InvisibleXML and XML
InvisibleXML (iXML) Pemberton 2013, Pemberton 2019 was designed to provide a lightweight grammar notation to parse inherent structure in (principally textual) data and provide control of how the resulting parse tree can be expressed in XML. As the grammar is expressed textually and inherently structural, a valid iXML grammar can be parsed by the iXML specification grammar (itself defined in iXML) to produce an XML representation of that grammar, with elements and attributes corresponding to necessary productions. For example the grammar:
expr: open, -arith, close.
open: "(".
close: ")".
arith: left, @op, right.
op: "+";"-".
left: "a".
right: "b".describes very simple arithmetic expressions such as:
(a+b)
for which a parse tree would be:
<expr op="+"> <open>(</open> <left>a</left> <right>b</right> <close>)</close> </expr>
But the grammar can itself be parsed by the iXML specification grammar to an XML equivalent:
<ixml>
<rule name="expr">
<alt>
<nonterminal name="open"/>
<nonterminal mark="-" name="arith"/>
<nonterminal name="close"/>
</alt>
</rule>
<rule name="open">
<alt>
<literal string="("/>
</alt>
</rule>
…
<rule name="arith">
<alt>
<nonterminal name="left"/>
<nonterminal mark="@" name="op"/>
<nonterminal name="right"/>
</alt>
</rule>
<rule name="op">
<alt>
<literal string="+"/>
</alt>
<alt>
<literal string="-"/>
</alt>
</rule>
<rule name="left">
<alt>
<literal string="a"/>
</alt>
</rule>
…
</ixml>Indeed this technique is used by some implementations to bootstrap the iXML processor. Figure 1 shows how this might be achieved:
Figure 1: Bootstrapping an iXML processor
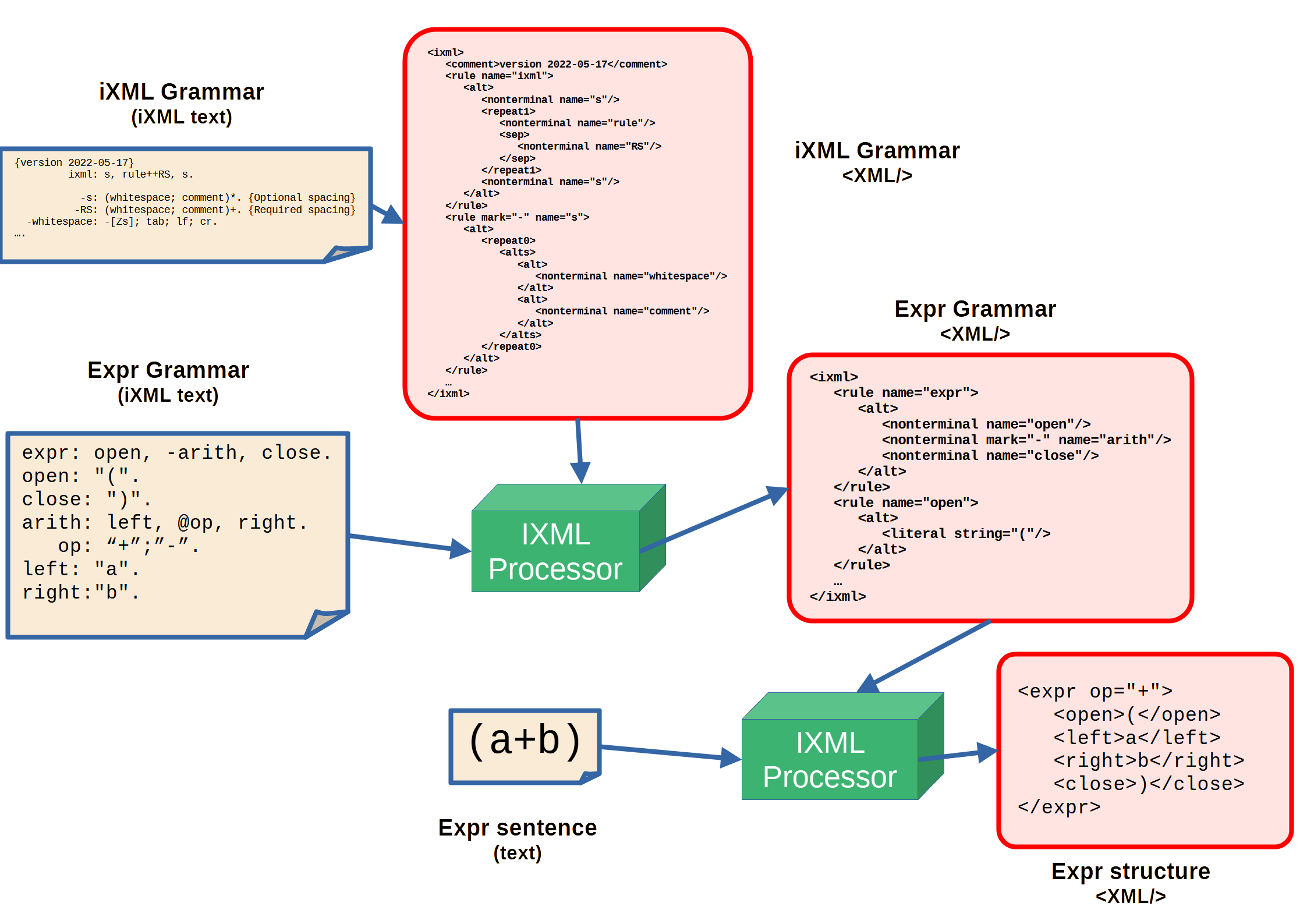
A (hand-transcribed) XML
version of the iXML specification grammar[1] can be used to prime the parsing rules of an iXML processor. This is then used to
parse the textual form of the application grammar, in this case expr, and
generate an XML tree of the given production rules (<rule name="expr:>...
etc). This can then in turn be used to prime the rules of the processor to parse the
end-application text input ((a+b)) as a sentence in the Grammar expr
and produce the final XML parse tree (<expr op="+">...).
But this emphasis on the parsing process has perhaps meant that another feature has been overlooked. That is that an iXML grammar has a perfectly valid XML form, from which the textual iXML form can be generated easily. And one thing this community is well aware of is that we have some very powerful tools for manipulation of an XML tree. This paper examines four applications that exploit this heavily by processing the grammar.
We'll start with a simple example of adding very limited language
localisation
support to a very simple grammar, then discuss how various
meta-grammatical modifications can be achieved, using the example of producing a
reduced tree
version of a given grammar. We then show how a very large and
complex grammar can be generated from an alternative source, by building an iXML grammar
for
XPath/XQuery 4 from the XML definitions that drive formatting of the specification.
Finally we
outline, in incomplete work, how a parse reversal
or round-trip
may be achieved by generating a suitable XSLT transform from the iXML grammar of the
language
.
