeline described here, this markup is added in the
second stage, which produces the FXML form of the data.
Fields are grouped in meaningful ways; by listing
Q. Fulvius Nobilior (95) immediately after the defendant and before
the prosecutors, TLRR signals that Fulvius was the advocate for the
defendant; the XML records this by grouping them in a
defGrp (defendant group) element.
In the pipeline being constructed, this is achieved in the MXML
format in the third stage.
Person names are identified and hyperlinked to an
index of persons.
In the pipeline described here, this markup is added in the
fourth and final stage.
Not visible here, but ancient sources are recognized
and tagged with the author, the work, and the passage (so that if
desired they can be hyperlinked to online editions which support
lookup by canonical references).
This markup, too, is added in the fourth stage.
Endnotes are given at the point of attachment to the
base text.
This property of the initial XML form created from the first
edition of TLRR may be replicated in the fourth stage, or it may be
abandoned (in which case routines for checking and adjusting note
numbers will be needed).
One approach to getting TLRR2e data into this format would be
to start from this format — to produce the second edition by
editing the existing XML representation of the first edition. That
was the original plan (editors would provide a list of changes,
technical staff would edit the XML), but the first batch of results
from the editors showed that the volume of changes was high enough to
make that approach error prone as well as tedious. So we want to
start from the editors’ Word documents and produce XML marked
up in the style shown.
We will proceed stage by stage.
4. Step 1: WordML to Rudimentary
XML
Experience with the XML conversion of the first edition showed
that XSLT could recognize and process the structural patterns of the
data, but that the expression of the patterns was often bulky and
sometimes obscured by artifacts of XSLT. Work on the TLRR2e workflow
starts from the observation that many of the relevant patterns are
easy to express in grammatical form and with the conjecture that
invisible-XML grammars may provide a more compact and more easily
manageable way of bringing out the structure expressed by
presentational markup like line breaks, in-text labels, font shifts,
and the like.
So we would like to use an invisible-XML grammar to parse the
input.
A complication immediately arises: Word files are XML documents
using a WordprocessingML vocabulary, and invisible XML is designed for
processing straight textual data, not XML. It is in principle
possible to parse well-formed XML with an invisible-XML grammar (as
illustrated in Hillman et
al. 2022), and we will exploit that fact in later stages of
the workflow, but the presentational markup of TLRR data is rather
obscured, in the WordprocessingML format, by the very high incidence
of markup conveying information that is important for Word but
contributes no information of use to us. An invisible-XML grammar
designed to read the Word file directly would devote most of its
attention to throwing information away.
Most of the presentational markup relevant for our purposes
would still be available in a text-only version of the file in which
the paragraph boundaries of the Word document are mapped to line
breaks in the textual form. That document would be far easier to
parse with invisible XML.
Unless special steps are taken, however, the italics and bold
of the Word document — which do convey meaning — would
be lost along with all the information we would be happy to lose. A
simple wiki-style markup could preserve paragraph breaks and font
shifts and remove all the other complications. It might look like
this (using *...* to mark bold and /.../ to
mark italics):
*No. 1* date: 149 [1] charge: /quaestio
extraordinaria/ (proposed) [2] (misconduct as gov. Lusitania 150)
defendant: Ser. Sulpicius Galba (58) cos. 144 spoke pro se (ORF 19.II,
III) advocate: Q. Fulvius Nobilior (95) cos. 153, cens. 136 ...
This approach was contemplated for a while. But without a
thorough search through the book — including the trials not yet
delivered by the editors — it’s hard to be confident
that there won’t be any asterisks or slashes in the input which
do not mark italics or bold and need to be preserved. Rather than
seek to invent some sort of escaping mechanism on the fly, it seems
simpler to use simple XML markup to mark italic and bold. If an XSLT
stylesheet is used to convert the Word file into a rudimentary XML
format, any left angle brackets and ampersands will be escaped and all
will be well.
If we are going to use a rudimentary XML format as our first
step, we might as well use markup to capture the paragraph boundaries
and record indentation as well. A document schema for the rudimentary
XML (RXML) to be produced would be:
<!ELEMENT TLRR-rudimentary-XML (p+)
> <!ELEMENT p (#PCDATA | i | b)* > <!ATTLIST indent CDATA
#IMPLIED > <!ELEMENT i (#PCDATA | b)* > <!ELEMENT b
(#PCDATA | i)* >
In this RXML format, the first few lines of Trial #1 will look
like this:
The value of the
indent attribute is taken direct from the
WordprocessingML, which records indentation in one-twentieths of a
point. So the names of the prosecutors are indented half an inch.
The exact amount does not matter, but if the editors produce any
nested lists the relative amounts will be important.)
It should be noted that another alternative was also
considered: using the HTML export facility of the word processor and
processing the HTML. The HTML thus produced is simpler than the
WordprocessingML (and far simpler than HTML produced by word
processors in years gone by), but it is also much more complex than
the RXML form shown above, in part because it faithfully records a lot
of information present in the Word file which has no significance for
TLRR.
The main advantage to be gained by using the HTML export would
be to make it unnecessary to write any code for this first stage of
the pipeline. But the advantage is very small. The wordml-to-rxml.xsl stylesheet is simple enough
that it took very little time to implement. It has only seven
templates:
one for the document node, which
inserts a TLRR-rudimentary-XML element;
one for w:p elements which writes out a
p element, adding an indent attribute if
indentation is detected in the paragraph properties;
three for runs, which detect the presence of the bold
property, the italic property, or both, and insert a b
element, an i element, or both;
two for w:ins and w:del
elements, to map them into ins and del
elements in the output. (This has thus far proved to be a dead end:
the change markup complicates things enough that the current version
of the pipeline simply ignores it: comparisons of the first and second
editions can be performed later field by field.)
So the cost of using a bespoke transformation is in the case
very low (much lower than the cost of complicating subsequent steps by
requiring them to deal with the HTML exported by the word processor).
