The S-series and a Text-based Messaging Standard
When pointy brackets still meant SGML and limitations in computing power resulted in short and cryptic element names, military and civil aircraft manufacturers keen on leveraging the power of markup formed working groups tasked with defining specifications intended to standardise aerospace information management. These specifications, today known as the S series, included everything from technical documentation to logistics and messaging.
S1000D
The technical documentation specification — maintenance procedures, parts data, wiring, etc — is called S1000D [S1000D Specifications]. The first version in widespread use, Issue 1.7, was as a set of SGML DTDs alongside a hefty document describing exactly how to use those DTDs and how to organise the resulting publications.
S1000D has since added support for land and sea vehicles, and moved to XML, dropping DTDs in favour of XML Schemas. The current specification, Issue 5.0, is twice the size of Issue 1.7.
S2000M
The messaging specification, S2000M, defines the processes, procedures and
provides the information for data exchange to be used for material management
throughout the lifecycle of a Product.
Unlike S1000D, the first released
version, Issue 2.1 more than 30 years ago, chose not to use
SGML and instead provided a text-based format. That format was kept very, very
compact to save on that precious computing power, because while the spec is more
than 30 years old today, the equipment it was meant to be used on could be closer
to
30 years old back then.
Of course, S2000M in its latest incarnation, Issue 7.0, is XML, and it, too, is governed by a set of XML Schemas.
The Context
Before we dive head first into a 30-year old text format, a few words about the
context in which all this happens may prove helpful and address some of the more
obvious questions you may have (such as why, oh why?
or but
couldn't you just...?
).
The products described and updated using the S-series of specifications have lifespans of several decades. For example, a jet engine manufactured by a client of the author first flew in the 60s and has been serviced, maintained, and updated ever since. The technical publications for it have had to live for as long — and need to be available for several years after the last of those engines has been retired.
Obviously, the lifespans alone make a good case for markup, but it's complicated. The Illustrated Parts Data (IPD) for that 60s engine started out in a proprietary text-based format in a mainframe computer, and while much of the documentation is now provided in SGML and XML formats, depending on the receiver, that mainframe is still in use and outputs that text-based format, even though the downstream processes have been updated multiple times.
The industry can be surprisingly conservative, partly because the documentation really does need to live for that long, and partly because if you want to keep the planes in the air, making sure the spare parts information remains available is paramount. In other words, an old text format producing IPD pages and another describing IPD messages can be very, very resilient.
In fact, some companies may go about their business day in and day out, producing new engine families, models, and variants, keeping the engines flying and in good shape while knowing that yes, they should replace that mainframe. They really should, but they don't.
Until one day, the decision is made to tear down the building in which the mainframe lives.
A 30-Year Old Text Format
The S2000M 2.1 specification [s2000m-2.1-spec] is 1739 pages. and hardly light bedtime reading, but once you understand the general idea, namely to exchange parts information during the lifecycle of a product, it is quite useful.
Much of it describes formal requirements such as how to identify and locate a part, how to provision a new part, how to provide observations regarding the data from a contractor to a customer, and so on, but a significant portion deals with the specifics of the text format describing the messages themselves, including data dictionaries covering all aspects of the format.
There are several types of messages:
-
Provisioning data; this is split into multiple message types depending on how the parts are identified, and how the parts data is updated and corrected
-
Observations and customer-provided data
-
Codification requests from a contractor
-
Codification data to the contractor
This translates to eight[1] distinct message types, all of which have a similar layout:
-
Header — basic identifier and status information
-
Body — The IP data itself
-
Trailer — sanity check information (number of segments, basic identifier)
The data is kept in segments and data units.
The segments are containers for types of information and contain data units, which
are
basically a key-value construct with a name (TEI
or Text Element
Identifier
) and a value (data element
). The value or data
element can be a composite, containing two or more component data elements.
The spec also explains how to group those messages into larger transmissions, plus a host of other subjects including how the Telex specification will work with S2000M, but I leave those parts to the reader to find out about.
Segments
Segments names are called tags
, a term that obviously means
something else today.[2]
A segment looks like this:
SEG+ABC:123+DEF:456'
This segment, SEG (a tag name, if you insist),
has two data units, ABC and DEF. The segment tag and each
data unit are separated using + characters. The segment is ended using
an apostrophe (').
Data Units
Data units are key-value pairs separated with colons (:). The key,
known as TEI, is before that colon while the value (data
element
) follows after.
Each segment tag and TEI is always identified using three upper-case letters. This is always the case; S2000M only ever uses 3 upper-case letters for segment and TEI identification.[3]
A data element may be a composite value, where several component values are associated with a single TEI:
ABC:12345:AB12:345
The TEI ABC has three components with values 12345
,
AB12
, and 345
, respectively.
The specification lists a number of composite data elements, with each component
having a very specific meaning. The spec spells out each component with a name, a
lower-case TEI, never repeated in the message. For example,
we might say that the data unit with the TEI ABC is a composite with
components def and ghi, but the actual message would
include the ABC data unit as ANC:123:456, with
def having the value 123
and ghi having
the value 456
. In the format, the context is everything; we know that
ABC contains two components, def and
ghi; there is no ambiguity.
The definitions of those basic character (sets) are similarly narrow. For example, we only get upper-case letters, and beyond the numerical characters we only get a handful of characters, such as equal signs, spaces, question marks, and the like.
Data Typing
Each data element — the value — is typed and meant to be usable in systems conceived long before Bill Gates thought 512 k was all it took. The typing lists not only the character sets allowed[4] but also the number of characters allowed. The specification is full of constructs like this:
an..14
This means between 0 and 14 alphanumeric characters. But the spec also lists
things like n..2 (0–2 numerical characters) and a2
(exactly two alphabetic characters).[5] Everything is well defined, but as narrowly as possible.