All the examples have been processed using the JavaScript/SaxonJS/browser-based jωiXML Processor workbench and the associated Interactive iXML workbench.
Adding language localisation
to a grammar
Suppose we have a simple grammar for an address, as used in one of the standard tutorials:
address: person,lf,street,lf,postcode,city,lf,country,lf ;
person,lf,street,lf,city,postcode,lf,country,lf.
person: (title,S?)?,(initials;given,S),surname,S?.
title: "Mr."; "Mrs."; "Dr."; "Ms.".
initials: initial+.
initial: LETTER,".",S?.
surname: name.
given: name.
-name: LETTER,letters.
street: no,S?,streetname; streetname,S?,no,S?.
streetname: name,S; name,S,name.
city: name,S; name,S,name,S.
country: name,S?; name,S,name,S?.
postcode: digits,S,LETTER,LETTER,S? ;
LETTER,LETTER,digits,S,digit,LETTER,LETTER,S?.
no: digits.
-LETTER: ["A"-"Z"].
-letters: ["a"-"z"]*.
-digit: ["0"-"9"].
-digits: ["0"-"9"]+.
-S: " "+.
-lf: -#a |
-#d,-#a.which might be processed as:
| Input sentence | Output tree |
|---|---|
Steven Pemberton 21 Sandridge Road St Albans AL1 4BY United Kingdom |
<address>
<person>
<given>Steven</given>
<surname>Pemberton</surname>
</person>
<street>
<no>21</no>
<streetname>Sandridge Road</streetname>
</street>
<city>St Albans </city>
<postcode>AL1 4BY</postcode>
<country>United Kingdom</country>
</address>
|
Now let us assume we want to use this grammar in multiple languages. To start with
we'd
like the output element tags to use a suitable name in the given language, such as
Person for person in German or nom-de-famille for
surname in French. We could of course edit the textual form of the
address grammar itself, but of course we'd lose connection with the original
grammar. Recall however that the grammar has two completely equivalent forms: the
original
text, used by an iXML processor as the definition of the grammar to parse inputs against,
and
the XML tree corresponding to parsing that grammar as a sentence in iXML:
<ixml>
<rule name="address">
<alt>
<nonterminal name="person"/>
<nonterminal name="lf"/>
<nonterminal name="street"/>
...
</alt>
...
</rule>
<rule name="person">
<alt>
<option>
…
</option>
…
<rule name="surname">
<alt>
<nonterminal name="name"/>
</alt>
</rule>(The XML has been heavily elided to save your eyes.) Now we could of course write an XSLT stylesheet to do the appropriate translation of that XML:
<xsl:template match="@name[. = 'person']>
<xsl:attribute name="{name()}" select="'Person'/>
</xsl:template>
...
<xsl:template match="@name[. = 'surname']>
<xsl:attribute name="{name()}" select="'nom-de-famille'/>
</xsl:template>where the stylesheet could either be hard-coded with the translations, or use internal or external dictionaries, or even lookup translations from suitable web services. But we'd rather empower the author of the grammar to decide what is translated and how, and the best place to do that is on the grammar source itself. Suppose we add something in comments:
person {lang de="Person" fr="personne"}: (title,S?)?,(initials;given,S),surname,S?.
...
surname {lang de="Nachnamen" fr="nom-de-famille"}: name.
...This is still a perfectly valid and executable iXML grammar, which will parse an
address
to produce an English result. Now the comments in an iXML grammar
do not affect the parsing behaviour of the grammar, but they
do appear as structured elements in the XML projection, that is the
iXML grammar doesn't discard comments. (If iXML supported pragmas, then these would
be better
defined as such, since they are intended for machine processing, which will still
appear in
the XML, but the approach remains the same.) Thus these two rules appear in the XML
as:
<rule name="person">
<comment>lang de="Person" fr="personne"</comment>
...
<nonterminal name="title"/>
<option>
<nonterminal name="S"/>
...
<rule name="surname">
<comment>lang de="Nachnamen" fr="nom-de-famille"</comment>
<alt>
<nonterminal name="name"/>
</alt>
</rule>So now we can be somewhat smarter. Any rule that needs to be renamed will have a
comment as its first child, whose contents start with the token
lang. So we can easily build up a two-level map of language translations of the
production names present in the grammar:
<xsl:variable name="translate" as="map(*)">
<xsl:map>
<xsl:for-each select="/ixml/rule[comment[starts-with(., 'lang ')]]">
<xsl:map-entry key="@name" select="
map:merge(tokenize(.)[contains(.,'=')] ! (let $p := tokenize(.,'=')
return
map:entry($p[1], replace($p[2], '"', ''))))"/>
</xsl:for-each>
</xsl:map>
</xsl:variable>Then, assuming $lang is a language code parameter we use this map in the
transformation:
<xsl:template match="@name">
<xsl:attribute name="{name()}" select="
(if (exists($translate(.))) then
$translate(.)($lang)
else
., .)[1]"/>
</xsl:template>
<xsl:template match="comment[starts-with(.,'lang')]/>and all the names of production rules for which a translation was provided and references
to them are renamed. The conversion from the XML to the (pretty-printed) iXML textual
form of
a grammar can be handled by a modest and quite simple XSLT stylesheet of some two-dozen
templates and text output method. Thus the flattened
iXML grammar for French
becomes:
adresse: personne, lf, rue, lf, code-postal, ville, lf, pays, lf |
personne, lf, rue, lf, ville, code-postal, lf, pays, lf.
personne: (titre, S?)?, (initiales; prénom, S), nom-de-famille, S?.
titre: "Mr."; "Mrs."; "Dr."; "Ms.".
initiales: initial+.
initial: LETTER, ".", S?.
nom-de-famille: name.
...and our example address now parses to:
<adresse>
<personne>
<prénom>Steven</prénom>
<nom-de-famille>Pemberton</nom-de-famille>
</personne>
<rue>
<numéro>21</numéro>
<nom-de-la-rue>Sandridge Road</nom-de-la-rue>
</rue>
<ville>St Albans </ville>
<code-postal>AL1 4BY</code-postal>
<pays>United Kingdom</pays>
</adresse>Now obviously there are a number of forms the transformation could take, but the point to take is that we can very flexibly modify an iXML grammar in its XML projection, and recover all the information present in the grammar. (Whitespace in comments is preserved, but non-significant whitespace, e.g. between rules, is discarded.)
We could of course describe more complex information within these comments, perhaps describing the information with another iXML grammar such as:
translation: -"lang", s, lang++s.
lang: code, -'="'',~['"']+,-'"'.
@code: ["a-z"],["a-z"].
-s: -" "+.which would parse the first translation
{lang de="Nachnamen" fr="nom-de-famille"}
to:
<translation> <lang code="de">Nachnamen</lang> <lang code="fr">nom-de-famille</lang> </translation>
(XPath4.0 will support an invisible-xml() function so that could be performed
dynamically within the transforming stylesheet.)
