Introduction
Problem domain
XML-encoding a textual corpus is typically achieved through manual tagging, i.e. by human operators using a text editor or specialized annotation software, or through the application of algorithms that complete the tagging on the basis of a known schema.
The problem we address in this paper is to provide an algorithmic substrate, made accessible through an Application Programming Interface (API), to achieve automated tagging [Renders2007a, Renders2009a, Briquet2009a] of the digitized version of one of the most complex paper dictionaries. This dictionary is the Französisches Etymologisches Wörterbuch (FEW) [ProjectFEW, Wartburg1922a]. The FEW is the historical and etymological dictionary of the languages of the gallo-roman area (i.e. French, Franco-Provençal, Occitan and Gascon in all of their diatopic variations), written over the course of more than eighty years.
Each article of the FEW describes all derived words (i.e. lexemes) of a given root word (i.e. etymon) [Buchi1996a], instead of (as happens in most etymological dictionaries) describing the root word of a given derived word. Of course, several fields of information are offered for each article, such as the etymon and the language in which this etymon originates, the signature of the article, footnotes. The structure of the article is emphasized through hierarchical numbering and labeling of groups of paragraphs and cross-references to these. Several fields of information are offered for each lexeme, including but not limited to geolinguistic labels, bibliographical references to attestations of the lexeme and the definition of the lexeme. All of these types of information are well-delineated, thus good candidates for tagging. In a nutshell, each article of the FEW is a highly structured text that can be described through a model [Buchi1996a] and thus algorithmically processed.
Besides these semantic types of information that are expected to be identified through automated tagging, formatting markup (such as paragraph, bold, italic, exponent, break tags such as end of line or end of column,...) is also available in each article following the digitization process (the formatting markup is added either manually or through OCR). This enables an on-screen visualization of articles that is faithful to the paper version of the dictionary. The availability of paragraph tags is important not only to properly format the articles, but to make accessible a first level of structuring of the article. Likewise, the availability of break tags enables to correctly tag some types of semantic types of information. Many hyphens indeed do not indicate that a long word is being cut at the end of the line where they are found, but instead convey semantic information (e.g. as part of affixes). And there is no straightforward way to automatically disambiguate the syntactic uses from the semantic uses of hyphens at the end of lines in the FEW dictionary.
To put the FEW dictionary [ProjectFEW, Wartburg1922a] in perspective, here is a quick comparison with another complex dictionary, the well-known Oxford English Dictionary (OED) [OED]. Whereas the markup used to encode OED articles is proprietary SGML [OED], the markup used to encode FEW articles is standard XML complying with an XML Schema [Briquet2009a]. The FEW markup is referred to as FFML (FEW Font-style Markup Language) for files input to the automated tagging process. It is referred to as FSML (FEW Semantic Markup Language) for files output by the automated tagging process. FSML is comprised of mostly a superset of FFML, that is augmented with semantic markup. There currently exists no in-depth comparison of the scopes of the OED and FEW markups, and it is clear that there are differences if only because FEW entries are etymons instead of, typically, lexemes. Nonetheless, in very general terms, both markups are intended to encode dictionary articles and it is not surprising to see many common features. The FEW dictionary, though, is considered to be one of the most complex dictionaries in the world [Buchi1996a], notably because of the ever-present implicitness of many types of information. The Table here below provides a shallow quantitative comparison of both dictionaries.
Table I
Shallow quantitative comparison of OED [OED] and FEW [Buchi1996a]
| Feature | OED | FEW | Comment |
|---|---|---|---|
| Pages | 21730 | 16865 | |
| Volumes | 20 | 25 | |
| Entries | 300000 | 20000 | FEW entries are etymons, not lexemes, thus fewer |
| Lexemes | 600000 | 900000 (*) | (*) back-of-the-envelop estimate |
Importance of the problem
Semantically tagging the articles of the FEW is a multi-year linguistics research project [Renders2007a] that is tremendously important to the historical linguistics community. Merely digitizing the FEW, without further processing would only enable full text search. Tagging the various fields of information would also enable so-called lateral search over the whole dictionary. Semantic tagging would disambiguate and resolve the implicitness of most of the fields of information contained in the dictionary.
Given the extreme linguistic complexity of the FEW, only highly-trained human experts could theoretically do the job. But there are not enough of them to process the twenty thousand articles of the FEW and this would be a tedious, error-prone job anyway. It was thus decided to use algorithmic automation to tag the fields of information of the FEW [Renders2009a]. Even though the articles of the FEW (implicitly) constitute a highly specialized textual corpus, we believe that the problem can be sufficiently abstracted so that our proposed approach is also relevant to other endeavors, particularly the processing of text-oriented XML documents (i.e. text with intersparsed markup) such as text corpora.
Scope of the problem
The input of our project is comprised of XML documents, each of which represents an article of the FEW and includes basic layout tags (article, paragraphs, bold, italic,...) that were added by human encoders and/or by OCR software. Obviously, all textual contents are eventually enclosed in paragraph and article tags. Nonetheless, the element hierarchy is often not the prime model of choice when accessing the FEW. Identifying fields of information in the FEW indeed focuses on linear regions of text where elements can be nested in many ways. Thus a very important property is that an FEW article should be considered as a text-oriented XML document, i.e. a text with intersparsed tags rather than a tree of elements with some textual contents found in the leaves.
The objective of our project is ultimately to add semantic markup around fields of information within a text-oriented XML document (fields of information of interest are listed in the Problem domain section here above). This requires to first identify these fields of information, then accordingly update the XML document.