5. Stage 2: Rudimentary XML to
Fielded XML
The next stage is to capture the overall structure of the
input, and in particular to translate the presentational markup for
labeled fields into corresponding XML markup. To take a concrete
example: the RXML element <p>date: 149
[1]</p> should be transformed into <date>149
[1]</date>. Some of the microstructure can also be
recognized easily, so in practice the reference to note 1 is
recognized and tagged, and the element is rendered as
<date>149 <ref>1</ref></date>.
5.1. Goals of stage 2
More explicitly, the goals in this stage are:
to recognize the boundaries of trials
and tag each trial as a trial element;
to recognize the list of references at the end of the
batch of trials and tag the references as bibl
elements;
within each trial, to
recognize the boundaries of labeled fields and tag each field with an
appropriate element; the element type name will usually but not always
match the label found in the input, and when it doesn’t, the
label should be recorded as an attribute;
within each trial, to recognize the (unlabeled) notes
and references to ancient and modern sources;
in fields whose value is a list of names, to recognize
the structure of the name list.
Recognizing the internal structure of bibliographic references,
names, dates, etc. is not a goal for this stage.
It is neither a goal nor a non-goal to eliminate empty
paragraphs. They may be retained if it seems likely to be useful, or
dropped if no longer useful. (They are useful in recognizing the
references to sources, because the references are consistently
preceded by at least one blank line.)
It proved helpful to break this stage up into a sequence of
three steps, each building on the work performed by the preceding.
Two intermediate formats are thus introduced between the RXML and the
FXML formats described above; since in them the markup identifies
fields in a more generic way, these two intermediate formats are
called gfxml0 and gfxml1, for ‘generic-fielded XML’
stages 0 and 1.
5.2. Step 1: categorize
paragraphs
The rxml-to-gfxml0 grammar describes the input as a
series of chunks (all tagged p in the input), some of
which can be identified as (section) titles, some as trial numbers,
some as labeled fields; some cannot be identified as a special kind of
chunk at all, and appear as p elements in the output,
unchanged from the input.
5.2.1. Top-level rule in the
grammar
A simplified version of the top-level grammar rule in this
grammar is:
That is, the input consists of a start-tag for the element
TLRR-rudimentary-XML, a series of things (in practice,
all p elements) we will recognize as paragraphs or
fields, and an end-tag for the TLRR-rudimentary-XML
element. The heart of the grammar will lie in the rule para-or-field and its descendants.
In reality, however, as examination of the full grammar (given
as an attachment) will show, the rule actually used is more
complicated. Depending on the process used to produce the RXML input,
the input may or may not have an XML declaration. And the elements in
the input will typically be separated by whitespace, for legibility.
We will need to add rules to recognize them, and refer to those rules
from this one. And, finally, we would like to make the output more
legible by injecting line breaks before the series of
paragraphs-or-fields and after each individual paragraph-or-field.
Making all these things explicit in the rule adds some visual clutter
in the form of references to the nonterminals xml-declaration, s (for optional whitespace), and inject-NL (which matches the empty string and
inserts a newline character into the output), so the rule takes the
following form.
The grammar distinguishes four varieties of paragraph-or-field,
as indicated in the following rule.
-para-or-field = title | trial-number
| field | p .
The mark “-” on the left-hand side
indicates that the nonterminal will not be serialized as an element,
so there won’t be a series of elements named
para-or-field. (A significant part of the design effort
involved in developing an iXML grammar for data one wants to work with
lies in choosing which nonterminals should be serialized as elements,
which as attributes, and which should be hidden, like para-or-field.)
Trial
numbers
A trial number (as may be seen in the
examples given above) appears in RXML as a bolded paragraph with
character data content like “No. 22”. This
is easily represented as a grammar rule. Since only the number
carries useful information and the string “No. ” can be
supplied at display time, we signal with a
“-” mark on the literal string that it
should be omitted from the output.
trial-number = -"<p><b>No. ", [N]+,
-"</b></p>".
The character class
“[N]” matches any Unicode numeral digit.
In this input, only the Western form of the Indo-Arabic digits will
appear, so this could also be written
“["0"-"9"]”. The shorter and more general
form is used for convenience in typing; since there is no likelihood
that those preparing the input will inadvertently use any other form
of digit, there is no point in checking that only Western digits are
used.
Titles
Any other bolded paragraph we will tag as a title. The
simple way to do this would be similar to the preceding:
title = -"<p><b>",
~["<>"]*, -"</b></p>".
This, however, would render the grammar ambiguous, since every
paragraph that matches the rule for trial number would also match this
rule for title. Unlike XSLT, formal grammars as defined in computer
science have no system of priorities to specify which rule applies if
more than one rule matches the input. Some grammar notations do have
various more or less ad hoc mechanisms for resolving ambiguities, and
some iXML processors have extensions for that purpose.
In this case, the task of rendering the grammar unambiguous is
relatively simple; it requires only a little bit of boilerplate
following a standard pattern. Every bolded paragraph should be
classified as either a trial-number
or a title — how can we decide
which?
If it begins with a nested element (the
only candidates are b and i), then it is a
title.
Otherwise, if it does not
begin with “N”, it is a
title.
Otherwise, if it begins with
“N” but stops there or continues with a
character other than “o”, then it is a
title.
Otherwise, if it begins with
“No” but stops there or continues with a
character other than “.”, then it is a
title.
Otherwise, if it begins with
“No.” but stops there or continues with a
character other than a space, then it is a title.
Otherwise, if it begins with “~No. ~”
but stops there or continues with a character other than a numeric
digit, then it is a title.
Otherwise, if it begins with “~No. ~”
followed by one or more numeric digits, but does not stop there and
continues with additional characters, then it is a
title.
Otherwise (as the reader will
perceive), it contains the string “No. ”
followed by a series of numeric digits, which means it matches the
rule for trial-number, and it is a
trial number and not a title.
This logic can be captured compactly in a grammatical rule.
The nonterminal para-bit denotes
phrase-level material (a small bit of a paragraph).
(In practice, the rule given also generally excludes angle
brackets at various points. That’s probably unnecessary and
inconsistent.)