But suppose we want to provide alternative translations for the terminals, e.g. Herr, Frau, etc for the titles. We could insert comments within the production rule bodies, but a little thought suggests it could get very messy and difficult to read. An alternative might be to provide suitably labelled alternative rules:
...
title: "Mr."; "Mrs."; "Dr."; "Ms.".
title>Anrede {lang de}: "Herr"; "Frau"….
...(The > operator declares a renaming of that non-terminal during
serialisation). Now an iXML grammar cannot contain multiple definitions of the same
term – an iXML processor would report an error using such a grammar. But this
text is perfectly valid to be parsed as a potential sentence by the iXML
specification grammar itself, producing an XML tree with a section such
as:
<rule name="title"> <alt><literal string="Mr."/></alt> ... </rule> <rule name="title" alias="Anrede"> <comment>lang de</comment> <alt><literal string="Herr"/></alt> ... </rule>
It is then comparatively simple in XSLT to filter the rules to those pertinent to the target language, and then convert to the textual form, leaving a fully valid and executable grammar.
Truncation of Deep Trees
In some highly recursive cases, especially in programming languages, the resulting parse tree can get very deep indeed. For example in XPath the production for a simple integer has to go though 28 earlier productions to be reached, each adding an element into the parse tree serialisation (and XQuery adds another 4):
<XPath>
<ExprSingle>
<OrExpr>
<AndExpr>
<ComparisonExpr>
<OtherwiseExpr>
<StringConcatExpr>
<RangeExpr>
<AdditiveExpr>
<MultiplicativeExpr>
… 14 intermediate levels elided …
<PrimaryExpr>
<Literal>
<NumericLiteral>
<IntegerLiteral>12345</IntegerLiteral>
</NumericLiteral>
</Literal>
…Hence for many minor expressions the full parse tree is very large but with many sections
that are very thin, that is elements with only a single child branch.
Whilst a computer takes such large structures in its stride (albeit at extra time
and memory
costs), when a human looks at such results, one may not see the wood for the
trees. In this case it can be useful to return the most specific production in
the grammar to which the sub expression relates, removing any intermediate single-child
elements. (The XSLT
Streamability Rules are specifically drawn up in such terms, so 1+2 is
treated as an AdditiveExpr of two IntegerLiterals with a
+ operator, rather than the full deep tree.)
Of course, it is trivial to construct a post-processing XSLT transform to trim a tree
in
such a manner, but avoiding building such a big tree in the first place might be preferable.
One of the techniques to reduce these trees during construction is to mark some rules
such
that if the element generated would only have one child, and no attributes, then ignore
it in
the serialisation. Using some method (a unique comment or some form of pragma Hillman 2022a) to mark such rules, a simple parse of the grammar to its XML form,
followed by an XSLT transform to change such rules (and references) and final conversion
back
to textual iXML can achieve this, making it a much more practical tool. This technique
was
used during development of an iXML grammar for XPath 3 expressions (see section The
XPath3.1 grammar
in Hillman 2022b for more details).
But this approach can be made more generic and automatic by implementing some of the following rules to recognise situations when an element with a single child element would be generated, and rewrite the rule to eliminate serialisation of the parent in such a case. Examples come from the XPath 4 grammar work described in the next section:
Only rules that are not marked (for definite inclusion
^, removal - or projection as an attribute @) will be
effected. This permits a grammar author to override any potential truncation, e.g.:
^start: body.
@operator:"-" ; "+".
-WhitespaceChar: -[#9;#D;#A;#20].
All of these rules (and non-terminal
references to them) will remain unaltered.
The focus is to identify unmarked rules where there are one or more alternative resolution paths which consist of just a single non-terminal, possibly decorated by a zero-or-more repetition or option occurrence mark. The general technique is for most candidate rules to be replaced with two rules, one of which handles single-child element alternatives and the other where multiple nodes are generated. There are a small number of candidate cases which involve different detailed treatment:
-
Rules where every alternative has just a single child which is an unmarked or suppressed non-terminal only need the rule to be marked suppressed, and it will reduce the local tree height by one, e.g.:
ExprSingle: ForExpr | LetExpr | QuantifiedExpr | IfExpr | OrExpr. → -ExprSingle: ForExpr | LetExpr | QuantifiedExpr | IfExpr | OrExpr.
-
Rules containing some alternatives that have terminals, or more than one non-terminal, are split into two rules: the first (which is suppressed and renamed) collecting all the single unmarked non-terminal alternatives and a reference to the original rule, and the original where all the single-non-terminal alternatives have been deleted. Examples are:
UnaryExpr: ValueExpr | UnaryExprOps+, ValueExpr. AbbrevForwardStep: "@", s, NodeTest | SimpleNodeTest. → -OPT-UnaryExpr: ValueExpr | UnaryExpr. UnaryExpr: UnaryExprOps+, ValueExpr. -OPT-AbbrevForwardStep: SimpleNodeTest | AbbrevForwardStep. AbbrevForwardStep: "@", s, NodeTest.Any references toUnaryExprelsewhere in the grammar, or self-referencing in the original rule, are altered to point toOPT-UnaryExprand so forth. -
Rules which have a single alternative consisting of a non-terminal followed by a zero-or-more repetition can be split into two rules: the first (which is suppressed and renamed) with two alternatives: the isolated leading non-terminal or a reference to the original, and the original with the zero-or-more term altered to a one-or-more. An example is:
ParamList: Param, (-",", s, Param)*. → -REP-ParamList: Param | ParamList. ParamList: Param, (-",", s, Param)+.Similar treatment can be applied to option cases (term?) or repetition with separation (term**sep)
The changes are of course performed on the XML form of the grammar, using a simple XSLT transform of just some nine templates and a small set of templates to regenerate the textual iXML form of the reduced grammar. These techniques have been exercised on the very large grammars described in the next section.
For example the XPath 4 iXML grammar contains 204 rules. Running the grammar
reducer
finds 32 rules which can be susceptible to tree reduction. Using this
grammar on a large sample (~2000 character) XPath expression results in a tree with
461
elements and a maximum depth of 17, compared to the full unreduced parse tree of 3764
elements
with a maximum depth of 142. Note that this tree does still contain elements which
have just a
single child, such as:
<EnclosedExpr> <VarRef> <QName local="crlf"/> </VarRef> </EnclosedExpr>This is because the production rules for the two parent elements contained suppressed terminals:
EnclosedExpr: -"{", s, Expr?, -"}".
VarRef: -"$", s, VarName.
and are therefore not candidates for reduction
from the rules above. In addition if we wished to round-tripthe expression (generate an XPath expression which on parsing would produce the same parse tree) we would have to preserve these elements in the tree to trigger interpolation of the necessary discarded characters. (This is discussed further in the last section.)
