Introduction
We have previously used the term XML Storage Systems to describe a range of systems which are used to store XML (structured) data [Paxton 2024]. This encapsulates processors which implement one-off XML parsing and transformation, systems which store XML files whole (and perhaps allow processing of them), systems which decompose XML documents and store them in another storage system (perhaps a SQL DB) and so-called Native XML Databases, in which collections of XML documents are decomposed and stored within a system which supports efficient retrieval, reconstruction, analysis and update of the documents.
While an XML Processor like Saxon [Saxon Processor] is focused on one-off processing of documents, Native XML Databases such as FusionDB [FusionDB], Elemental [Elemental], BaseX [BaseX], and eXist-db [eXist-db] are designed to handle data which is repeatedly accessed, and potentially updated. As their name suggests, they are much closer to traditional SQL and NoSQL Databases in the concerns they address; they just manage XML structured data.
Native XML Databases and XML Processors share a common, standardized query language for XML in [XQuery 3.1]. The standardization of XQuery offered an obvious basis on which to measure, compare and contrast the performance of XML Storage Systems. The XMark Project [Schmidt 2002] defined a canonical XML data collection and a set of XQuery queries over that collection. The XMark data collection and queries have been widely used to assess the relative performance of multiple XML Storage Systems, for instance by [Lu 2005].
The term database testbed was introduced by [Difallah 2013] in the context of their system OLTP-Bench, which was designed to flexibly control, manage and extract metrics from the benchmarking of OLTP systems. Observing that the core benchmark code was only a small part of a realistic production-quality benchmark, led to the understanding that the infrastructure of dispatch, monitoring and metric extraction and reporting was a problem that could be solved within a testbed which allowed for easier construction of new benchmarks in future.
In the NoSQL space, the YCSB system [YCSB10] predates OLTP-Bench, and is a database testbed in practice if not in name. More recently, NoSQLBench [NoSQLBench], [DataStax 2020] has embraced the testbed ethos, and has united pluggable adapters for database instances with the concept of Virtual Data Sets, a flexible and powerful means of generating large, pseudo-random but repeatable synthetic data with which to drive benchmarks.
The continued progress in benchmarking of NoSQL and OLTP systems exposes the relative lack of progress in benchmarking XML Databases. Much of the literature on the subject of XML benchmarking is not recent, and a review such as [Mlýnková 2008] remains relevant. We have revisited the XML Benchmarking landscape in this paper [Paxton 2024] in detail, and have proposed a way forward by adopting NoSQLBench as a testbed, adapting it with an XML:DB driver to operate with standardized XML Databases, and enhanced it with a Virtual Data Set(VDS) based library for generating synthetic XML database collections.
In the rest of this paper we restate our goals in developing an XML Benchmarking testbed, and describe the recent progress we have made towards them.
-
In the section: section “Architecture of the XML Benchmark Testbed” we describe the current architecture of our testbed.
-
In the section: section “Running XMark in the Testbed” we demonstrate what is involved in running individual benchmarks in our testbed, using the XMark benchmarks of [Schmidt 2002] as our example. We show that the level of automation we have currently achieved already makes this a practical system.
-
In the section: section “A Comparison of XMark xmlgen and xmlgen2 Auction Data” we compare the results of the XMark benchmarks when run against the original auction database generated by
XMark xmlgenwith the results when run againstxmlgen2, our re-implementation ofxmlgenutilising our new testbed framework. We have set up this comparison as a checkpoint of the capabilities of our testbed. -
In the section: section “Conclusions and Future Work” we discuss what we have achieved so far in using NoSQLBench as an XML Benchmarking testbed, how successful it has been, and what can usefully still be done to improve it.
Architecture of the XML Benchmark Testbed
The OLTP-Bench paper [Difallah 2013] defines the goals of benchmark testbeds as:
-
control the data set and workload for testing
-
automate the extraction of metrics from test runs
-
ensure these runs are repeatable
-
Test data generation/loading
-
Benchmark setup, query ramp-up, run and teardown
-
Metric collection
Benchmark run
In order to run NoSQLBench benchmarks with XML databases, NoSQLBench must be able
to interact with XML databases.
NoSQLBench interacts with NoSQL databases using adapters which fit into a framework which it defines.
This allows 3rd parties to create adapters to implement interaction with other databases,
and in practice XML Storage
Systems can just as well fit in the adapter framework.
The standard XML:DB API [XML:DB] is the obvious candidate for this, and so the first artifact
we have created is an XML:DB adapter for NoSQLBench.