Similar logic will be called for in any situation in which two
distinct classes of inputs must be distinguished, and the rule for one
of them (here title) is most simply
expressed as anything that matches a fairly simple description, unless
it also matches a competing description of higher priority (here
trial-number). In language-theoretic
terms, what we want is for trial to be the set of all bolded
paragraphs, after the set of all trial numbers is subtracted: in set
notation bolded-paragraph \ trial-number. When both sets are regular
languages, the set difference is also guaranteed to be a regular
language, so in that case there is always a way to describe the
desired set, even if (as shown above) the expression requires more
machinery.
An extension to iXML to include a set-subtraction operator (and
possibly also a set-intersection operator) would make this grammar
somewhat simpler to write and understand. So would some mechanism for
assigning priorities to nonterminals or rules, or more generally for
resolving ambiguity.
Labeled fields
A labeled field is a paragraph whose content begins with a
label, which is a sequence of lower-case letters possibly italicized
and possibly containing blanks, followed by a colon and then a value
for the field. Sometimes a note-reference precedes the value, and
must also be recognized. The grammatical rule is this:
field = -"<p>", label, s,
(note-ref, s)?, value?, -"</p>" .
A note reference is just a number in square brackets.
note-ref = -"[", [N], -"]".
Only a single digit is allowed, because no individual trial has
ten end-notes.
The definition of label is
complicated a bit by the observation that in working with input
produced in Word we cannot reliably assume either that the colon after
an italicized label will always be italicized, or never be italicized;
we need to accept either form.
In a labeled field, the colon after the label is followed by
whitespace, so a simple definition of value would be any series of paragraph-bits
that begins with a non-whitespace character.
value = ~[" <>"], para-bit+.
However, it is not unusual, in word-processing files, to see a
blank preceding or following an italicized phrase marked as itself
italic, as in the following field from trial #2:
<p>charge:<i> iudicium populi</i>,
for <i>perduellio </i>[1] (failure as commander in Farther
Spain)</p>
This could easily be saved
for a later cleanup stage, but it broke the first attempt at a rule
for value, so a more complicated set
of rules was written to detect the case and ensure that the whitespace
at the beginning of the value was suppressed. (The blank after the
Latin term perduellio remains,
awaiting that later cleanup stage.)
The two rules at the end of that code block exploit a feature
added to iXML after the publication of version 1.0: they specify that
the nonterminals i-no-leading-blank
and b-no-leading-blank should be
serialized in the output as i and
b elements. That allows us to write
nonterminals to recognize special cases of italic and bold, which
require special handling (here, the suppression of initial whitespace
within the element), without having those nonterminals appear in the
output as distinct element names.
Other
paragraphs
Any paragraph which is not one of the above should be copied to
the output, tagged p. This includes empty elements, and
indented paragraphs in the input.
The definition of unlabeled-content is complicated by the need to
exclude any sequence of characters beginning with a sequence of
lowercase letters and blanks terminated by a colon, with or without
italics. The interested reader will find it in the full grammar in
the attachment.
5.2.3. The data after step 1
The result of parsing the RXML form of the data with the
rxml-to-gfxml0 grammar can be
illustrated by the beginning of the file, up through the trial number
for trial #2. Line breaks have been introduced in long paragraphs, to
simplify display. In the actual data, each field and
each p element occupies a single line.
<TLRR-generic-fields-0
xmlns:ixml="http://invisiblexml.org/NS"
ixml:state="version-mismatch"> <title>TLRR (2)</title>
<p/> <p/> <trial-number>1</trial-number>
<field><label>date</label><value>149
[1]</value></field>
<field><label>charge</label><value><i>quaestio
extraordinaria</i> (proposed) [2] (misconduct as gov. Lusitania
150)</value></field>
<field><label>defendant</label><value>Ser. Sulpicius
Galba (58) cos. 144 spoke <i>pro se</i>
(<i>ORF</i> 19.II, III)</value></field>
<field><label>advocate</label><value>Q. Fulvius
Nobilior (95) cos. 153, cens. 136</value></field>
<field><label>prosecutors</label></field>
<p indent="720">L. Cornelius Cethegus (91)</p> <p
indent="720">M. Porcius Cato (9) cos. 195, cens. 184
(<i>ORF</i> 8.LI)</p> <p
indent="720">L. Scribonius Libo (18) tr. pl. 149
(<i>promulgator</i>)</p>
<field><label>outcome</label> <value>proposal
defeated</value></field> <p/> <p>Cic.<i>
Div. Caec.</i> 66; <i>Mur</i>. 59;
<i>D</i><i>e
</i><i>o</i><i>rat</i>. 1.40, 227-28;
2.263; <i>Brut</i>. 80, 89; <i>Att</i>. 12.5b;
Liv. 39.40.12; <i>Per</i>. 49;
<i>Per</i>. <i>Oxy</i>. 49;
Quint. <i>Inst</i>. 2.15.8;
Plut. <i>Cat</i>. <i>Mai</i>. 15.5;
Tac. <i>Ann</i>. 3.66; App. <i>Hisp</i>. 60;
Fro. <i>Aur</i>. 1. p. 172 (56N); Gell. 1.12.17, 13.25.15;
see also Val. Max. 8.1. abs. 2; Ps. Asc. p. 203;
<i>Vir</i>. <i>Ill</i>. 47.7. [3]</p>
<p/> <p>[1] On the date see
Cic. <i>Att</i>. 12.5b.</p> <p>[2] See Brennan
(2000) 175. </p> <p>[3] Val. Max. wrongly portrays the
trial as a iudicium populi: see Briscoe (2019) 69.</p>
<p/> <p/> <trial-number>2</trial-number> ...
Several things are worth noting about this output:
Information about a single trial is not
grouped into a single containing element; the fields pertaining to
each trial still need to be gathered into a trial
element.
The prosecutors
field of trial #1 has a value consisting of a list of names, each in a
separate paragraph in the WordprocessingML and RXML data.
That list of names needs to be tagged and brought into the
field element for the prosecutors.
In each trial, the list of ancient sources and the
notes need to be recognized and tagged.