The XPath/XQuery grammars
One of the goals of the InvisibleXML Community Group is to show that the technology can have a role as a lightweight front-end parser for XML work-flows even on an industrial scale and as such various larger and more complex grammars have been constructed and tested. One large grammar that may be familiar to readers is that of XPath, used extensively within an XSLT compiler, so it was natural to see how a modification of the EBNF of the 3.1 specification (https://www.w3.org/TR/xpath-31/#id-grammar) of 2017 into iXML would work.
Generally the transcription was fairly straightforward, with a few additional
pseudo-productions needing to be added. For example, to allow (variable) operators
to be
projected as attributes in the resulting parse tree (e.g. ("+"|"-") in
AdditiveExpr becoming @AddOp: s?,'+',s?; s,'-',s.) This worked
pretty well and the resultant grammar parsed sample XPath expressions of moderate
complexity
successfully, successfully parsing all bar a dozen or so of the ~20k expressions in
the
XPath3.1 test suite.
Over the past two years the QT4 Community Group has been working on developing the XPath, XQuery and XSLT specifications to a 4.0 level. Here the grammar for XPath added a lot of new features but rather than modify my pre-transcribed version, I chose to examine a different path.
Whilst the EBNF grammar appears in textual form in the draft specifications, those production rules are actually a generated display of a more structured definition of the grammar, described in XML, covering a number of specifications (XPath, XQuery, XQueryUpdate and XSLT Patterns). This structure describes the production rules and tokens in several different forms. For example the production in the specification HTML:
Wildcard ::= "*" /* ws: explicit */
| (NCName ":*")
| ("*:" NCName)
| (BracedURILiteral "*")is actually defined by a series of sections:
<g:production name="Wildcard" whitespace-spec="explicit">
<g:choice break="true" name="WildcardChoice">
<g:string process-value="yes">*</g:string>
<g:ref name="NCNameColonStar" needs-exposition-parens="yes"/>
<g:ref name="StarColonNCName" needs-exposition-parens="yes"/>
<g:ref name="URIQualifiedStar" needs-exposition-parens="yes" if="xpath40 xquery40 xslt40-patterns"/>
</g:choice>
</g:production>
...
<g:token name="NCNameColonStar" value-type="string" inline="true">
<g:ref name="NCNameTok"/>
<g:string not-if="xpath40 xquery40">:</g:string>
<g:string not-if="xpath40 xquery40">*</g:string>
<g:string if="xpath40 xquery40">:*</g:string>
</g:token>
...which contains conditional directives if="xpath40..." for relevancy to
various specifications, inline substitution directives, information about whitespace
handling,
hints for parsing (such as a state-table graph) and references to other productions
etc. The
specification repository contains a series of XSLT stylesheets which are used in concert
to
produce the specifications themselves, including EBNF text generation as well as other
ancillary features, such as tests from the examples given in the specification
narrative.
So the question was could an iXML grammar be generated to parse the full complexity of XPath or XQuery 4.0 by stylesheets using this definition as a source, and if so, how little specialist knowledge of the domain would need to be injected into the tools to make it work correctly?
The development technique employed was to process the input data incrementally through several stages, refining the transformation until reaching a point where it is possible to test the result with a corpus of test cases. Luckily in the case of XPath and XQuery 4.0 there are a very large number of test cases (about 35,000) so we have an extensive ready-made set of examples to test the grammar.
The first step is to discard any parts of the specification which are not appropriate
to
the chosen grammar, e.g. discarding declaration statements in XPath, or the parser
state-table
hints. Conditionality is described through @if|@not-if attributes with values
being a set of grammar name tokens. So a very simple single pass with templates such
as:
<xsl:param name="specName" as="xs:string" select="'xpath40'"/> ... <xsl:template match="g:*[@if][not(tokenize(@if) = $specName)]" priority="2"/>removes all superfluous or unnecessary components leaving only and all components relevant to the given grammar:
The second step was to expand the fixed tokens (such as for and
in in a ForClause or NCNameColonStar above) which are
referred to from appropriate productions and marked as inline in the
definition. They will appear as terminal strings in the eventual iXML rules. This
is achieved
by forming $inLines as map(xs:string,element()) indexing the inlined productions
and substituting for any references to those g:ref[map:contains($inLines,@name)]
with the contents of the production: $inLines[@name)/*. The productions declared
to be inlined are discarded. Now we have a version of the grammar specification which
is tuned
to the required specification, and with most terminal tokens inlined in the production
rules.
The next stage is to start the translation into iXML. For most productions this is a relatively straightforward mapping using template matching, e.g.:
g:production → <rule name="{@name}/>
g:ref → <nonterminal name="{@name}/>
g:token → <rule name="{@name}/>
g:string → <literal string="{.}"/>
g:charRange → <member from="{@minChar}" to="{@maxChar}"/>
g:choice → <alts> <xsl:apply-templates/> </alts>
g:choice/* → <alt> <xsl:next-match/> </alt>
g:zeroOrMore → <repeat0> <xsl:apply-templates/> </repeat0>
...but there are some special constructs, such as for the operator expressions (boolean,
comparison, arithmetic, type casting and checking etc.) which are defined in a
cascade
of operator descriptions, each being defined in terms of itself and
its successor production. For example:
<g:binary name="OrExpr" condition="> 1">
<g:string>or</g:string>
</g:binary>
<g:binary name="AndExpr" condition="> 1">
<g:string>and</g:string>
</g:binary>declares that an OrExpr can either be a single instance of its successor (an
AndExpr) or an AndExpr followed by the token or
followed by another OrExpr. AndExpr is similarly defined in terms of
its successor, which is a ComparisonExpr. There are some
16 of these operator declarations and they are processed with templates that use a
simple
helper function to retrieve the name of the next production.
But there are other cases where some specialist treatment is required. Generally there are four types:
-
Rules that are added outside the primary EBNF, mainly to support whitespace tokenisation. (This is discussed more extensively later.)
-
Rules (possibly defined outside the EBNF, and referred to by annotation) that contain a construct which cannot be expressed within iXML. For example some potential names for function calls (
element,if… ) are reserved as they conflict with node types or language construct keywords. This is discussed below. -
Rules that need to be modified to reduce potential ambiguity in the resulting iXML grammar
-
Rules which accommodate some of the extra-grammatical conventions not directly mentioned in the EBNF, such as supporting the use of (
>, xFF1E) full-width greater-than signs in operators where a normal right-angle-bracket>would require entity representation within XML structures.
The third category (reducing ambiguity) is worth describing by taking the example
of the
StringTemplate construction, which supports interpolation within strings, e.g.
`The time is {$time} precisely`. This is defined in the grammar (converted to
iXML equivalent) as:
StringTemplate : -"`", (StringTemplateFixedPart | StringTemplateVariablePart)*, -"`".