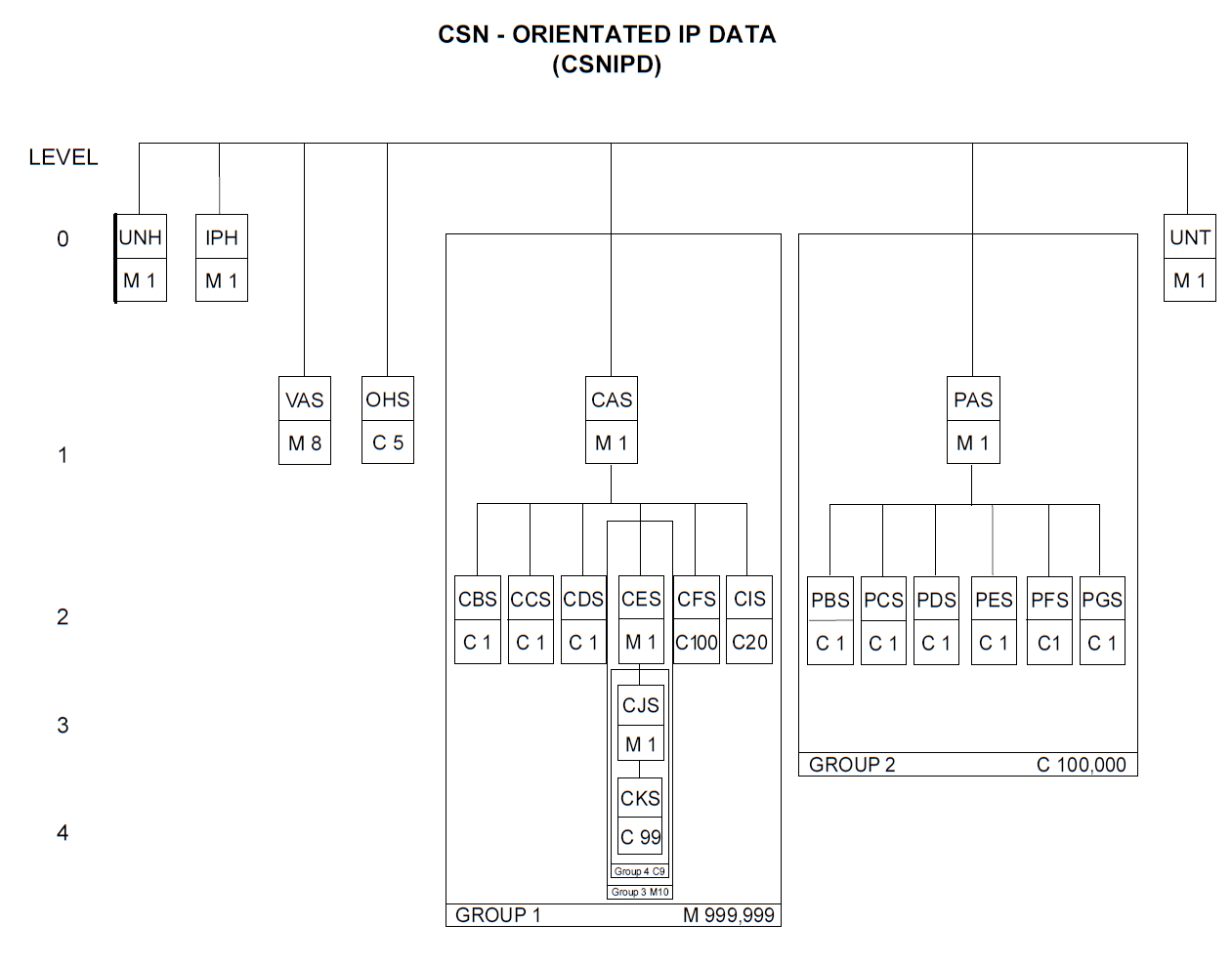
Message Structures
The specification, rather helpfully, includes diagrams outlining the eight message types. Figure 1, for example, outlines the segments in a CSNIPD message; the CSNIPD message is used for the initial IP project definition and provides information on all parts in scope.
Figure 1: CSNIPD Message Segments
The specification also details the message itself (see ), with the data units in the segments.
Figure 2: CSNIPD Message Structure
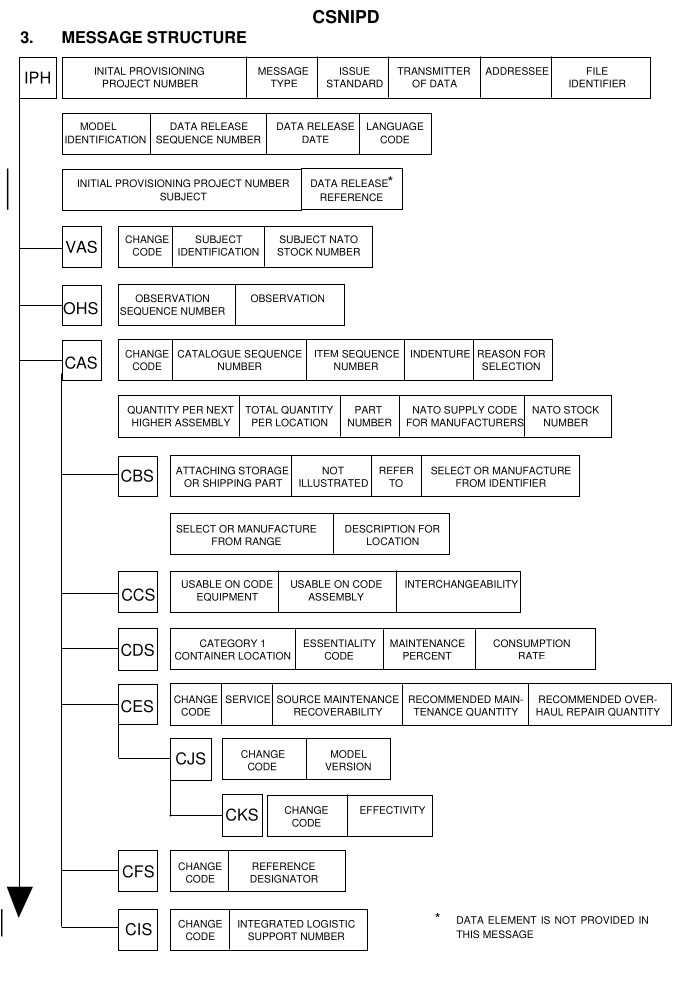
This is only half of the story; there is a second diagram detailing the CSNIPD message in the spec.
The segments are three-letter codes with all but IPH ending with
S
, while the contained data units use the full data unit names
rather than the TEI three-letter abbreviations.