Adapter
XML:DB API is database agnostic, and may be used to access any XML database that supports it. Our XML:DB adapter is compatible with [FusionDB], [Elemental], and [eXist-db].
The XML:DB API adapter implementation is straightforward. Both NoSQLBench and its adapters are written in the Java programming language. The current NoSQLBench release (5.17) requires Java 17, and the current development branch for the forthcoming (5.21) release requires Java 21. We implemented our adapter as a new Maven module within the NoSQLBench codebase. There are several compulsory classes to create/load an adapter and have it build and execute the operations that NoSQLBench requires. Our fork of NoSQLBench with our new XML:DB API adapter is available from https://github.com/evolvedbinary/nosqlbench. The adapter supports compulsory parameters defining how to connect to the XML database endpoint.
Naturally we intend to contribute this adapter back to NoSQLBench as soon as is practical.
Control of the Data Set and Workload
NoSQLBench makes strong claims for the efficacy of their system [NoSQLBench Introduction]:
NoSQLBench provides tight control of the data set and workload in a number of ways:
You can run common testing workloads directly from the command line. You can start doing this within 5 minutes of reading this.
You can generate virtual data sets of arbitrary size, with deterministic data and statistically shaped values.
You can design custom workloads that emulate your application, contained in a single file, based on statement templates - no IDE or coding required.
These features are provided by the core of NoSQLBench. What is missing is a way to
efficiently provide
a large XML data workload. Of course it is easy to update the database through
queries using the XML:DB adapter,
but the overhead of the interface makes this piecemeal mechanism very inefficient.
What is needed is a way to bulk generate XML data which can be stored in a file and uploaded into the target database through whatever file ingestion mechanism it provides. We observed that the NoSQLBench Virtual Data Sets (VDS) effectively do this for the runtime of a benchmark, and we decided to build a tool using VDS that generates XML at compile time. This is the second and final artifact we created to adapt NoSQLBench for XML.
A Standalone XML Generation Tool using VDS
Recall that the NoSQLBench framework is written in Java. In fact, the VDS services within it were once a standalone package of their own, and while they have been rolled into the greater NoSQLBench, they still present a clean, general, and very powerful functional library for efficient data generation.
It turns out to be very easy, then, to use VDS as a Java library directly and to supplement that with support (and syntactic sugar) simplifying the generation of XML output. Thus while defining XML workloads in this system involves, in both principle and practice, writing programs for XML generation rather than scripts, the programs are usually extremely simple and formulaic.
We have implemented such a Java tool which uses the VDS libraries and generates XML elements, attributes and text. Using the tool we have implemented XML generation of a database modelled on the XMark auction site. Our tool could be re-integrated into NoSQLBench as a step in a workload scenario, however it does not take the same form as an adapter (as defined by NoSQLBench). In the section: section “A Comparison of XMark xmlgen and xmlgen2 Auction Data”, we compare the results of this method of XML generation with the original XMark xmlgen.
Metric collection and extraction
NoSQLBench automatically measures and extracts timing of distinct operations run within a benchmark. Means and distributions of per-operation performance are then reported via whichever mechanisms are configured; the simplest is a log file. That is more than adequate for our needs, but the growing requirement for feeding continuous statistics into control panel dashboards can also be accommodated.
Figure 1: NoSQLBench XML Database testbed architecture
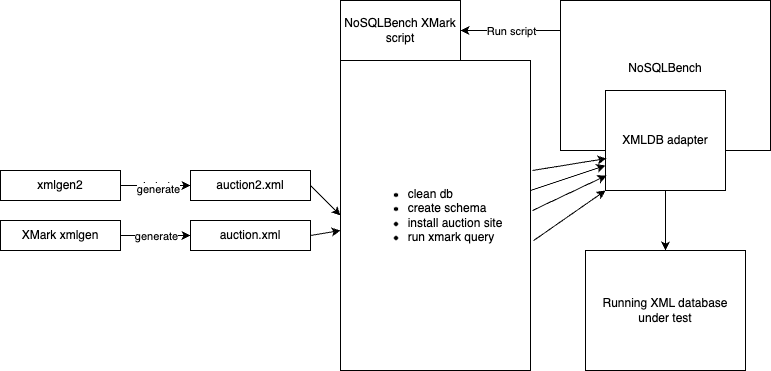
Running XMark in the Testbed
Having built an XML:DB adapter and an XML generation tool, we can construct a NoSQLBench script
to run XMark benchmark queries. NoSQLBench scripts are written in YAML, and are structured
at the top level as a number of scenarios. Our scenarios are:
-
A scenario for clearing the database and reloading XML data from the (previously generated) auction database file.