StringTemplateFixedPart : ("{{"; "}}"; "``"; ~["`{}"])*.
StringTemplateVariablePart : EnclosedExpr.
EnclosedExpr : -"{", Expr?, -"}".These productions will match valid string templates but within iXML they introduce (potentially infinite) ambiguity, mainly because the fixed part expression will match the empty string and thus any sequence of (empty) fixed parts can match, or a string can be partitioned between any number of consecutive fixed parts. (The XPath grammar employs longest-matching semantics, which iXML doesn't support by specification.) In order to overcome this problem, a different but operationally equivalent set of productions is used:
StringTemplate: -"`", StringTemplateContent?, -"`", s.
-StringTemplateContent: StringTemplateFixedPart |
StringTemplateVariablePart |
StringTemplateVariablePart, StringTemplateContent |
StringTemplateFixedPart, StringTemplateVariablePart, StringTemplateContent?.
StringTemplateFixedPart: ("{{"; "}}"; "``"; ~["`{}"])+.
^StringTemplateVariablePart: EnclosedExpr.which ensures that empty
fixed parts are never matched, and that no two
fixed parts can be adjacent. Other productions that need a similar ambiguity-reduction
treatment include: Comment and CommentContents and four in XQuery
node constructors: DirPIContents, CDataSectionContents,
PragmaContents and DirAttributeList
The general mechanism used for such substitution of single rules is of course to define
the new rules in iXML, then parse this to XML using the iXML specification grammar.[2] This substitution dictionary
can then be consulted when
translating from the productions to iXML rules, replacing with the new
definition:
FunctionCall: EQName ¬ reservedFunctionNames,ArgumentList.
NamedFunctionRef: EQName ¬ reservedFunctionNames,-"#",IntegerLiteral.
StringTemplateFixedPart: (("{{";"}}";"``");~["`{}"])+.
^StringTemplateVariablePart: EnclosedExpr.
-QNameToken: (@NCNameTok>prefix,-":")?,@NCNameTok>local.
The next stage was to stress-test it by attempting to parse all the ~22,000 XPath expressions contained in the QT4 test-suite, and the ~35,000 expressions of the XQuery superset. A simple XSLT program was written and ran successfully, with the following approximate results:
| Grammar | Number of expressions | Time | Failures | Ambiguous |
|---|---|---|---|---|
|
XPath 4.0 |
26139 |
14m 57.732s |
26 |
33 |
|
XQuery 4.0 |
35551 |
37m 29.795s |
42 |
69 |
But in that process of refining the grammar against the samples, some possibly significant constraints to avoid extensive (and potentially exponential) ambiguity propagation have arisen, illustrating the limits of iXML as a notation for languages found in the wild. These include:
-
XPath defines some (binary) operators the character sequences of which could occur in a name (an
NCName), such aseqordivand do not require to be surrounded by whitespace in situations in which they are unambiguously (according to XPath rules) acting as operators, such as5div6. But in iXML we cannot express such restrictions, so if we permit them to be unsurrounded by whitespace we have the ambiguity ofIt this an operator or part of a name?
[3] The worst culprit is-(minus/hyphen) which whilst not a letter, can appear withinNCNames and letting that have both roles typically causes exponential ambiguity growth with many large XPath expressions. -
To remove ambiguity, XPath also mandates some extra-grammatical constraints, which again we cannot express within iXML. Some names for function calls (
element,if… ) are reserved as they conflict with node types or language construct keywords. To overcome this issue asubtraction
or set difference operator was introduced within the iXML (A ¬ B), which matches the first termAonly if the second termBdoes not match at the same character position. It seems to work reasonably well and may be proposed as an additional feature of iXML. -
Occurrence indicators (
?,*,+) also can lead to ambiguous cases, such as in typed function signatures. For example, isfunction () {..} as xs:string+describing a single function returning multiple strings, or multiple functions each returning a single string or even describing the start of an erroneous additive expression? Here they have to bind to the closestSequenceTypeproduction rather than act on the broader type or even as possible arithmetic operators – there are a few other similar restrictions. However, iXML as currently defined has no feature that would support this, and any resolution of ambiguity would need to be carried out by post-processing the set of possible parse trees.
The other area that requires great care (applicable to other grammars describing
effectively tokenised grammar structures) is to ensure that optional whitespace doesn't
get
double accounted
. This is sufficiently important in this application that it
is discussed in the following section.
But all these restrictions aside, this has demonstrated that large and complex grammars
can be supported with iXML. In fact a significant recent (April & June 2024) modifications
of the for and let constructs for XPath 4.0, bringing them more in
line with XQuery, manifested itself in non-trivial changes in the grammar (new production
rules etc.) and this was handled without change by the automated construction mechanism.
The curse of Ambiguity - Whac-a-Mole on whitespace
This section describes in some more detail the problems associated with correctly handling whitespace in grammars with the complexity of XPath, given that iXML does not have a tokenization phase and any effective tokenization has to be performed with iXML rules acting on a character-by-character basis. The real issue is where a whitespace matching element is defined both in a non-terminal production and in a (possibly indirect) reference to it. For example:
A: "start", s, B. B: s, "some text". -s: -" "*.
will have six ambiguous solutions for the input
start some text as the five spaces separating the
strings can be accounted for by being allocated 0-5 either in the s of
A or the s of B. And the suppression of the
s element in the serialisation results in all six ambiguous solutions having
the same XML tree!
In texts like programming listings with large sections of whitespace any such double-accounting will rapidly lead to explosive growth of ambiguity. But solving this isn't clear-cut, especially when possibly nested repetition and optional constructs abound. Failing to add whitespace matching where needed can lead to parsing failures – adding multiples inadvertently can lead to large ambiguity.
A good example of this in the XPath grammar is handling the
MultiplicativeExpr operator div, such as in
2 div foo where there are three spaces between the
2 and the operator symbol. If we assume that a number can be followed by
optional discarded trailing spaces:
IntegerLiteral: Digits, s.
-s: WhitespaceChar*.
then this would imply that
2div foo would be valid, but if we change the operand to an axis step
bar2, viz bar2div foo the expression is no longer valid as
bar2div is also an axis step. So we must mandate required space before the
div
operator:
MultiplicativeExpr: UnionExpr, (RS,"div";"*"), UnionExpr.
-RS: WhitespaceChar+.
But if we try this on
2 div foo (the IntegerLiteral satisfying
productions from UnionExpr) we get 3 ambiguous parses, corresponding to the
trailing s of IntegerLiteral consuming 0, 1 or 2 spaces, the
remainder being swept-up by the RS of the operator. To remove this we need to
restrict the required space before the operator to just be a single
character:
MultiplicativeExpr: UnionExpr, (RS1,"div";"*"), UnionExpr.