An Example
Here's a CSNIPD message fragment from the spec:
UNH+...' IPH+IPP:F61170026+MTP:CSNIPD+ISS:D1+TOD:F6117+ADD:D1234+FID: S+MOI:1X+DRS:004+DRD:201088+LGE:UK+IPS:LANDING GEAR ASSY' VAS+CHG:N+SID:F6117:A11K400000' OHS+OSN:1+OBS:**PAM PROPOSED FROM 150189 TO 200189' CAS+CHG:N+CSN:32000001 000 +ISN:00A+IND:1+RFS:0+QNA:1+TQL: 1+PNR:A11K400000+MFC:F6117+NSN:1620' CES+CHG:N+SRV:GYL+SMR:XBDDD' CES+CHG:N+SRV:FRA+SMR:XBDDD' CAS+CHG:N+CSN:32000001 001 +ISN:00A+IND:2+RFS:0+QNA:1+TQL: 1+PNR:A11B410100+MFC:F6117' CBS+RTX:32100001 000 00A' CES+CHG:N+SRV....' . . . CAS+CHG:N+CSN:32100001 000 +ISN:00A+IND:1+RFS:0+..... +PNR: A11B410100+MFC:F6117' . . . CAS+CHG:N+CSN:32100002 025 +ISN:00A+IND:2+RES:1+QNA:2+.... PNR:31599BC060LE+MFC:F6117' CBS+ASP:1' CES+CHG:N+SRV:GYL+SMR:PAOZZ +RMQ:10+ROQ:5' CES+CHG:N+SRV:FRA +SMR:PAOZZ +RMQ:20+ROQ:0' . . . CAS+CHG:N+CSN:32100002 036 +ISN:00A+IND:2+RFS:1+QNA:2+... PNR:31599BC060LE+MFC:F6117+NSN:1480:' PAS+CHG:N+PNR:A11K400000+MFC:F6117+DFP:LANDING GEAR ASSEMBLY' . . PAS+CHG:N+PNR:A11B410100+MFC:.....' . PAS+CHG:N+PNR:31599BC060LE+MFC:F6117+DFP:WASHER+INC:13393' PBS+UOI:EA+SPQ:100+TOP:06+CML:1+SPC:1+PLT:3+STR:0+SLC: 0+PLC:A+PCD:A' PDS+UPR:300+CUR:FRF' . . UNT+....'
The headers and trailers are without consequence; the data is mostly in
CAS and PAS segments (and their child segments[6]). The message syntax itself is a series of flat segments and there is
nothing in the format itself to suggest more structure. The above is also far from
complete; more CAS and PAS segments are involved.[7]
Forcing a Change
The industry is traditionally slow to change, having to keep all those planes in the air while being subject to strict regulations. Frequently, change is forced rather than planned, from software no longer being supported to, well, tearing down the building in which a mainframe computer lives.[8]
This paper happened because of the latter. At the time of this writing, the mainframe has a few more months to live, and the migration into new systems and software must be complete by then. There are any number of problems to solve, data to migrate, and processes to replace, and while the approach is to introduce a drop-in replacement for the mainframe — to keep the inputs and outputs as close to the current architecture as possible — the project is still an absolutely massive undertaking.
My role in the project is to make sure that it remains possible to store, process, and send across illustrated parts data to every system that currently depends on the mainframe once that mainframe is decommissioned.[9] Here, it must be noted that currently, the actual Illustrated Parts Catalogues are all produced by either proprietary software converting text-based mainframe output to SGML or XML, or by third parties doing the same, again from various text-based mainframe outputs.
A critical process involves exchanging IPD messages between the client and their partners and customers. The data exchange system and processes were first introduced when the client became involved in a multinational aerospace project. The decision was made to use S2000M, and an implementation was developed for the mainframe system, already 20 years old by then.
You might think that this would be a great opportunity to move to the latest version of the specification, Issue 7.0, and I would agree, in principle. However, the many partners and customers currently do expect S2000M 2.1 and asking them to upgrade is currently not a viable option.
We could also move to 7.0 but convert to and from 2.1 for the back-and-forth exchange, every time. This introduces several other problems, most importantly that the spec is not backwards-compatible to that extent, and certainly not between the very oldest and the very newest issues. Not a viable option either, then.
Sticking with Issue 2.1
The mainframe S2000M implementation is lacking in several respects. There's not
enough processing power and concurrent users are not really a thing; you have to
book time on it, and an entire day is blocked every week for various batch processes
that can't be done during night-time. Authoring and receiving messages is very much
a manual process, involving a series of cryptically named, tiny text-based
screens
where you type in equally cryptic commands or read
incoming messages by flipping through multiple screens. It's not what you might call
an intuitive
UI.
As the S2000M messaging was implemented on top of an upgrade of an earlier system, there are any number of legacy screens and internal logic that are not always fully documented or even understood.[10] Also, as another consequence of the implementation on top of an upgrade, the S2000M segments and data units do not use S2000M naming; instead, they use existing database field names.
It probably goes without saying that we don't actually want to replicate the
mainframe inputs and outputs exactly. For example, there's no need to copy the many
screens to author or present a message, nor is it necessary to keep the downstream
systems that translate between the mainframe S2000M flavour and the
proper
S2000M format. We should be able to handle S2000M
as-is.
But S2000M Issue 2.1 is not widely implemented. If you need it, you need to implement it yourself.[11] At the same time, the client now accepts that the old specifications do need to be upgraded, eventually. The intention is to start using the entire S-series of specifications and start authoring directly in XML in the new system that will eventually include a CSDB.[12] It makes sense, then, to plan for upgrading S2000M as well. Just not now.
But do we actually want to implement a 30-year old text-based specification, especially if it's going to go away soon?
iXML to the Rescue
For the longest time, I thought of iXML [ixml-spec] as a very cool but
maybe not all that useful idea. How wrong I was! Invisible XML [ixml-webpage] is a
language for describing the implicit structure of data, and a set of technologies
for making that structure explicit as XML markup
. The idea is that given an
implicit structure (dates are often provided as examples), it is possible to express
that structure as an iXML grammar and then use the grammar and an iXML application
to
serialise an instance using the grammar in XML format, with explicit structures.
A Simple Example
This is not the place to walk you through iXML — the Invisible XML home on the web [ixml-webpage] links to several tutorials, so start there — but let me give you an example.[13] Given this implicit structure:
SEG+ABC:123+DEF:456'
And this grammar:
SEG = -"SEG", sep, ABC, sep, DEF, segend . -sep = -"+" . -segend = -"'", (#9 | #a0 | #a | #d)* . -comp-sep = -":" . -num = [N] . -n3 = num, num, num . ABC = -"ABC", comp-sep, n3 . DEF = -"DEF", comp-sep, n3 .
We get this XML:
<SEG>
<ABC>123</ABC>
<DEF>456</DEF>
</SEG>But don't take my word for it. John Lumley's implemented an iXML processor running under Saxon JS [lumley-ixml-processor] that allows you to test the above in the browser.