-
A scenario for running each individual XMark benchmark; most are structured in the same way:
Most of the XMark benchmark scenarios run the query multiple times serially in a single thread, because the nature of the XMark benchmark query demands this mode of operation. It is entirely possible, and a core feature of NoSQLBench, to configure a scenario to run multiple threads and to distribute more than one operation over these threads. We have tested this model with a very simple XQuery operation to demonstrate the simulation of a database servicing multiple requests from multiple clients. Clearly the potential exists to benchmark realistic queries in relevant concurrent contexts.-
Run a
warmupphase which performs the single XQueryoperationof the benchmark several times to stabilise any startup effects of the database. -
Run a
readphase which performs the XQueryoperationof the benchmark multiple times to generate a statistically useful distribution of results. The different benchmark query scenarios are run a fixed number of times which depends on how long-running each individual query is.
-
As an example, here is the scenario for XMark benchmark 3:
Return the first and current increases of all open
auctions whose current increase is at least twice as
high as the initial increase.
xmark003:
# Single threaded
warmup: run driver=elemental tags==block:"xmark003.*",
cycles===TEMPLATE(warmup-cycles,5)
threads=1 errors=timer,warn
endpoint=xmldb://localhost:3808
read: run driver=elemental tags==block:"xmark003.*",
cycles===TEMPLATE(read-cycles,10)
threads=1 errors=timer,warn
endpoint=xmldb://localhost:3808
and here is the single XMark benchmark 3 operation,
xmark003:
ops:
query:
xquery version "3.1"
for $b in /site/open_auctions/open_auction
where $b/bidder[1]/increase/text() * 2 <= $b/bidder[last()]/increase/text()
return <increase
first="{$b/bidder[1]/increase/text()}"
last="{$b/bidder[last()]/increase/text()}" />
NoSQLBench is invoked as a command to run a series of scenarios:
java -jar ./nb5/target/nb5.jar ./adapter-existdb/target/classes/activities/xmldb_xmark.yaml
reset xmark003 auctionfile="auction-xmlgen2-f10.xml"
This runs the scenarios reset and xmark003 in order, and has set the (script defined) auctionfile
parameter as the name of the XML database file to install (part of the reset scenario).
Metrics from the run can, by default, be found in NoSQLBench log files. The default
result_success
metric from the read activity is what we need to tell us how the benchmark has performed:
{activity="read",container="xmark003",instance="default",jobname="nosqlbench",
name="result_success",
node="192.168.68.62",
scenario="xmark003",session="o2988XR",workload="xmldb_xmark"}
count = 10
mean rate = 0.00 calls/nanosecond
1-minute rate = 0.00 calls/nanosecond
5-minute rate = 0.00 calls/nanosecond
15-minute rate = 0.00 calls/nanosecond
min = 10779885568.00 nanoseconds
max = 12788957183.00 nanoseconds
mean = 11526261964.80 nanoseconds
stddev = 587242416.24 nanoseconds
median = 11340349439.00 nanoseconds
75% <= 11827937279.00 nanoseconds
95% <= 12788957183.00 nanoseconds
98% <= 12788957183.00 nanoseconds
99% <= 12788957183.00 nanoseconds
99.9% <= 12788957183.00 nanoseconds
A Comparison of XMark xmlgen and xmlgen2 Auction Data
In order to demonstrate that our new XML generation library is arguably adequate,
along with the XML:DB adapter, as an XML benchmark system
we have chosen to appeal to the the XMark benchmark. First we present the results
of
running a selection of XMark benchmarks using auction sites generated both by the
original
XMark xmlgen and by our new xmlgen2. Time pressure has prevented
us completing running all the benchmarks, but we have tried to select a broad illustrative
sample. Then, we discuss the results.
The XQuery for each of these benchmarks is in the test YAML script which is avaliable from: https://github.com/evolvedbinary/nosqlbench/blob/exist-driver/adapter-existdb/src/main/resources/activities/xmldb_xmark.yaml.