-RS1: WhitespaceChar.
which replaces the ambiguity of
effectively a sequence WhitespaceChar*,WhitespaceChar+ with the unambiguous
WhitespaceChar*,WhitespaceChar.
This requires some general approach and handling far too many specific cases. Firstly we define three cardinalities of whitespace in the generated grammar:
-WhitespaceChar: -[#0009;#000D;#000A;#0020].
-s: WhitespaceChar*. {Optional whitespace}
-RS: WhitespaceChar+. {Required whitespace}
-RS1: WhitespaceChar. {Required single whitespace character}and then insert appropriate reference around candidate terms. These can be indicated
in
the original grammar definition where some tokens are described as delimiting
such as $ or != and in general can be surrounded by optional
whitespace – in this case we add a following s non-terminal. Others are
described as non-delimiting
such as ancestor or
else and require whitespace separation, at least beforehand, so an
RS1 non-terminal is prepended.
However, this phase has proven to be very hit and miss (hence Whac-a-Mole on
Whitespace
) and thus far there has been far too much use of heuristic cases to
establish a grammar that doesn't fail in parse and doesn't introduce ambiguity due
to
doubly-accounted whitespace. More work is needed to streamline the process and develop
more
general principals.
Projecting into the language of the grammar
Let us assume that you have a requirement to modify XPath expressions, perhaps renaming
some of the variables in the expression, possibly for obfuscation reasons. A
regular-expression substitution to replace $target with $xyz667 is
dangerous as $target could occur in an important constant string, or in other
cases where it is not acting as the given variable. The only safe method is to perform
this on
the parse tree of the expression, where it will be a part of a VarRef
construction. So you use the XPath iXML grammar to get the parse tree and modify that.
Now you
need to back-convert from the modified XML parse tree to the equivalent textual XPath
expression. How could you do this in the general case, when you're given an original
iXML
grammar (G) and the (assumed correct) parse tree of a sentence in that
language?
This is often referred to as the round-tripping problem, between two
different language representations of essentially the same information. In the case
of XML
work some 15 years ago on XSugar Braband 2007, explored this in the context
of a dual syntax for XML definable data (normal start/end tags and an alternative
non-XML
textual syntax). It employed a dual-part context-free grammar of productions each
of which
describes both the non-XML form (using regular expressions extensively to describe
tokens) and
the equivalent XML form of that production, with linkage between the two. The technique
uses
a Unifying Syntax Tree
into which parsing can taken place from both syntaxes,
and unparsing to project from an instance of that tree into appropriate
XML or non-XML text.
Often this round-tripping is treated as arranging for
sentence A → parse-tree → sentence B, where A and B are
identical strings. In this analysis I'm looking at a slightly different take:
parse-tree A → sentence → parse-tree B, where A and B
are identical trees and thus have identical meaning in the given grammar.
In this case we want to generate a sentence from tree A which when re-parsed
would produce the same tree. This should be a necessary condition for the mapping
of a parse
tree into a correct sentence in the target grammar, though a sufficient condition
requires
this for any possible parse tree in the grammar.
(If the parse tree of an input text is the only information used to
create effect from that input in the given application, then any textual components
marked for
discarding during the parse and not appearing on the tree can by definition be dropped
– any
meaningful effect they have is on the form of the parse tree. For example in XPath
the
to token can be discarded in 1 to 14 as the parse
RangeExpr(1,14) can only appear with use of the binary to operator.
The problem here is to identify exactly when, where and which discarded text needs
to be
re-injected to create the same portion of the parse tree.)
Round-tripping using iXML
Pemberton Pemberton 2024 uses an approach generating an
inversion
iXML grammar which parses the XML serialised string (i.e. a
series of characters include XML punctuation
– <>/=") to
Create an input that would produce the identical output, which is a
similar target to that used in this paper. For example the RHS of a rule
bar : ["a"-"z"]+. has recognizers
for the opening and closing
tags added, viz:
bar: -"<bar>", ["a"-"z"]+, -"</bar>".
such that the serialised element will be recognised, the XML tags removed and only the text content passed through.
Similarly suppressed literals (-"foo") are converted into insertions
(+"foo") (and vice versa) and if the path they lie on is in the final tree,
then necessary suppressed or inserted keywords
will be added or removed as
appropriate.
To handle out-of-order
attributes he has to extend the repertoire of iXML
non-terminal serialisation directives to add parse the input but do not
serialise
(*) and parse nothing but serialise the node of this
name from earlier in the tree marked with a "*"
(+). The technique
works in part because the iXML grammar parses a sequence of characters
representing the XML tree serialisation, accounting for various options of
document-order
of sub-trees, by the option and alternative support of iXML
itself.
Technically this approach is more expensive than the original parse, as the XML element tag characters need to be recognised in addition to (most of) the original text, but it certainly has elegance and by double-application actually acts as a serialiser.