S2000M Grammar Considerations
It turns out that while expressing the S2000M message formats as iXML grammars is
a lot of work, it's perfectly doable. Here's a made-up S2000M
CSNIPD (used for the transmission of IP data which
has been compiled in accordance with the CSN-orientated IP procedure
)
example:
UNH+123456+CD3456:EF1:FD3:C1:ABC123+1234567890ABCDEFGHIJ012345678912345+12:C' IPH+IPP:F61170026+MTP:CSNIPD+ISS:D1+TOD:F6117+ADD:D1234+FID:S+MOI:1X+DRS:004+DRD:201088+LGE:UK+IPS:LANDING GEAR ASSY+DRR:AB123456' VAS+CHG:N+SID:12345:X1234999999999999+SNS:1234:123456789' OHS+OSN:1+OBS:TESTING THIS' CAS+CHG:B+CSN:0123456789123+ISN:ABC+IND:9+RFS:0+QNA:123+TQL:ABCDE+PNR:01234567890+MFC:QWERT+NSN:1234:123456789' CBS+ASP:1+NIL:Q+RTX:1234567890123456+SMF:X+MFM:THIS IS TEXT+DFL:THIS IS MORE TEXT' CCS+UCE:ABCDEFGH+UCA:123456+ICY:AB' CDS+CTL:1234567+ESC:9+MAP:12+CSR:321' CES+CHG:A+SRV:ABC+SMR:654321+RMQ:12345+ROQ:98765' CJS+CHG:C+MOV:BA' CKS+CHG:D+EFY:ABCDEFGH' CFS+CHG:A+RFD:1234567' CIS+CHG:B+ILS:09876543211234567890' PAS+CHG:F+PNR:123456789123456789123456789+MFC:EDCBA+DFP:THIS IS A DFP TEXT+INC:12345+NSN:1234:123456789+RNC:7+RNV:5+RNJ:3' PBS+UOI:AB+SPQ:0123+TOP:QW+ITY:ER+SPC:0+PLT:12+STR:9+SLC:X+PLC:Y+PCD:W' PCS+UOM:AB+QUI:1234' PDS+UPR:123456789012+CUR:ABC+MSQ:54321+PBD:1:2:3000:4:5:11111111' PES+CRT:123+SRA:21+MTI:123456:AB+TBI:123456:CD+TSI:654321:BD+ALI:987654:XY+TLF:123' PFS+DMC:ABC123+HAZ:ED12+PIC:8+FTC:X+PSC:Q+ESD:0+CMK:9' PGS+SUU:AB345678901234+SPU:CD345678901234+WUU:AB34567+WPU:CD34567' UNT+123456+ABCD1234567812'
Much of this won't make sense to you, but we can spot the basic constructs, namely
segments —the rows starting with a three-letter alphabetic code followed by
+ and ending with a segment end character ('). Within
the segments, we can recognise data units, each separated with a plus
(+) and starting with a TEI (Text Element Identifier) followed by
one or more values, each separated with colons (':). The specification
defines the allowed contents for each segment and their respective data units (see
Figure 2
for an overview), and so the remaining work is about expressing those contents in
a
formal grammar.
Many segments are optional, as are many of the contained data units. When they are optional depends on the type of information being carried across by the messages, so some segments will only appear depending of the item being described or if other segments are used.
Figure 2 may
help illustrate this. The CAS segment provides mandatory
location-related information about the item, but the C
segments
CBS, CCS, CDS and CFS that
follow are only provided depending on the nature of the item. Those segments are
effectively child segments to CAS and do not appear without it. S2000M
does not define such a concept, but it is helpful to think of them in that
way.
{
This is an iXML grammar for S2000M CSNIPD messages.
S2000M spec 2.1: https://www.s2000m.org/S2000M/S2000M%20Issue%202.1%20CP1-4.pdf
iXML information: https://invisiblexml.org/
Grammar tested with https://johnlumley.github.io/jwiXML.xhtml
}
CSNIPD = UNH, IPH, VAS+, OHS*, CAS+, PAS*, UNT .
@segend = -"'", (#9 | #a0 | #a | #d)* .
-sep = -"+" .
-comp-sep = -":" .
-alpha = [L] .
-num = [N] .
-other-level-a = [" !.,(;&<>%*=)"; #22] .
-an = (alpha | num | other-level-a) .
-num4 = num, num, num, num .
-num9 = num, num, num, num, num, num, num, num, num .
-num0-2 = (num? | num, num) .
-num0-3 = (...) .
-num0-4 = (...) .
-num0-5 = (...) .
-num0-6 = (...) .
-num0-12 = (...) .
-an2 = an, an .
-an3 = an, an, an .
-an4 = (...) .
-an5 = (...) .
-an6 = (...) .
-an7 = (...) .
-an8 = (...) .
-an9 = (...) .
-an13 = (...) .
-an14 = (...) .
-an0-2 = (an? | an, an) .
-an0-3 = (...) .
-an0-4 = (...) .
-an0-5 = (...) .
-an0-6 = (...) .
-an0-7 = (...) .
-an0-8 = (...) .
-an0-14 = (...) .
-an0-16 = (...) .
-an0-19 = (...) .
-an0-20 = (...) .
-an0-32 = (...) .
-an0-35 = (...) .
no-segments-0074 = num0-6 .
msg-no-0062 = an0-14 .
msg-type-0065 = an0-6 .
msg-version-nbr-0052 = an0-3 .
msg-rel-nbr-0054 = an0-3 .
ctrl-agency-0051 = an0-2 .
assoc-assign-code-0057 = an0-6 .
message-identifier-S009 = msg-type-0065, comp-sep, msg-version-nbr-0052, comp-sep, msg-rel-nbr-0054, comp-sep, ctrl-agency-0051, comp-sep, assoc-assign-code-0057? .
common-access-ref-0068 = an0-35 .
sequence-transfers-0070 = num0-2 .
first-last-transfer-0073 = alpha . {C or F - should it be checked here?}
transfer-status-S010 = sequence-transfers-0070, comp-sep, first-last-transfer-0073 .
UNH = -"UNH", sep, msg-no-0062, sep, message-identifier-S009, sep, common-access-ref-0068, sep, transfer-status-S010, segend .
UNT = -"UNT", sep, no-segments-0074, sep, msg-no-0062, segend .
IPP = -"IPP", comp-sep, an9 .
MTP = -"MTP", comp-sep, an0-6 .
ISS = -"ISS", comp-sep, an, an .
TOD = -"TOD", comp-sep, an5 .
ADD = -"ADD", comp-sep, an5 .
FID = -"FID", comp-sep, alpha .
MOI = -"MOI", comp-sep, an, an .
DRS = -"DRS", comp-sep, num, num, num .
DRD = -"DRD", comp-sep, num, num, num, num, num, num .
LGE = -"LGE", comp-sep, alpha, alpha .
IPS = -"IPS", comp-sep, an0-19 .
DRR = "DRR", comp-sep, an8 .
IPH = -"IPH", sep, IPP, sep, MTP, (sep, ISS)?, sep, TOD, sep, ADD, sep, FID, sep, MOI, sep, DRS, sep, DRD, sep, LGE, sep, IPS, (sep, DRR)?, segend .
CHG = -"CHG", comp-sep, alpha .
mfc = an5 .
pnr = an0-32 .
SID = -"SID", comp-sep, mfc, comp-sep, pnr .
nsc = num4 .
nin = num9 .
SNS = -"SNS", (comp-sep, nsc)?, (comp-sep, nin)? .
VAS = -"VAS", sep, CHG, sep, SID, (sep, SNS)?, segend .
OSN = -"OSN", comp-sep, num .
OBS = -"OBS", comp-sep, an* . {This is 0-130 chars}
OHS = -"OHS", sep, OSN, sep, OBS, segend .