The lists of abbreviations and bibliography at the end
of the input (not shown above, and not discussed in detail below) need
to be wrapped in containers, and the individual items in each list
need to be tagged appropriately.
The next step is devoted to addressing these issues. A further
peculiarity visible in the data may be noted but will not be addressed
yet:
At some points, a sequence of italic
characters is not marked by an i element but by a
sequence of two or more adjacent i elements; this will
complicate later processing and will need to be cleaned
up.
5.3. Step 2: field-boundary
fixup
5.3.1. Goals of step 2
The second step in this stage has the primary task of detecting
cases where a given field takes up more than one paragraph in the RXML
form. Since fields are recognized only by having a label at the
beginning, any paragraphs beyond the first will have been left
unchanged by the preceding step. Sometimes this is due to the value
containing a list of names, as illustrated by the prosecutors field of trial #1; sometimes
it’s the result of an erroneous hard return in a field value,
as in the following example from trial #8:
<field><label>charge</label><value><i>lex
</i>(<i>Calpurnia</i>?) <i>de
repetundis</i> (misconduct as consul
and</value></field> <p>proconsul in Hither Spain)
[2]</p>
At the same time, the grammar recognizes the notes and the
lists of ancient and modern sources appearing at the end of each
trial, and groups and tags the back matter in the input.
5.3.2. Organization of the input,
organization of individual trials
The key drivers here are the definition of the top level of the
document and the definition of trial.
The top level defines the body of the document as consisting of a work
title followed by a series of trials, followed by a list of
abbreviations and a bibliography, with sections optionally separated
by blank lines.
Since the abbreviations and bibliography begin with distinctive
titles, they are not recognized solely by position. But some material
within a trial is recognized by
position. Neither the sources of a
trial nor the notes have distinctive
markup (although notes do begin with note numbers, which proves
important); the rule for a trial
recognizes them, essentially, by their position. The input
consistently (at least so far!) separates the sources from the
preceding labeled fields with one or more blank lines (represented at
this point by empty p elements).
In the input to this step, individual fields can take any of
three forms. Most common is a field element and nothing
more, as illustrated by the first right-hand side of the field rule below. The second form has a
list-structured value, where the first paragraph has only the label
(and optionally a note references), and the actual value is recorded
in a series of indented paragraphs immediately following. In the
third form, the value spills to one (or possibly more) following
p elements.
A note on the first line of the rule above: Defining the
nonterminal field as a string
beginning with an XML start-tag for a field element and
ending with an end-tag for that element is the iXML equivalent of an
identity transformation on the field element. (Unlike
XSLT, iXML does not have the equivalent of a generic identity
template, or a default mode="shallow-copy" treatment:
every element to be treated must be given a rule. That means there
are tradeoffs to consider in deciding whether to process XML data with
iXML or with XSLT or XQuery. In the workflow described here, the
markup is simple enough that providing identity rules is not a big
burden. But as the markup becomes richer, the burden of providing the
identity rules increases.)
The rules for label, note-ref, and value are also identity rules.
For list-valued fields, we would like to wrap the value in a
value element, as usual, and then within that wrap the
list items in a list element. That leads to the
following slightly indirect-looking set of rules. (Some inject-NL references have been deleted here to
make the rules a little easier to read.) Any indented paragraph we
see is a list item. The exact value of the indentation does not
matter, because the input has no nested lists.
list-value > value = value-list.
value-list > list = item++s. item = -"<p indent=",
-~["<>"]*, -">", phrases, -"</p>".
An ‘extended’ value, on the other hand, spills
not to indented paragraphs but to unindented paragraphs, as shown in
the following rule.
extended-value > value =
-"<value>", phrases, -"</value></field>", s,
(-"<p>", +" ", phrases, -"</p>") ++ s.
Because the rule for trial
specifies that the main body of a trial consists of a sequence of
fields separated only by whitespace, every p element
following a field element in the input will be absorbed
into that field. (To do this in XSLT, it is necessary to perform what
is sometimes called a right-sibling traversal, which many XSLT
programmers report finding difficult to get right — or use
grouping constructs, which are somewhat easier to get right.) An
attempt was made to make the grammar of the preceding step detect such
multi-paragraph fields and handle them correctly, but the attempt
failed, because the higher-level nonterminal had defined the document
as a sequence of fields and paragraphs, so every multi-paragraph field
could be read as a single field or as a field followed by paragraphs.
Both were allowed, so the grammar became ambiguous, and no way was
found to force one reading over the other. (It is, probably, not
impossible. But no solution was found in the time available.)
5.3.4. Phrase-level information and
well-formed XML
It may be worth spending a moment on the phrases nonterminal and on the handling of
phrase-level content within fields and notes.
The nonterminal phrases
matches zero or more occurrences of:
a character other than an angle
bracket;
a note
reference;
an i
(italics) element;
a b
(bold) element;
empty i
and b elements which enclose no characters and thus serve
no purpose other than to complicate downstream processing; like start-
and end-tags that put whitespace that belongs outside an element
inside that element, such empty elements are not uncommon in
word-processor documents.
-phrases = phrase*. -phrase =
~["<>"] | note-reference | i | b | cruft.
note-reference > note-ref = "[", [N], "]". i = -"<i>",
phrases, -"</i>". b = -"<b>", phrases, -"</b>".
-cruft = -"<i/>"; -"<b/>".
The grammar also includes rules for structuring the
abbreviations and bibliography; they are present in the attached
grammar but will not be discussed here.
5.3.5. The data after step 2
The beginning of the data now shows the restructuring of the
information. (Reformatted for legibility.)