Round-tripping with XSLT
The technique explored in this paper is to attempt to generate an XSLT transform from
the description of the grammar which will process the (unserialised) parse tree as
input and
add suppressed text or reorder components to produce a parse tree whose text
value
is a correct sentence in the original grammar and whose parse tree will be
identical to the original. In theory this should be much more efficient than Pemberton's
approach, working on internal representations of the XML tree, but almost certainly
considerably more complex to set up. The general arrangement is shown in Figure 2
Figure 2: Round-tripping with XSLT
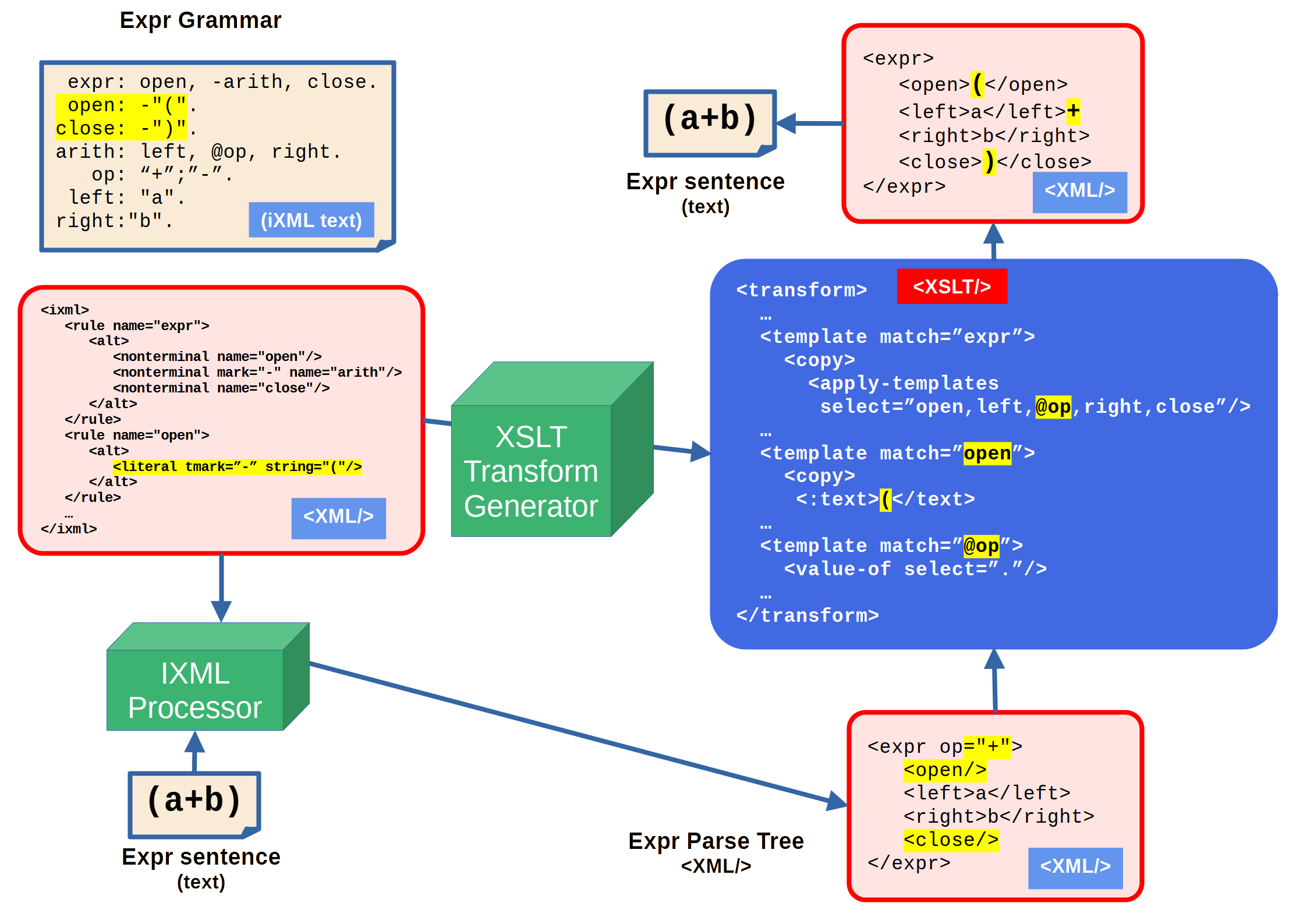
In the example, the opening and closing bracket literals are suppressed (they add no meaning to the parse tree and would make the parse tree have undesirable mixed content) and the operator value is held as an attribute. Where these are declared in the grammar and have effect in the parse tree are highlighted in yellow.
The first step is to use an XSLT transform to generate another XSLT transform from
the
XML form of the grammar. This generated transform, which defaults to a
shallow-copy
of the input, will have templates matching sections of the
parse tree where additional text will need to be added, or attribute values interpolated
as
text, again highlighted in yellow. The generation of this transform is entirely independent
of any sample parse trees - it only depends upon the original grammar and can be used
on any
number of (assumed valid) parse trees.
This transform is then used to modify the sample XML parse tree, adding text nodes
where
necessary, highlighted in yellow in the figure. Then taking the text-value
of
that tree (concatenating all the text-nodes in document order) yields the round-tripped
sentence, which if re-parsed will produce the same sample parse tree as the original.
The
problem of course is to generate that transform.
The rest of this section describes an ongoing and incomplete
experiment to generate a such a transform that will invert
the parse tree of
an XPath4 expression of some considerable complexity, using the XPath4 iXML grammar
described above as the source to generate that transform, The work aims to limit as
much as
possible, and ideally eliminate, any generator code specific to the exact productions
within
that grammar.
We make one initial assumption – the grammar contains no text insertions, which happens to be the case for the XPath4 grammar. This means we concentrate only on i) identifying text suppressions which need to be added to the parse tree, and ii) adding interpolation as text nodes of information that has been bound to an attribute in the parse tree. The task is to identify where such exclusions have occurred or data stored on an attribute, and generate an XSLT template that matches just that situation and adds a suitable text node whose value is either a string value that satisfies the original (excluded) terminal declaration, or the value of the appropriate attribute.
The first stage is to process the grammar into a canonical form by i) determining the serialisation mark for every non-terminal reference and ii) eliminating any components that only suppress text (and non-terminals) and are entirely optional. These are therefore irrelevant to the form of the final parse tree – often this might cover optional whitespace, but it might take any form. For example:
-WhitespaceChar: -[#0009;#000D;#000A;#0020].
-s: WhitespaceChar*.
-RS: WhitespaceChar+.
-RS1: WhitespaceChar.
where matched references to any of the four
non-terminals will never generate output in the parse tree, but of the four only references
to s are entirely optional in the input. Deleting them completely will not
change the result of any valid sentence generated and their removal from the grammar
makes
subsequent processing easier.
We term such components void and they are identified by a recursive
process looking for non-terminal productions where all the RHS components are
all suppressed (direct or indirect) terminals
and the occurrence cardinality of those components are
zero-or-more
. In this case the indirect terminals for s are
the suppressed -[#0009;#000D;#000A;#0020]. Here is an example, shown in iXML
form:
MapConstructor: (-"map", s)?, -"{", s,
(MapConstructorEntry, (-",", s, MapConstructorEntry)*)?,
-"}", s.
→
MapConstructor: -"map"?, -"{",
(^MapConstructorEntry, (-",", ^MapConstructorEntry)*)?,
-"}".where all void components have been stripped out and every component has a serialization mark.
Currently we unfortunately then have to handle some dozen or more different cases for non-terminal production rules of increasing complexity. Some determine that no parse-tree modification is needed, such as when every RHS term is an unsuppressed terminal, e.g.:
CommentContents: (~[":("]; ":", ~[")"]; "(", ~[":"])*.Others
need to generate a template to inject required suppressed
terminals:
EnclosedExpr: -"{",Expr?, -"}".
→
<xsl:template match="EnclosedExpr">
<xsl:copy>
<xsl:text>{</xsl:text>
<xsl:apply-templates select="*"/>
<xsl:text>}</xsl:text>
More complex cases require examining the
parse tree to determine which of a number of alternatives was selected or to choose
appropriate injection of suppressed text. For example:
OrExpr: AndExpr |
AndExpr, RS1, -"or", RS, OrExpr.
→
<xsl:template match="OrExpr[OrExpr]">
<xsl:copy>
<xsl:apply-templates select="AndExpr"/>
<xsl:text> or </xsl:text>
<xsl:apply-templates select="OrExpr"/>
which matches a recursive use
of the or operator. (There are a number of ways of expressing this, with a
conditional, multiple templates etc.) Some of the rules get much more complex having
to
examine the presence or absence of certain conditions within repetitions, options
and
alternates. The hope is to gradually uncover deeper properties against which the necessary
templates can be generated.