CSN = -"CSN", comp-sep, an13 .
ISN = -"ISN", comp-sep, an3 .
IND = -"IND", comp-sep, num .
RFS = -"RFS", comp-sep, num .
QNA = -"QNA", comp-sep, an0-4 .
TQL = -"TQL", comp-sep, an0-5 .
PNR = -"PNR", comp-sep, -pnr .
MFC = -"MFC", comp-sep, -mfc .
NSN = -"NSN", comp-sep, nsc, (comp-sep, nin)? .
CAS = -"CAS", sep, CHG, sep, CSN, sep, ISN, (sep, IND)?, (sep, RFS)?, (sep, QNA)?, (sep, TQL)?, (sep, PNR)?, (sep, MFC)?, (sep, NSN)?, segend, (CBS?, CCS?, CDS?, CES, CFS?, CIS?)? .
ASP = -"ASP", comp-sep, num .
NIL = -"NIL", comp-sep, an .
RTX = -"RTX", comp-sep, an0-16 .
SMF = -"SMF", comp-sep, alpha .
MFM = -"MFM", comp-sep, an* {0-40 alphanumeric chars} .
DFL = -"DFL", comp-sep, an* {0-130 alphanumeric chars} .
CBS = -"CBS", (sep, ASP)?, (sep, NIL)?, (sep, RTX)?, (sep, SMF)?, (sep, MFM)?, (sep, DFL)?, segend .
UCE = -"UCE", comp-sep, an8 .
UCA = -"UCA", comp-sep, an6 .
ICY = -"ICY", comp-sep, an, an .
CCS = -"CCS", (sep, UCE)?, (sep, UCA)?, (sep, ICY)?, segend .
CTL = -"CTL", comp-sep, an7 .
ESC = -"ESC", comp-sep, num .
MAP = -"MAP", comp-sep, num0-2 .
CSR = -"CSR", comp-sep, num0-3 .
CDS = -"CDS", (sep, CTL)?, (sep, ESC)?, (sep, MAP)?, (sep, CSR)?, segend .
SRV = -"SRV", comp-sep, an0-3 .
SMR = -"SMR", comp-sep, an0-6 .
RMQ = -"RMQ", comp-sep, num0-5 .
ROQ = -"ROQ", comp-sep, num0-5 .
CES = -"CES", sep, CHG, sep, SRV, (sep, SMR)?, (sep, RMQ)?, (sep, ROQ)?, segend, CJS* .
RFD = -"RFD", comp-sep, an0-7 .
CFS = -"CFS", sep, CHG, sep, RFD, segend .
ILS = -"ILS", comp-sep, an0-20 .
CIS = -"CIS", sep, CHG, sep, ILS, segend .
MOV = -"MOV", comp-sep, an0-2 .
CJS = -"CJS", sep, CHG, sep, MOV, segend, CKS* .
EFY = -"EFY", comp-sep, an0-8 .
CKS = -"CKS", sep, CHG, sep, EFY, segend .
DFP = -"DFP", comp-sep, an* {0-130 alphanumeric} .
INC = -"INC", comp-sep, an5 .
RNC = -"RNC", comp-sep, an .
RNV = -"RNV", comp-sep, num .
RNJ = -"RNJ", comp-sep, num .
PAS = -"PAS", sep, CHG, sep, PNR, sep, MFC, (sep, DFP)?, (sep, INC)?, (sep, NSN)?, (sep, RNC)?, (sep, RNV)?, (sep, RNJ)?, segend, (PBS?, PCS?, PDS?, PES?, PFS?, PGS?)? .
UOI = -"UOI", comp-sep, alpha, alpha .
SPQ = -"SPQ", comp-sep, num0-4 .
TOP = -"TOP", comp-sep, an2 .
ITY = -"ITY", comp-sep, an2 .
SPC = -"SPC", comp-sep, num .
PLT = -"PLT", comp-sep, num0-2 .
STR = -"STR", comp-sep, num .
SLC = -"SLC", comp-sep, an .
PLC = -"PLC", comp-sep, an .
PCD = -"PCD", comp-sep, an0-2 .
PBS = -"PBS", (sep, UOI)?, (sep, SPQ)?, (sep, TOP)?, (sep, ITY)?, (sep, SPC)?, (sep, PLT)?, (sep, STR)?, (sep, SLC)?, (sep, PLC)?, (sep, PCD)?, segend .
UOM = -"UOM", comp-sep, an2 .
QUI = -"QUI", comp-sep, num0-4 .
PCS = -"PCS", (sep, UOM)?, (sep, QUI)?, segend .
UPR = -"UPR", comp-sep, num0-12 .
CUR = -"CUR", comp-sep, alpha, alpha, alpha .
MSQ = -"MSQ", comp-sep, num0-5 .
qty = num0-5 .
upr = num0-12 .
PBD = -"PBD", comp-sep, qty, comp-sep, qty, comp-sep, upr, (comp-sep, qty, comp-sep, qty, comp-sep, upr)* {0-2 repetitions} .
PDS = -"PDS", (sep, UPR)?, (sep, CUR)?, (sep, MSQ)?, (sep, PBD)?, segend .
CRT = -"CRT", comp-sep, num0-3 .
SRA = -"SRA", comp-sep, num0-2 .
-alpha0-2 = (alpha? | alpha, alpha) .
tbf = num0-6 .
tcm = alpha0-2 .
MTI = -"MTI", (comp-sep, tbf)?, (comp-sep, tcm)? .
tbo = num0-6 .
tco = alpha0-2 .
TBI = -"TBI", (comp-sep, tbo)?, (comp-sep, tco)? .
tsv = num0-6 .
tcs = alpha0-2 .
TSI = -"TSI", (comp-sep, tsv)?, (comp-sep, tcs)? .
aul = num0-6 .
tca = alpha0-2 .
ALI = -"ALI", (comp-sep, aul)?, (comp-sep, tca)? .
TLF = -"TLF", comp-sep, num0-3 .
PES = -"PES", (sep, CRT)?, (sep, SRA)?, (sep, MTI)?, (sep, TBI)?, (sep, TSI)?, (sep, ALI)?, (sep, TLF)?, segend .
DMC = -"DMC", comp-sep, an0-6 .
HAZ = -"HAZ", comp-sep, an4 .
PIC = -"PIC", comp-sep, num .
FTC = -"FTC", comp-sep, an .
PSC = -"PSC", comp-sep, an .
ESD = -"ESD", comp-sep, num .
CMK = -"CMK", comp-sep, num .
PFS = -"PFS", (sep, DMC)?, (sep, HAZ)?, (sep, PIC)?, (sep, FTC)?, (sep, PSC)?, (sep, ESD)?, (sep, CMK)?, segend .
SUU = -"SUU", comp-sep, an14 .
SPU = -"SPU", comp-sep, an14 .