<TLRR-generic-fields-1
xmlns:ixml="http://invisiblexml.org/NS" ixml:state="ambiguous
version-mismatch"> <title>TLRR (2)</title>
<trial n="1"> <field><label>date</label>
<value>149
<note-ref>[1]</note-ref></value></field>
<field><label>charge</label>
<value><i>quaestio extraordinaria</i> (proposed)
<note-ref>[2]</note-ref> (misconduct as gov. Lusitania
150)</value> </field>
<field><label>defendant</label>
<value>Ser. Sulpicius Galba (58) cos. 144 spoke <i>pro
se</i> (<i>ORF</i> 19.II, III)</value>
</field> <field><label>advocate</label>
<value>Q. Fulvius Nobilior (95) cos. 153,
cens. 136</value> </field>
<field><label>prosecutors</label>
<value><list> <item>L. Cornelius Cethegus
(91)</item> <item>M. Porcius Cato (9) cos. 195, cens. 184
(<i>ORF</i> 8.LI)</item> <item>L. Scribonius
Libo (18) tr. pl. 149 (<i>promulgator</i>)</item>
</list></value></field>
<field><label>outcome</label> <value>proposal
defeated</value> </field> <sources>
<ancient>Cic.<i> Div. Caec.</i> 66;
<i>Mur</i>. 59; <i>D</i><i>e
</i><i>o</i><i>rat</i>. 1.40, 227-28;
2.263; <i>Brut</i>. 80, 89; <i>Att</i>. 12.5b;
Liv. 39.40.12; <i>Per</i>. 49;
<i>Per</i>. <i>Oxy</i>. 49;
Quint. <i>Inst</i>. 2.15.8;
Plut. <i>Cat</i>. <i>Mai</i>. 15.5;
Tac. <i>Ann</i>. 3.66; App. <i>Hisp</i>. 60;
Fro. <i>Aur</i>. 1. p. 172 (56N); Gell. 1.12.17, 13.25.15;
see also Val. Max. 8.1. abs. 2; Ps. Asc. p. 203;
<i>Vir</i>.
<i>Ill</i>. 47.7. <note-ref>[3]</note-ref>
</ancient> </sources>
<notes> <note>[1] On the date see
Cic. <i>Att</i>. 12.5b.</note> <note>[2] See
Brennan (2000) 175. </note> <note>[3] Val. Max. wrongly
portrays the trial as a iudicium populi: see Briscoe (2019)
69.</note> </notes> </trial> ...
5.4. Step 3: retagging the
fields
5.4.1. Goal of step 3
At this point, the field structure of the input has been
cleanly recognized. For further work, it will be more convenient if
each type of field has a distinctive element type, rather than being
tagged generically as a field with a label
and value. So the sole purpose of this step is to retag
the fields, using the value of the label as a guide.
For some fields, this is a simple matter of using the value of
the label as the generic identifier for the element. So the date
field of trial #1 (reformatted here to shorten lines)
will be retagged more
informatively and compactly as
<date>149 <note-ref>[1]</note-ref></date>
For other fields, the retagging is more complex. A survey of
the first-edition data shows that the field which records the
presiding magistrate in a trial, which will be tagged as a
judge element, may in the displayed text be labeled in
any of several different ways, often simply recording the Latin term
used in the historical sources, and sometimes recording some
uncertainty:
praetor
peregrine
praetor
peregrine?
praetor
urban
praetor
(urban?)
praetor
urban and peregrine
praetor
quaesitor
quaesitores
iudex
quaestionis
praetor or iudex
quaestionis
aedile or iudex
quaestionis
…
The variations in the label are, needless to say, important to
preserve, even as all variations on the theme of “presiding
magistrate𣀝 are merged into a single element type in order to
support searches to find out whether a particular named individual is
ever recorded as having presided over a trial.
<judge label="praetor"> M. Popillius Laenas (22) (pr. by 142)
cos. 139? <note-ref>[1]</note-ref> </judge>
5.4.2. Recognizing fields
In this grammar, again the input is recognized as a series of
trials, and each trial as a sequence of fields. The main work occurs
in the rule describing fields, which classifies them by type.
As may be seen for some fields such as date, there is only one form of label, and
it’s given as a literal. For others such as judge, the description of matching labels is
packaged in a separate nonterminal such as label-judge, which we give here as a typical
example:
The effect of these grammar rules may be worth describing step
by step in a procedural way. At any point where the grammar is
expecting a field of any kind, the parser looks to see if the input
matches the rule for field, which in
turn translates to looking to see if the input matches the rule for
date or charge or any of the other nonterminals on the
right-hand side of the rule for field, including judge. If the input does match the rule for
field, it will not be tagged as a
field element in the output because the left-hand side of
the rule is marked with a minus sign, meaning that the nonterminal
field is to be hidden. Its children
may be tagged, but not the nonterminal as a whole.
Matching the rule for judge
requires a field element with contents matching the
sequence of nonterminals label-judge,
optionally note-ref, and value. If the input matches here, it will
appear in the output as a judge element. Operationally
speaking, we have thus used the iXML grammar to replace a
field element with a corresponding judge
element.
If the label child of the field we
are processing has the form
“<label>praetor</label>”, then
it will match the nonterminal label-judge, which is hidden, and also the
nonterminal judge-label which is (a)
marked with “@”, which means it will be
serialized as an attribute, and also annotated with “>
label”, which means that the attribute will be
serialized with the attribute name “label”,
not “label-judge”. The literal strings
which match the tags for the label element in the input
are marked with a minus sign to be hidden, so they will not be copied
to the output. Only the content of the label element
will be copied, as the value of the label attribute in the output.
If the input had matched the string
“<label>judge</label>” instead,
there would be no label attribute.
So operationally we have used iXML to copy the string used as a label
into a label attribute on the judge element,
but not if the label used was the string “judge”.
A comparison with the XSLT code that performed this work on the
first edition about ten years ago shows that the iXML form is somewhat
more compact. (However, as the expression "quaesitor",
"es"? shows, for individual regular expressions, the notation
used in XSLT and XQuery is somewhat more compact than that of iXML.)
5.4.3. Handling well-formed XML
(revisited)
Fields recognized by the grammar rules shown above get retagged
as described. Everything else in the input, meanwhile, should be left
unchanged. The discussion of step 2 (above) included a description of
how the grammar matched well-formed XML in the phrases nonterminal. That part of the grammar
was simple, because every phrase-level fragment was either a
character, an i element, or a b element, so
only a few rules were needed.