It is clear that trying to determine which path through the options for a rule have been taken in a particular section of the parse tree in XSLT isn't straightforward, at least at the superficial level, compared with the approach using iXML itself that Pemberton uses. As a very simple example consider the two possible outcomes of:
S: -"alt1" A, B, A; -"alt2", A, A, B. → <S><A/><B/><A/></S> or <S><A/><A/><B/></S>In the inverted iXML approach, the iXML processor attempts parsing of both inverted alternatives concurrently - if it was the first then
<B/> will match before a second
<A/> and so forth. But in the XSLT case we have to match a sequence of
A,B,A to determine that it was the first case (and therefore need to re-inject
the discard "alt1") and whilst XSLT patterns can be constructed to do so, they
get very complex, very quickly, especially with nested optionalities, repetions and
alternatives. It is conceivable that a deeper level of ananlysis and implmentation
will be
required – this is part of the ongoing research.
Implementing these template-generating rules (described in some three-dozen templates)
and using the XPath iXML grammar described above (XP), converted to its XML
form, we generate a putative inversion transform
for XPath4 as a stylesheet
with 167 templates.
We can then take a rather complex XPath expression sample of some 2000 characters (which is a sequence of a number of the larger examples in the XPath specification):
let $crlf :=
char('\r')||char('\n')
return
let $csv-uneven-cols :=
concat(
`date,name,city,amount,currency,original amount,note{$crlf}`,
`2023-07-19,Bob,Berlin,10.00,USD,13.99{$crlf}`,
`2023-07-20,Alice,Aachen,15.00{$crlf}`,
`2023-07-20,Charlie,Celle,15.00,GBP,11.99,cake,not a lie{$crlf}`)
return
for $r in parse-csv($csv-uneven-cols,
map { "column-names": true(),
"number-of-columns": 6 })?rows["justTemp"]
return array { $r?fields },
let $data := map{
"fr":map{"capital":"Paris", "languages":["French"]},
"de":map{"capital":"Berlin", "languages":["German"]}
} return pin($data)??languages[.='German']!label()?path()[1],
replace(
"57°43′30″",
"([0-9]+)°([0-9]+)′([0-9]+)″",
action := function($s, $groups) {
string($groups[1] + $groups[2] ÷ 60 + $groups[3] ÷ 3600) || '°'
}
),
( if (3 != 2) then 16 else 0 ) + ( if (8 = 7) then 4 else 1 ) ,
if (/doc/widget1/@unit-cost = /doc/widget2/@unit-cost) then /doc/widget1/@name else /doc/widget2/@name,
if (if (5 != 3) then fn:true() else fn:empty(/doc/widget1)) then "search" else "assume",
every $emp in /emps/employee satisfies (
some $sal in $emp/salary satisfies $sal/@current = 'true'
),
"red" instance of enum("red", "green", "blue"),
let $x := "[A fine romance]"
let $x := substring-after($x, "[")
let $x := substring-before($x, "]")
return upper-case($x),
$tree ??$cities =>
map:for-each( fn($key, $val) { $val ??to ! ($key || "-" || .) } ),
if (@code = 1) {
"food"
} else if (@code = 2) {
"fashion"
} else if (@code = 3) {
"household"
} else {
"general"
},
if ($x castable as hatsize)
then $x cast as hatsize
else if ($x castable as IQ)
then $x cast as IQ
else $x cast as xs:string,
"The cat sat on the mat"
=> tokenize()
=!> concat(".")
=!> upper-case()
=> string-join("-"),
not($M instance of map(xs:int, xs:string)),
3.14159_26535_89793e0,
0xffff,
0b1000_0001,
12345This parses against the XPath4 iXML grammar to produce a tree with 3764 elements, 114 attributes and 97 non-whitespace text nodes. (This tree is some 142 levels deep at its deepest!)
Using the inversion
stylesheet to transform this parse tree results in a
tree with the same number of elements (3737), no attributes and 471 non-whitespace
text
nodes. The resulting string is now 1671 characters long, the shortening due to removal
of
unnecessary whitespace.
When we parse this generated string against XP we, thankfully, obtain the
same parse tree as the original. As suggested above, this is a necessary condition
for the
generated transform being a function to invert
an iXML grammar parse tree, at
least as far as preserving semantics is concerned, but certainly not sufficient.
It is clear that at this stage for this large example the technique just about
works, is fragile and contains far too many heuristics, though currently only
three of the introduced XPath productions (RS,RS1,WhitespaceChar) are
specifically named in the inversion generator. Much more experimentation is needed.
Acknowledgements
The author is grateful for the very useful discussions, and shared understanding, with fellow iXML implementators which involved many of the topics described in this paper, and the reviewers for helpful suggestions.
References
[Braband 2007] Claus Brabrand, Anders Møller and Michael I. Schwartzbach. Dual Syntax for XML Languages.
Aarhus University, 2007, http://cs.au.dk/~amoeller/papers/xsugar/journal.pdf
[Hillman 2022a] Tomos Hillman, C.M. Sperberg-McQueen, Bethan Tovey-Walsh and Norm Tovey-Walsh. Designing for change: Pragmas in Invisible XML as an extensibility mechanism.
Proceedings of Balisage: The Markup Conference 2022. Balisage Series on Markup Technologies, vol. 27, 2022. doi:https://doi.org/10.4242/BalisageVol27.Sperberg-McQueen01
[Hillman 2022b] Tomos Hillman, John Lumley, Steven Pemberton, C.M. Sperberg-McQueen, Bethan Tovey-Walsh
and Norm Tovey-Walsh. Invisible XML coming into focus: Status report from the community group.
Proceedings of Balisage: The Markup Conference 2022. Balisage Series on Markup Technologies, vol. 27, 2022. doi:https://doi.org/10.4242/BalisageVol27.Eccl01
[InvisibleSpec] Steven Pemberton (ed.). Invisible XML Specification.
invisiblexml.org, 2022, https://invisiblexml.org/ixmlspecification.html
[Pemberton 2013] Steven Pemberton. Invisible XML.
Proceedings of Balisage: The Markup Conference 2013. Balisage Series on Markup Technologies, vol. 10, 2013. doi:https://doi.org/10.4242/BalisageVol10.Pemberton01
[Pemberton 2019] Steven Pemberton. On the Specification of Invisible XML.
Proc. XML Prague 2019, 2019, pp 413-430, https://archive.xmlprague.cz/2019/files/xmlprague-2019-proceedings.pdf#page=425
[Pemberton 2024] Steven Pemberton. Round-tripping Invisible XML.
Proc. XML Prague 2024, 2024, pp 153-164, https://archive.xmlprague.cz/2024/files/xmlprague-2024-proceedings.pdf#page=163