WUU = -"WUU", comp-sep, an7 .
WPU = -"WPU", comp-sep, an7 .
PGS = -"PGS", (sep, SUU)?, (sep, SPU)?, (sep, WUU)?, (sep, WPU)?, segend .The XML serialisation is as follows:
<CSNIPD>
<UNH segend=" ">
<msg-no-0062>123456</msg-no-0062>
<message-identifier-S009>
<msg-type-0065>CD3456</msg-type-0065>
<msg-version-nbr-0052>EF1</msg-version-nbr-0052>
<msg-rel-nbr-0054>FD3</msg-rel-nbr-0054>
<ctrl-agency-0051>C1</ctrl-agency-0051>
<assoc-assign-code-0057>ABC123</assoc-assign-code-0057>
</message-identifier-S009>
<common-access-ref-0068>1234567890ABCDEFGHIJ012345678912345</common-access-ref-0068>
<transfer-status-S010>
<sequence-transfers-0070>12</sequence-transfers-0070>
<first-last-transfer-0073>C</first-last-transfer-0073>
</transfer-status-S010>
</UNH>
<IPH segend=" ">
<IPP>F61170026</IPP>
<MTP>CSNIPD</MTP>
<ISS>D1</ISS>
<TOD>F6117</TOD>
<ADD>D1234</ADD>
<FID>S</FID>
<MOI>1X</MOI>
<DRS>004</DRS>
<DRD>201088</DRD>
<LGE>UK</LGE>
<IPS>LANDING GEAR ASSY</IPS>
<DRR>DRRAB123456</DRR>
</IPH>
<VAS segend=" ">
<CHG>N</CHG>
<SID>
<mfc>12345</mfc>
<pnr>X1234999999999999</pnr>
</SID>
<SNS>
<nsc>1234</nsc>
<nin>123456789</nin>
</SNS>
</VAS>
<OHS segend=" ">
<OSN>1</OSN>
<OBS>TESTING THIS</OBS>
</OHS>
<CAS segend=" ">
<CHG>B</CHG>
<CSN>0123456789123</CSN>
<ISN>ABC</ISN>
<IND>9</IND>
<RFS>0</RFS>
<QNA>123</QNA>
<TQL>ABCDE</TQL>
<PNR>01234567890</PNR>
<MFC>QWERT</MFC>
<NSN>
<nsc>1234</nsc>
<nin>123456789</nin>
</NSN>
<CBS segend=" ">
<ASP>1</ASP>
<NIL>Q</NIL>
<RTX>1234567890123456</RTX>
<SMF>X</SMF>
<MFM>THIS IS TEXT</MFM>
<DFL>THIS IS MORE TEXT</DFL>
</CBS>
<CCS segend=" ">
<UCE>ABCDEFGH</UCE>
<UCA>123456</UCA>
<ICY>AB</ICY>
</CCS>
<CDS segend=" ">
<CTL>1234567</CTL>
<ESC>9</ESC>
<MAP>12</MAP>
<CSR>321</CSR>
</CDS>
<CES segend=" ">
<CHG>A</CHG>
<SRV>ABC</SRV>
<SMR>654321</SMR>
<RMQ>12345</RMQ>
<ROQ>98765</ROQ>
<CJS segend=" ">
<CHG>C</CHG>
<MOV>BA</MOV>
<CKS segend=" ">
<CHG>D</CHG>
<EFY>ABCDEFGH</EFY>
</CKS>
</CJS>
</CES>
<CFS segend=" ">
<CHG>A</CHG>
<RFD>1234567</RFD>
</CFS>
<CIS segend=" ">
<CHG>B</CHG>
<ILS>09876543211234567890</ILS>
</CIS>
</CAS>
<PAS segend=" ">
<CHG>F</CHG>
<PNR>123456789123456789123456789</PNR>
<MFC>EDCBA</MFC>
<DFP>THIS IS A DFP TEXT</DFP>
<INC>12345</INC>
<NSN>
<nsc>1234</nsc>
<nin>123456789</nin>
</NSN>
<RNC>7</RNC>
<RNV>5</RNV>
<RNJ>3</RNJ>
<PBS segend=" ">
<UOI>AB</UOI>
<SPQ>0123</SPQ>
<TOP>QW</TOP>
<ITY>ER</ITY>
<SPC>0</SPC>
<PLT>12</PLT>
<STR>9</STR>
<SLC>X</SLC>
<PLC>Y</PLC>
<PCD>W</PCD>
</PBS>
<PCS segend=" ">
<UOM>AB</UOM>
<QUI>1234</QUI>
</PCS>
<PDS segend=" ">
<UPR>123456789012</UPR>
<CUR>ABC</CUR>
<MSQ>54321</MSQ>
<PBD>
<qty>1</qty>
<qty>2</qty>
<upr>3000</upr>
<qty>4</qty>
<qty>5</qty>
<upr>11111111</upr>
</PBD>
</PDS>
<PES segend=" ">
<CRT>123</CRT>
<SRA>21</SRA>
<MTI>
<tbf>123456</tbf>
<tcm>AB</tcm>
</MTI>
<TBI>
<tbo>123456</tbo>
<tco>CD</tco>
</TBI>
<TSI>
<tsv>654321</tsv>
<tcs>BD</tcs>
</TSI>
<ALI>
<aul>987654</aul>
<tca>XY</tca>
</ALI>
<TLF>123</TLF>
</PES>
<PFS segend=" ">
<DMC>ABC123</DMC>
<HAZ>ED12</HAZ>
<PIC>8</PIC>
<FTC>X</FTC>
<PSC>Q</PSC>
<ESD>0</ESD>
<CMK>9</CMK>
</PFS>
<PGS segend=" ">
<SUU>AB345678901234</SUU>
<SPU>CD345678901234</SPU>
<WUU>AB34567</WUU>
<WPU>CD34567</WPU>
</PGS>
</PAS>
<UNT segend="">
<no-segments-0074>123456</no-segments-0074>
<msg-no-0062>ABCD1234567812</msg-no-0062>
</UNT>
</CSNIPD>Notable in the XML are a few handy tweaks. For example, every segment — remember
the constructs starting with a segment name (tag
) and ending with an
apostrophe? — has a @segend attribute, making it easy to differentiate
between segments and data units.[14] A composite data unit's components are named and, just as declared in
the specification, use lower-case letters.
Note
An earlier version of the grammar added an explicit notion of child segments,
and there was also grouping based on the multiple groups
described by the specification, but I've since removed them, based on end user
input.
All this becomes useful later, when publishing the XML in S2000M format (see section “Input and Output”).
Lengthy Productions
You'll notice in the CSNIPD grammar that I've edited some of the productions
to only contain ... rather than the full model. The problem is that
if I am to express a model such as 0 to 3 numeric characters, the iXML grammar
rules will have me do this (here, n represents a production
defining a single digit):
n0-3 = (n? | n, n | n, n, n ) .