Table I
XMark Performance
| Query | XMark xmlgen | SD | xmlgen2 (VDS) | SD |
|---|---|---|---|---|
| Q2 | 4.18s | 0.057s | 4.42s | 0.19s |
| Q3 | 1.35s | 0.15s | 1.14s | 0.20s |
| Q3 (modified) | 1.35s | 0.15s | 1.36s | 0.065s |
| Q8 (10MB DB) | 12.6s | 0.083s | 13.3s | 0.093s |
| Q8 (reformulated) | 6.79s | 0.07s | 7.78s | 0.12s |
| Q9 (reformulated) | 6.93s | 0.085s | 6.95s | 0.17s |
| Q14 | 1.19s | 0.07s | 1.22s | 0.05s |
| Q15 | 2.538s | 0.05s | 2.875s | 0.05s |
| Q16 (1GB DB) | 1.73s | 0.10s | 1.96s | 0.07s |
| Q17 (1GB DB) | 1.163s | 0.127s | 0.851s | 0.52s |
| Q17 (1GB DB, fixed) | 1.163s | 0.127s | 1.240s | 0.143s |
Looking at the table, we can see that most benchmarks result in a very slightly slower
runtime for xmlgen2
compared to that for XMark xmlgen.
We speculate that the consistently slightly larger database, which is due to
the VDS mechanism we use to generate text yielding larger paragraphs,
is the uniform reason for this. Even so, the differences are never more than 5%-10%.
We consider in more detail the queries that differ most significantly:
Query 3
Return the first and current increases of all open auctions whose current increase is at least twice as high as the initial increase.
The xmlgen2 numbers were surprisingly better.
A variation in the distribution of the bid values means that
xmlgen2 database yields only 1862 matching result elements,
while XMark xmlgen yields 3048 elements.
When we control for this in xmlgen2 by adjusting the query
to return an element if the final bid is at least 1.4 times greater,
the query yields 3072 elements and the run time is almost identical
to that of XMark xmlgen.
Query 8
List the names of persons and the number of items they bought. (joins person, closed auction)
We were only able to use the 10MB database for this query; the query was too slow to measure reliably on the 100MB database. This reflects a known issue in eXist-db which will be addressed in Elemental in the near future.
By manually rewriting the where clauses to predicates we were
able to re-formulate the same query in order to utilise the defined indices.
Then the query could easily
be executed against the full 100MB database.
The results for this run in an acceptable time.
Query 9
List the names of persons and the names of the items they bought in Europe. (joins person, closed auction, item)
This query again had to be reformulated, in the same way as Query 8 was. Particularly reassuring was the observation that the number of result elements returned by the query was:
-
2497 for
xmlgen2 -
2568 for
XMark xmlgen
XMark xmlgen.
Query 14
Return the names of all items whose description
contains the word gold
.
We use white
instead of gold
as the query
for xmlgen2 as it occurs with a close
count (1619) to the number of occurrences of gold
(1689) in
the XMark xmlgen database.
Query 15
For only closed auctions, print the keywords in emphasis in annotations.
There are fewer results in the xmlgen2 database
(1440 vs 1890),
but the performance is slightly lower, possibly
due to the greater raw size of the text fields generated by xmlgen2.
Query 17
Return the person records with an empty homepage.
This returns a very large result set, and the cost of sending the result set over the wire to the database dwarfs the cost of the query. We could improve our adapter implementation to reduce this effect, but the easy solution is to run a query which simply counts the result set. This is the version we provide a result for.
Interestingly, on first running this query we saw a significantly quicker
result for xmlgen2 (0.851s). On
investigation we noted that our
generator was unconditionally creating <homepage> elements within
<person> records,
rather than conditionally creating them with a 50% probability, as in the original
XMark xmlgen.
We quickly remedied this in xmlgen2,
and on re-running this query benchmark we found the reported
results. This is reassuring. The benchmark queries have allowed us to identify a mismatch
between XMark xmlgen and our new xmlgen2.
Conclusions and Future Work
First of all, we have validated that our new xmlgen2 (VDS) generator
can generate an auction site sufficiently similar to XMark xmlgen
that the same set of queries execute correctly.
Second, we are able to run performance tests against both versions of the auction database, in a range of sizes, and get repeatable results. Our NoSQLBench driver extension is responsible for this.
Third, our results show that the selection of XMark queries we have tested
behave consistently across auction databases generated by XMark xmlgen
and xmlgen2 (VDS). While results are not identical, they are close enough
to show that our system is generating a sufficiently similar auction database,
and we have been able to identify and repair flaws in xmlgen2 on the basis
of discrepancies in the performance of the XMark benchmarks.
This all means that moving forward, someone who wishes to benchmark their XML Database
can confidently adopt our NoSQLBench adapter and xmlgen2 to easily run
XMark benchmarks. If they have maintained XMark benchmarks with the original
XMark xmlgen they can carry out a one-off comparison of their benchmark
results with both systems, and then confidently adopt xmlgen2 and NoSQLBench
as a modern testbed with which to build a continuous performance regression test setup.