In the grammar for this step, however, the input has
significantly richer markup (and we are working on larger structures,
not just on phrase-level material). So the relevant part of the
grammar containing the iXML equivalent of an identity transform is
somewhat longer, as shown below.
-wf-xml = wf-xml-bit*. -wf-xml-bit
= ~["<>"] | abbr | ancient | author | author-group | b | bibl |
i | item | list | modern | note | note-ref | notes | p |
primary-sources | secondary-sources | sources | title | work .
abbr = -"<abbr>", wf-xml, -"</abbr>".
abbreviations = -"<abbreviations>", wf-xml,
-"</abbreviations>". ancient = -"<ancient>", wf-xml,
-"</ancient>". author = -"<author>", wf-xml,
-"</author>". author-group = -"<author-group>", wf-xml,
-"</author-group>". b = -"<b>", wf-xml, -"</b>".
bibl = -"<bibl>", wf-xml, -"</bibl>". bibliography =
-'<bibliography>', wf-xml, -"</bibliography>". i =
-"<i>", wf-xml, -"</i>". item = -"<item>", wf-xml,
-"</item>". list = -"<list>", wf-xml, -"</list>".
modern = -"<modern>", wf-xml, -"</modern>". note =
-"<note>", wf-xml, -"</note>". note-ref =
-"<note-ref>", wf-xml, -"</note-ref>". notes =
-"<notes>", wf-xml, -"</notes>". p = -"<p>",
wf-xml, -"</p>". primary-sources = -"<primary-sources>",
wf-xml, -"</primary-sources>". secondary-sources =
-"<secondary-sources>", wf-xml, -"</secondary-sources>".
sources = -"<sources>", wf-xml, -"</sources>". title =
-"<title>", wf-xml, -"</title>". work = -"<work>",
wf-xml, -"</work>".
At about this point, the absence of anything in iXML comparable
to a default identity template in XSLT may begin to feel like a
painful gap. The next section explores a potential
work-around.
5.4.4. An alternative approach to handling well-formed XML
The rules given in the preceding section for the identity-transform
behavior desired for much of the input are not very complicated, but
very repetitive, and if any of the elements involved carried
attributes, it would be even more tedious and probably a bit
error-prone.
A generic form of the identity-transform part of the grammar would
perhaps make things simpler. A simple version of the required rules
was shown in Hillman et
al. 2022. In the grammar fragment below, all nonterminals
are written in all-caps and prefixed with two underscores, to reduce
the likelihood of collision with other names in the surrounding iXML
grammar and for reasons which will shortly become clear.
A few lines of trial #1 will give an idea of the flavor of the result
of parsing the data using this grammar. As usual, linebreaks have
been introduced to make the lines shorter.
This format is, of course, not particularly easy to read or convenient
for further processing, but it does preserve all the information in
the material parsed as wf-xml. And
it does allow an arbitrary number of XML element types to be passed
through without change using a small number of rules in the iXML
grammar, and without requiring one rule per element type.
One hitch is that iXML cannot easily be used to transform this
format back into normal XML, because the names of elements and
attributes must be assigned in the grammar, not taken from the
input data. This is another extension to iXML which might make
life easier in some cases.
Fortunately, a simple XSLT transformation with templates for elements
ELEMENT, ATTRIBUTE, PCDATA, and
so on can easily translate from this format back into conventional
XML. Here are the templates for the three elements mentioned.
Since the material being processed has no XML comments or processing
instructions, these suffice.
5.4.5. Would this step be simpler in XSLT?
Some readers may be thinking at this point that performing this step
with an iXML grammar may be pushing things a bit far. Would it not be
just as simple, or perhaps simpler, to do it in XSLT? After all,
XSLT’s system of templates and priorities is very well suited to
near-identity transforms.
The answer, unsurprisingly, is that yes, XSLT can indeed be used for
this step. The key template is shown below.
Because the XSLT stylesheet can pass over in silence all elements and
attributes to be left unchanged, the XSLT stylesheet is about ten per
cent more compact than either of the two iXML grammars for this step:
150 vs 167 or 168 lines (including blank lines and comments). It is
also much simpler than the corresponding XSLT step in the workflow for
the first edition created ten years ago, probably because the task of
assigning the correct element names to fields has been separated from
the task of recognizing field boundaries.)
5.4.6. The data in FXML form
The form of the data in ‘fielded XML’ is shown below.
All three versions of the previous step produce the same output,
except for some variation in the namespace declarations and iXML
attributes on the document element.
<TLRR-fielded xmlns:ixml="http://invisiblexml.org/NS" ixml:state="version-mismatch">
<title>TLRR (2)</title>
<trial n="1">
<date>149 <note-ref>[1]</note-ref></date>
<charge><i>quaestio extraordinaria</i
> (proposed) <note-ref>[2]</note-ref
> (misconduct as gov. Lusitania 150)</charge>
<defendant>Ser. Sulpicius Galba (58) cos. 144
spoke <i>pro se</i> (<i>ORF</i> 19.II, III)</defendant>
<advocate>Q. Fulvius Nobilior (95)
cos. 153, cens. 136</advocate>
<prosecutor label="prosecutors"><list>
<item>L. Cornelius Cethegus (91)</item>
<item>M. Porcius Cato (9) cos. 195, cens. 184 (<i>ORF</i> 8.LI)</item>
<item>L. Scribonius Libo (18) tr. pl. 149 (<i>promulgator</i>)</item>
</list></prosecutor>
<outcome>proposal defeated</outcome>
<sources>
<ancient>Cic.<i> Div. Caec.</i> 66; <i>Mur</i>. 59;
<i>D</i><i>e </i><i>o</i><i>rat</i>. 1.40, 227-28; 2.263;
<i>Brut</i>. 80, 89; <i>Att</i>. 12.5b; Liv. 39.40.12;
<i>Per</i>. 49; <i>Per</i>. <i>Oxy</i>. 49;
Quint. <i>Inst</i>. 2.15.8;
Plut. <i>Cat</i>. <i>Mai</i>. 15.5; Tac. <i>Ann</i>. 3.66;
App. <i>Hisp</i>. 60; Fro. <i>Aur</i>. 1. p. 172 (56N);
Gell. 1.12.17, 13.25.15; see also Val. Max. 8.1.
abs. 2; Ps. Asc. p. 203; <i>Vir</i>.