A production defining a range between 0 and 130 numerical characters will be quite a bit longer.[15] Obviously, you can define a production using something like exactly 10 characters and then repeat that production where you need it:
n10 = n, n, n, n, n, n, n, n, n, n .
The result will still be a fair number of lengthy productions.
Syntactic Sugar
You'll notice that some productions begin with a - sign:
-an0-2 = (an? | an, an) .
Others include a - sign before a literal string (CHG
within quotes, right after the equal sign):
CHG = -"CHG", comp-sep, alpha .
This means that the XML serialisations should not output the production or literal as elements.
Data Types
The S2000M 2.1 specification made it obvious that memory was precious, 30 years ago. If a data element only requires a single character, that is what you get. A textual data element might contain up to 130 characters, which is rather excessive for the specification; much more common is either a range up to no more than 6 or a fixed length of no more than what is absolutely necessary.
The allowed character sets are very limited, too, allowing only for digits, the upper-case English alphabet, spaces, question marks, and a few others:
-alpha = [L] . -num = [N] . -other-level-a = [" !.,(;&<>%*=)"; #22] . -an = (alpha | num | other-level-a) .
Here, alpha is more permissive than S2000 M; more correct is
probably [Lu] (the Unicode character class for uppercase letters
only).
Some characters in S2000M are restricted, as they represent control
characters: apostrophes, plus signs, colons and question marks. Question marks
are release characters
(escape characters
in
today's parlance).
So, Now That I've Got the XML...
...what do I do with it?
Well, XML, unlike S2000M Issue 2.1, has a full ecosystem with editors, transformation languages, etc. To start with, can we author messages using the XML format?
Validation
If we are to use the serialised XML for authoring we will need a schema. Or, in my case, a DTD. Relax NG wasn't an option, and if I have to choose between DTDs and W3C XML Schemas, I'll pick DTDs every time.
The dependencies between the various segments aren't something you can express
in a schema, beyond basic ordering and nesting, but Schematron rules, in many
cases, can. For example, there is a requirement in the spec that a message
number given in the message header (UNH) is repeated in the message
trailer (UNT). Looking at the grammar, above we find the
msg.no production in both:
UNH = -"UNH", sep, msg-no-0062, sep, message-identifier-S009, sep, segend . UNT = -"UNT", sep, no-segments-0074, sep, msg-no-0062, segend .
Here's the header in XML format:
<UNH segend=" ">
<msg-no-0062>123456</msg-no-0062>
...
</UNH>And here's the trailer:
<UNT segend="">
...
<msg-no-0062>ABCD1234567812</msg-no-0062>
</UNT>All we have to do is to create a Schematron rule that checks if the two
message identifiers (msg-type-0062) are the same. In this case,
they are not, meaning that the test should fail.
A combination of DTD validation and Schematron rules can express many, if not all[16], rules expressed either directly or indirectly in the S2000M specification.
Generating the DTD
Rather than writing the DTD by hand, I chose to generate it in oXygen XML Editor by feeding it with a number of examples serialised as XML from S2000M text messages, from the bare minimum to the maximum allowed. Most were not realistic — the various combinations wouldn't make sense to an IP engineer — but they did cover the many permutations allowed by the specification. Of course, this works only if the S2000M message structure is actually expressible in a DTD.
But is it? For example, I mention in section “S2000M Grammar Considerations” that the various C
segments — CAS, CBS, CCS, etc — imply
a segments and child segments hierarchy, even though the message syntax is
flat. You'll have to read the spec to know that:
CAS+CHG:B+...+NSN:1234:123456789' CBS+ASP:1+...+DFL:THIS IS MORE TEXT' CCS+UCE:ABCDEFGH+UCA:123456+ICY:AB'
The spec implies this:
CAS ├── CBS └── CCS
In an XML DTD, this might be represented like so:
<!ELEMENT CAS (%cas.content;, CBS?, CCS?)
In the grammar, the equivalent is this:
CAS = -"CAS", ... , segend, (CBS?, CCS?) .
This skips most of the CAS segment content; see section “S2000M Grammar Considerations” for the full example. Importantly,
the segend marks the end of the current hierarchy level;
everything following is a child segment.
DTD Additional Modelling
The spec illustrations (see Figure 1) add numbered levels to the segment hierarchy. These are not in the message syntax; you need to read the spec to know about them. They add dependencies to the segment hierarchy, and a higher level must always relate to data contained in the next lower level. For example, level 1 segments must always relate to level 0 segments.
As such, they provide essential information about the segment and child
segment relations, information we can use to fully validate a message.
Directly adding them to the grammar causes an overlap problem, however; for
example, both CAS and PAS child segments are level
2 segments, but they have different parents.
As I believe there is no way to add a production to the grammar to
represent an XML attribute with different values depending on the segment, I
settled with adding the level information as #FIXED attributes
to the DTD after generation[17]:
<!ELEMENT CBS (ASP?,NIL?,RTX?,SMF?,MFM?,DFL?)> <!ATTLIST CBS level CDATA #FIXED "2" segend CDATA #REQUIRED>
Another S2000M implied construct is the groups (see Figure 1). These are used to what the allowed number of occurrences the segments in a group is, but also how those groups would appear in the explicit syntax.
Unlike levels, I've elected not to express these in the XML, at least not yet, because while the text format in the spec does need them to make the occurrences obvious to the user, the XML serialisation does not. The XML serialisation hierarchies should be enough.
Schematron Notes
The Schematron rules are useful for checking data types (numeric, upper-case letters, some special characters, or a combination thereof; note that the character sets are actually very small), of course, as well as the number of characters allowed for each S2000M data unit; rather than using an iXML grammar-provided (and lengthy) production declaring a model from 0 to 130 alphanumeric characters, we can do that check in a Schematron rule.[18]
There are rules concerning how many times segments can be repeated, there are various conditions on when some data units may appear, and there are sanity checks for the messages themselves, e.g. the message trailer repeats an identifier also found in the header, there is a segment count, and so on.
Authoring Considerations
The idea of authoring S2000M 2.1 messages as XML was presented with a proof of concept where I implemented a tiny authoring environment in oXygen XML Editor. A generated DTD, Schematron rules, and some CSS was enough.
But this was a bit like taking an 18-wheeler for shopping groceries a quiet Thursday night. It works, but it's unnecessarily complicated and there is really no need. There are very few free text fields, and most of the data is either from predefined controlled lists or retrievable from engineering databases.
Context
The messages do not happen in a vacuum but rather as part of other engineering
tasks. The product itself is commonly handled as a hierarchical tree known as a
build of materials
or BOM. In that tree, the root is the
product, and the nodes are the parts and kits (groups of parts) that together
form the product. So when you, say, add a part, the part is a node in that tree,
and the various properties of that part — part number, quantity, etc — are
attached to the node as attributes
[19], metadata about the part.