Future Work
-
Integrate
xmlgen2generation directly into NoSQLBench. We have tested using a number of variations of the XMark auction database which we have pre-generated at various sizes, and re-generated when we discovered flaws in the generator. An additional NoSQLBench adapter to directly call the generator would remove a manual step from our testing, and take us close to a 1-step testing invocation. The more advanced version of this would generalise from just using the auction site generator, to anytop level
generator class built upon thexmlgen2libraries. -
Make the
xmlgen2generator concurrent. At present the generator is resolutely single-threaded, as the internal architecture contains a single central XML context state managing the tree of XML being generated. A re-architecture to reduce or remove this dependency, and to introduce threading, would allow far better exploitation of modern multi-core systems. This would realistically make the (re)generation of test XML data interactively fast, and better support 1-step invocation. -
We are considering using
xmlgen2to generate simulated and anonymous test data which has the performance characteristics of important customer data. With this we can further enhance test suites which ensure and maintain that databases we are developing perform well for real world customers. -
We intend to submit our new NoSQLBench adapter(s) to the NoSQLBench project for their inclusion.
References
[Difallah 2013]
Difallah, Djellel Eddine and Pavlo, Andrew and Curino, Carlo and Cudre-Mauroux, Philippe.
Oltp-bench: An extensible testbed for benchmarking relational databases,
Proceedings of the VLDB Endowment, Volume 7, Number 4, Pages 277-288, 2013, VLDB Endowment. doi:https://doi.org/10.14778/2732240.2732246
[Shook 2020] Shook, Jonathan. NoSQLBench - An open source, pluggable, NoSQL benchmarking suite. https://www.datastax.com/blog/nosqlbench
[Paxton 2024]
Paxton, Alan and Retter, Adam.
Modern Benchmarking of XQuery and XML Databases,
XML Prague 2024, Conference Proceedings, Pages 211-239.
[Schmidt 2002]
Schmidt, Albrecht and Waas, Florian and Kersten, Martin and Carey, Michael J and Manolescu,
Ioana and Busse, Ralph.
XMark: A benchmark for XML data management,
VLDB'02: Proceedings of the 28th International Conference on Very Large Databases, Pages 974-985, 2002, Elsevier. doi:https://doi.org/10.1016/B978-155860869-6/50096-2
[NoSQLBench] NoSQLBench [online]. http://web.archive.org/web/20080207010024/https://docs.nosqlbench.io/ (Accessed: 2024-June-05)
[NoSQLBench Introduction] NoSQLBench Introduction [online]. http://web.archive.org/web/20080207010024/https://docs.nosqlbench.io/introduction (Accessed: 2024-June-05)
[DataStax 2020] NoSQLBench (DataStax Blog) [online]. https://www.datastax.com/blog/nosqlbench
[XML:DB] XML:DB Initiative for XML Databases. https://github.com/xmldb-org/xmldb-api (Accessed: 2024-June-05)
[Saxon Processor] Saxonica. https://www.saxonica.com/technology/technology.xml
[Elemental] Elemental. https://elemental.xyz/
[FusionDB] FusionDB. https://fusiondb.com/
[eXist-db] The eXist-db Open Source Native XML Database. https://exist-db.org/exist/apps/homepage/index.html
[XQuery 3.1] Robie, Jonathan and Dyck, Michael and Spiegel, Josh. XQuery 3.1: An XML Query Language. https://www.w3.org/TR/xquery-31/
[Lu 2005]
Lu, Hongjun and Yu, Jeffrey Xu and Wang, Guoren and Zheng, Shihui and Jiang, Haifeng
and Yu, Ge and Zhou, Aoying.
What makes the differences: benchmarking XML database implementations,
ACM Transactions on Internet Technology (TOIT), Volume 5, Number 1, Pages 154-194, 2005, ACM New York, NY, USA. doi:https://doi.org/10.1145/1052934.1052940
[YCSB10]
Cooper, Brian F and Silberstein, Adam and Tam, Erwin and Ramakrishnan, Raghu and Sears,
Russell.
Benchmarking cloud serving systems with YCSB,
Proceedings of the 1st ACM symposium on Cloud computing, Pages 143-154, 2010. doi:https://doi.org/10.1145/1807128.1807152
[Mlýnková 2008] Mlýnková, Irena. XML benchmarking: Limitations and opportunities. Technical Report, Department of Software Engineering, Charles University, 2008.
[XML:DB] XML:DB Initiative for XML Databases. https://github.com/xmldb-org/xmldb-api
[BaseX] BaseX The XML Framework. https://basex.org/