<i>Ill</i>. 47.7. <note-ref>[3]</note-ref></ancient></sources>
<notes>
<note>[1] On the date see Cic. <i>Att</i>. 12.5b.</note>
<note>[2] See Brennan (2000) 175. </note>
<note>[3] Val. Max. wrongly portrays the trial
as a iudicium populi: see Briscoe (2019) 69.</note>
</notes>
</trial>
...
6. Stage 3: Fielded XML to Macro-structured XML
The main goal of this stage is to cluster fields together into
appropriate groups marked with a container element. For example, the
defendant and adjacent advocate(s) and witness(es) will be grouped
into a def-group (‘defendant group’)
element, and similarly plaintiffs and their allies will go into a
pp-group (‘plaintiffs or prosecutors
group’).
6.1. The grammar
The key grammar rule is that for trial, which describes the content
of a trial as for the most part a series of grouping elements.
The individual grouping elements vary somewhat in complexity. Some
are just wrappers around one or two field elements; others may enclose
several disparate fields.
The individual fields each need to be identified by a distinctive
nonterminal so that the rules just given can work. But nothing is
changed inside any field, so the fields all have the equivalent of
identity rules, some with special provision for a label attribute.
The nonterminal wf-xml is defined using a generic XML grammar, and
the output from the iXML process is passed through the same XSLT
fix-up transformation as was described above.
6.2. The macro-structured XML
The groupings detected and marked up in this step are visible
in trial #1:
<trial n="1">
<date>149 <note-ref>[1]</note-ref></date>
<ccGrp>
<charge><i>quaestio extraordinaria</i> (proposed)
<note-ref>[2]</note-ref> (misconduct as gov. Lusitania
150)</charge>
</ccGrp>
<defGrp>
<defendant>Ser. Sulpicius Galba (58) cos. 144
spoke <i>pro se</i> (<i>ORF</i> 19.II, III)</defendant>
<advocate>Q. Fulvius Nobilior (95) cos. 153, cens. 136</advocate>
</defGrp>
<ppGrp>
<prosecutor label=" "prosecutors""><list>
<item>L. Cornelius Cethegus (91)</item>
<item>M. Porcius Cato (9) cos. 195, cens. 184 (<i>ORF</i> 8.LI)</item>
<item>L. Scribonius Libo (18) tr. pl. 149 (<i>promulgator</i>)</item>
</list></prosecutor>
</ppGrp>
<outcome>proposal defeated</outcome>
<sources>
<ancient>Cic.<i> Div. Caec.</i> 66; <i>Mur</i>. 59;
<i>D</i><i>e </i><i>o</i><i>rat</i>. 1.40, 227-28; 2.263;
<i>Brut</i>. 80, 89; <i>Att</i>. 12.5b; Liv. 39.40.12;
<i>Per</i>. 49; <i>Per</i>. <i>Oxy</i>. 49;
Quint. <i>Inst</i>. 2.15.8; Plut. <i>Cat</i>. <i>Mai</i>. 15.5;
Tac. <i>Ann</i>. 3.66; App. <i>Hisp</i>. 60;
Fro. <i>Aur</i>. 1. p. 172 (56N); Gell. 1.12.17, 13.25.15; see
also Val. Max. 8.1. abs. 2; Ps. Asc. p. 203;
<i>Vir</i>. <i>Ill</i>. 47.7. <note-ref>[3]</note-ref></ancient>
</sources>
<notes>
<note>[1] On the date see Cic. <i>Att</i>. 12.5b.</note>
<note>[2] See Brennan (2000) 175. </note>
<note>[3] Val. Max. wrongly portrays the trial as a
iudicium populi: see Briscoe (2019) 69.</note>
</notes>
</trial>
7. Future work: Recognizing micro-structures in mixed content
At this point, the fields and the macro-structure of each trial have
been fully recognized and are tagged with characteristic element
types. What remains to be done is to enrich the markup of individual
fields by recognizing important structures: dates, individual
references to ancient or modern sources (and their structure),
references to named individuals, and so on. It is not a single
process defined by a single iXML grammar but a series of independent
grammars intended to be applied to individual fields as appropriate.
In order to operate in the simplest possible way on a specific field
type (e.g. only on dates, or only on the sources element), at this
point the pattern for invoking an iXML processor changes. In the
earlier stages, the parser has been invoked from the command line to
operator on a file or similar text stream. In this stage, the parser
will be invoked from an XSLT or XQuery processor using an extension
function. The processing of any given element E involves several
steps:
E (or, more usually, its content) is serialized as XML and the
result saved in a variable s of type xs:string.
An appropriate iXML grammar is used to parse s and return XML,
which is stored in another variable (call it x). The grammar may
have rules for every element type that may be found in the string,
or it may use a generic XML grammar as illustrated in earlier
stages.
Any generic XML (using the elements __ELEMENT etc.) in x is
fixed up.
The contents of E are replaced with the value of x, or part of
it.
The next steps in the development of the TLRR 2e workflow are thus to
write iXML grammars to recognize and tag various micro-structures:
dates with indications of vagueness (date range, terminus ad quem,
terminus a quo), uncertainty, and annotation (references to notes);
names of individuals, with annotation and indications of
uncertainty;
references to ancient sources, identifying author, work, and locus
for each reference (so that it can if desired be hyperlinked to an
online edition);
bibliographic references to modern sources;
cross references to other trials (and supplying unique identifiers
for trials, so that numbers can be regenerated in case trials are
relocated and renumbered).
8. Concluding remarks
Those interested in descriptive markup have been devising workflows
beginning with word-processor documents since the late 1980s or
longer; there is nothing new about the idea of taking Word documents
as input and producing useful XML with descriptive markup as output.