The node has an address
, a location in the product. In the
aerospace industry, there are standardised approaches for those locations. The
ATA 2200 specification, for example, places the various physical components of
an aeroplane in numbered chapters where the numbers exactly match specific
components. For example, 71 is power plant and 72 is engine. The chapters are
then divided into sections and the sections into subjects, and addressing an
assembly task might look like the example in Figure 3:
Figure 3: ATA Number for a Task
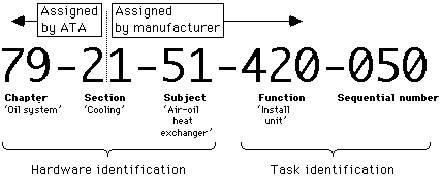
S1000D has a similar approach, as parts of that specification was derived from ATA. It, like S2000M, uses SNS (Standard Numbering System) to identify a component's system, subsystem, sub-subsystem, down to an assembly or unit.
This is the context in which the S2000M messaging happens, the idea being that the messages are directly about an assembly or unit, a node in the BOM.[20] Thus, much of the information is either in the BOM itself or it should be attached to a node in the BOM as metadata.
This paper is not the place to discuss the larger picture, however.
Input and Output
Messaging is a two-way communication. You author messages, and you read responses.
The incoming messages are S2000M text messages and need to be fed through the iXML processor to be serialised as XML. The XML can then be opened in an editor, of course, but it can also be published in some suitable format using an XSLT conversion.
The outgoing messages are authored in XML format (see section “Authoring Considerations”) but in order for the receiver to process them, the XML needs to be converted to an S2000M text message. This requires no more than a few lines of XSLT — which, of course, is expected. If we have a context-free iXML grammar for S2000M, it follows that the resulting XML is a lossless representation of the same[21], and it should therefore be possible to do a round trip.
Reviews
The lifecycle of an aerospace product means decades of updates, tweaks, and
fixes, all of which need to be thoroughly reviewed before a new version of the
product can fly. The data exchanges between manufacturers, partners, and others
reflect the work involved in those changes and form a paper trail
for later reviews.
The mainframe messages for those updates used to be converted to an Excel spreadsheet using a set of macros, but processing and storing the messages as XML does away with the macros — we can easily convert the XML to Excel spreadsheets, but also to any other suitable format for reviewing purposes.
In Conclusion
This is very much an ongoing project. As I write this, I have a proof-of-concept solution with iXML grammars, draft DTDs and accompanying Schematron rules, plus XSLT stylesheets to output the XML in various formats. The form-based authoring environment is yet to follow, and there is much more work left to finalise the DTDs and the Schematron rules.
The system that handles the BOMs is similarly a work in progress; it is being built around and in Siemens Teamcenter, a large software kit handling engineering data in any number of contexts and configurations.
Future State
The current project is very much about replacing a mainframe that is scheduled to be decommissioned later this year. It does not attempt to replace or redesign any downstream system that can continue to function if we replicate the necessary data flows to and from the mainframe. What we are doing should be seen as a drop-in replacement for the mainframe.
But that's an extremely inefficient way to move away from 60s technology, so there
is also a future state
, one where the various old downstream systems
and text formats are replaced with IPD authoring directly in the system, using
state-of-the-art software and up-to-date S-series specifications. And so, yes, the
S2000M messaging iXML solution described in this paper will be replaced by Issue 7.x
and up-to-date XML Schemas.
The cool thing about this is that while moving to the latest issue is a big project, replacing the iXML-based authoring with 7.x is not. The basic functionality coupling the messages with the BOM will likely be reusable, even though some metadata will certainly change. If we replace an XML-based authoring approach with another, we are not starting from scratch. It's all authored, viewed, and published using XML technologies, so much of that functionality and logic can stay. It will have to be updated, yes, but we don't need to throw everything away this time.
The XML is here to stay.
References
[S1000D Specifications] S1000D
Specifications
[online, fetched on 3 April 2024]. https://users.s1000d.org/Default.aspx
[s2000m-2.1-spec] S2000M Issue 2.1
[online, fetched on 3
April 2024]. https://www.s2000m.org/S2000M/S2000M%20Issue%202.1%20CP1-4.pdf
[ixml-spec] Invisible XML Specification
[online, fetched
on 4 April]. https://invisiblexml.org/1.0/
[ixml-webpage] Invisible XML
[online, fetched on 4 April
2024]. https://invisiblexml.org/
[lumley-ixml-processor] jωiXML processor
[online, fetched
on 4 April 2024]. https://johnlumley.github.io/jwiXML.xhtml
[1] There is a 9th message type, used for error handling.
[2] And did back then; I don't think the working group cared.
[3] Remember what I mentioned above, about saving that precious computing power?
[4] And I use the phrase liberally.
[5] Yes, you really do get the feeling that space was at a premium.
[6] The child segment term is not in the spec; these are segments that I
consider to be within CAS and PAS, respectively.
There is a very clear grouping and nesting of components within segments in
the spec, but you can also argue that there is overlap rather than
hierarchy. I choose to go with hierarchy.
[7] The two segments depend on one another, which again is not something apparent in the format itself.
[8] You could say that the building and the mainframe are a single unit; it's not
obvious which is built into which. The one joke the client is really tired of
hearing is So, how much do these things weigh? Maybe we could all pitch
in?
[9] There are a number of other potential subjects for Balisage papers there. Alas, there is no time.
[10] Many of the original engineers are no longer able to provide assistance.
[11] Some off-the-shelf solutions do exist but they all bring with them other problems.
[12] Common Source Database, an S1000D term for what is essentially a specialised CMS and publishing platform for S1000D content. Implementing the full S-series requires a single, common repository for all of the data.
[13] And I'm sure you can see where this is going.
[14] No, the attribute value is of no interest whatsoever. The existence of the attribute itself is enough.
[15] The specification specifies different ranges for many of the close to 300 data units.
[16] For example, neither a DTD, nor a Schematron, can express some S2000M
segment dependencies, such as the CBS segment only
appearing depending on the nature of the item given location-related
information in the preceding CAS segment. The grammar
itself does not address the mechanics of such dependencies, only that
they exist.
[17] And very quickly learned to not tweak the generated DTD until the grammar is stable.
[18] It turned out that these could be generated in their entirety. The customer had an Excel spreadsheet with every segment and data unit listed alongside with the data types, so generating the rules was a matter of writing an XSLT to process the spreadsheet.
[19] Not necessarily in the XML sense of the word.
[20] I am but a humble pointy bracket professional, and there is much more to engineering and spare part BOMs, but this is where the S-series becomes powerful; the approach fits with that taken in engineering.
[21] An interesting exercise, outside the scope of this paper, is to prove this.