The technical interest of the work described here, if it has any, is
in the use of invisible XML to describe patterns of interest in the
input and in the application of invisible-XML grammars not only to
plain text but to XML documents, and further to mixed content within
XML documents.
Patterns, of course, can be described in many ways. Some of the
patterns recognized and marked up by the iXML grammars shown above can
also be recognized using regular expressions or using ad hoc logic in
a program.
Clarity, like beauty, may lie in the eye of the beholder, but it can
easily be verified that the iXML grammars used in stages 2 and 3 of
the processing are as a rule more compact than equivalent XSLT or
XQuery programs. For example: the three iXML grammars used in step 2
total 486 lines (including comments and blank lines); the XSLT
stylesheet which did roughly the equivalent work on the first edition
is 1043 lines long. For step 3, the grammar is 120 lines and the
rough equivalent in XSLT written for the first edition is 175 lines
long.
Most iXML grammars are used to move non-XML data into the XML space;
it is less usual to use them to process data that is already in XML.
Some extensions to iXML (which have, for the most part, already been
proposed and are still under consideration) might make workflows like
that described here a little simpler:
A set-subtraction operator would make it much easier to eliminate
ambiguity in cases like trial numbers and titles: the rule for titles
could be written to say that it matches any bolded paragraph that does not match the description of a trial
number. When both patterns are simple (technically: both
regular languages), it's possible to work around the problem, but as
shown above the solution is often complex and tedious to work out by
hand.
Failing that, it would be helpful if one could manage ambiguity by
specifying in the grammar which parse trees should be preferred when
the input has more than one parse tree. A number of parser generators
(e.g. yacc and its kin) provide annotations with this purpose; they
offer little hope that an easily explained general approach to the
problem can be found.
The ability to serialize XML with element and attribute names
drawn not from the grammar but from the input would make it much
easier to define a single rule for elements in the input which
should reappear unchanged in the output.
Invisible XML processing is by no means a replacement for XSLT or
XQuery; far from it. But as the examples above show, it is a useful
complement to those languages, particularly useful in cases where the
input XML is very simple and the patterns to be captures are more
easily expressed in grammatical terms than in XPath.
Attachments
A Zip file containing the following attachments can be found in the Slides and Materials accompanying this paper.
wordml-to-rxml.xsl transformation for stage 1.
rxml-to-gfxml0.ixml grammar for step 2a.
gfxml0-to-gfxml1.ixml grammar for step 2b.
gfxml1-to-fxml.ixml grammar for step 2c.
gfxml1-to-fxml-generic.ixml alternate grammar for step 2c.
gfxml1-to-fxml.xsl XSLT stylesheet for step 2c.
gxml-to-xml.xsl XSLT stylesheet for fixup after a ‘generic’ XML
grammar is used.
fxml-to-mxml.ixml grammar for stage 3.
References
[Alexander 1990]
Alexander, Michael C. Trials in the Late Roman
Republic 149 BC to 50 BC. Toronto: University of Toronto
Press, 1990. (= Phoenix, Journal of the Classical Association of
Canada / Revue de la Société canadienne des études classiques,
Supplementary volume / Tome supplementaire XXVI)
[Hillman et al. 2022] Hillman, Tomos, C. M. Sperberg-McQueen,
Bethan Tovey-Walsh and Norm Tovey-Walsh. “Designing for change:
Pragmas in Invisible XML as an extensibility mechanism.” Presented at
Balisage: The Markup Conference 2022, Washington, DC, August 1 - 5,
2022. In Proceedings of Balisage: The Markup Conference 2022. Balisage
Series on Markup Technologies, vol. 27 (2022). doi:https://doi.org/10.4242/BalisageVol27.Sperberg-McQueen01.
[Lenz] Lenz, Evan. “The WordprocessingML
Vocabulary.” Excerpt from Evan Lenz, Mary McRae, and Simon
St. Laurent, Office 2003 XML
(Sebastopol, CA: O’Reilly, 2004). Online at https://lenzconsulting.com/wordml/.
[Sperberg-McQueen 2016] Sperberg-McQueen, C. M. “Trials of the
Late Roman Republic: Providing XML infrastructure on a shoe-string for
a distributed academic project.” Presented at Balisage: The Markup
Conference 2016, Washington, DC, August 2 - 5, 2016. In Proceedings of
Balisage: The Markup Conference 2016. Balisage Series on Markup
Technologies, vol. 17 (2016). doi:https://doi.org/10.4242/BalisageVol17.Sperberg-McQueen01.
Alexander, Michael C. Trials in the Late Roman
Republic 149 BC to 50 BC. Toronto: University of Toronto
Press, 1990. (= Phoenix, Journal of the Classical Association of
Canada / Revue de la Société canadienne des études classiques,
Supplementary volume / Tome supplementaire XXVI)
Hillman, Tomos, C. M. Sperberg-McQueen,
Bethan Tovey-Walsh and Norm Tovey-Walsh. “Designing for change:
Pragmas in Invisible XML as an extensibility mechanism.” Presented at
Balisage: The Markup Conference 2022, Washington, DC, August 1 - 5,
2022. In Proceedings of Balisage: The Markup Conference 2022. Balisage
Series on Markup Technologies, vol. 27 (2022). doi:https://doi.org/10.4242/BalisageVol27.Sperberg-McQueen01.
Lenz, Evan. “The WordprocessingML
Vocabulary.” Excerpt from Evan Lenz, Mary McRae, and Simon
St. Laurent, Office 2003 XML
(Sebastopol, CA: O’Reilly, 2004). Online at https://lenzconsulting.com/wordml/.
Sperberg-McQueen, C. M. “Trials of the
Late Roman Republic: Providing XML infrastructure on a shoe-string for
a distributed academic project.” Presented at Balisage: The Markup
Conference 2016, Washington, DC, August 2 - 5, 2016. In Proceedings of
Balisage: The Markup Conference 2016. Balisage Series on Markup
Technologies, vol. 17 (2016). doi:https://doi.org/10.4242/BalisageVol17.Sperberg-McQueen01.