Each article of the FEW dictionary typically features multiple occurrences of 25 or so types of information [Buchi1996a], each of which is detected and tagged by a specific tagging algorithm (see Figure 1 here below).
few-tagging-sequence
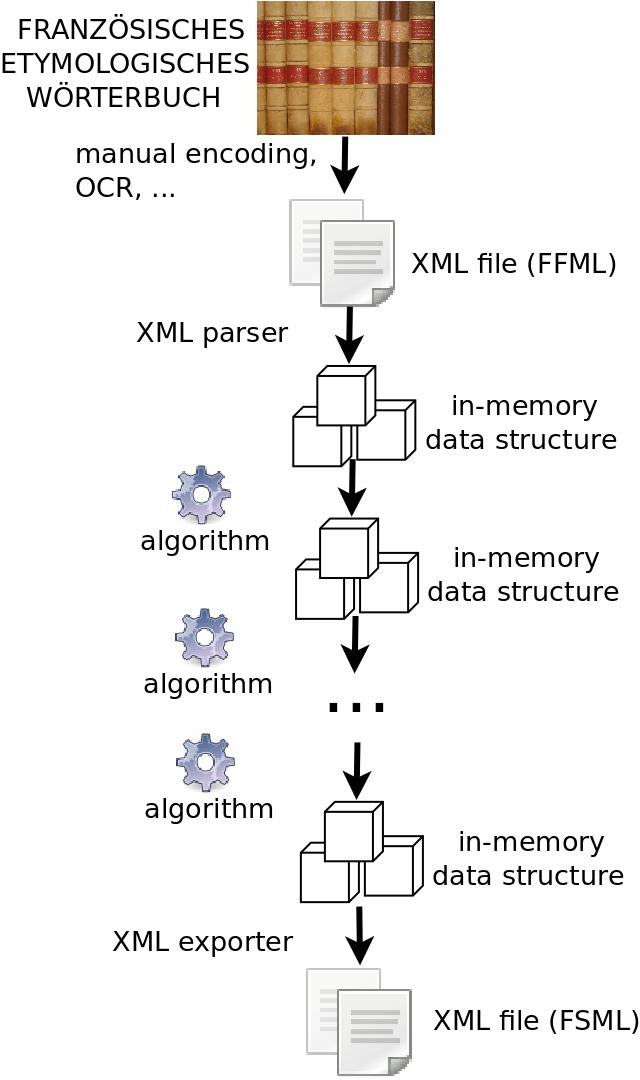
FEW tagging sequence
As the dependency graph of tagging algorithms is acyclic, it is possible - though not straightforward - to determine the sequence in which they should be applied (the so-called retroconversion sequence, e.g. tag definitions, then geolinguistic labels, then bibliographic labels,...) [Renders2009a, Briquet2009a]. An important property is that the order in which tags are inserted into the XML document representing an FEW article is known. Therefore, when designing a tagging algorithm, one knows which types of information have previously been tagged - and thus which ones might interfere with information retrieval and updates.
Identification of fields of information in an FEW article by a tagging algorithm is typically based on several retrieval primitives: keyword search, matching of regular expressions (regexp), as well as matching of contextual tag sequences. Most algorithms rely on a combination of several of these primitives, often in non-straightforward ways that involve secondary lookups in the contexts surrounding initial matches. The linguistic challenge resides in handcrafting combinations of retrieval primitives that lead to accurate identification of types of informations. As the design and implementation of tagging algorithms is beyond the scope of this paper, we now concentrate on issues that arise from the stated information retrieval requirements.
Among the issues that make information retrieval in the FEW quite challenging, two classes of issues stand out:
-
Firstly, some keyword search may be relevant only in some selected contexts, i.e. would lead to false positives if applied to irrelevant contexts.
-
Secondly, the presence of some tags, e.g. such as exponent or end of line tags, within words or groups of words may prevent the matching of keywords and regular expressions, thus leading to false negatives.
Update of (the XML document representing) an FEW article by a tagging algorithm typically includes the insertion, removal, displacement or update of text, as well as the insertion, displacement or removal of tags. The possible presence of many types of tags within updated text regions increases the complexity of update operations, as these should preserve the well-formedness of the XML document. Moreover, the tagging of a text region might be decided based on the identification of patterns in a neighboring text region. Support for match points is thus very important, as the locus of where to insert a tag is most often decided based on offsets in the textual representation of the XML document (these offsets being sometimes far away from the XML node whose contents were matched in the identification phase), not relative to tags of the XML document.
In addition to these retrieval and update challenges, one must keep in mind that the semantic tagging of FEW is a research project [Renders2007a] whose object of study is a very complex dictionary. Concretely, another layer added to these challenges resides in the lack of knowledge of where tags can appear in the text. Even though it might be known that a given tag type is always included in a specific parent element, this provides no information on where the given tag appears among the textual content of its englobing element. This is the kind of challenge one must face when searching both markup and textual contents at the same time [StLaurent2001a].
This leads to the following additional requirement: A mechanism must be provided to flexibly and easily configure the contexts where retrieval and update operations will be applied. This is a challenging requirement, as we desire to provide users of the mechanism a way to think of the dictionary and express themselves in a familiar environment: text without tags.
What is required is thus a mechanism that enables flexible, dynamic, tag-aware retrieval and update in a text-oriented XML document, in order to support natural linguistic reasoning. Based on our review of the state of the art presented in the section of this paper discussing related works (see below), we are not aware of any existing XML technology that addresses all of these requirements, specifically the provision of a familiar environment to users of the mechanism.
Our Approach
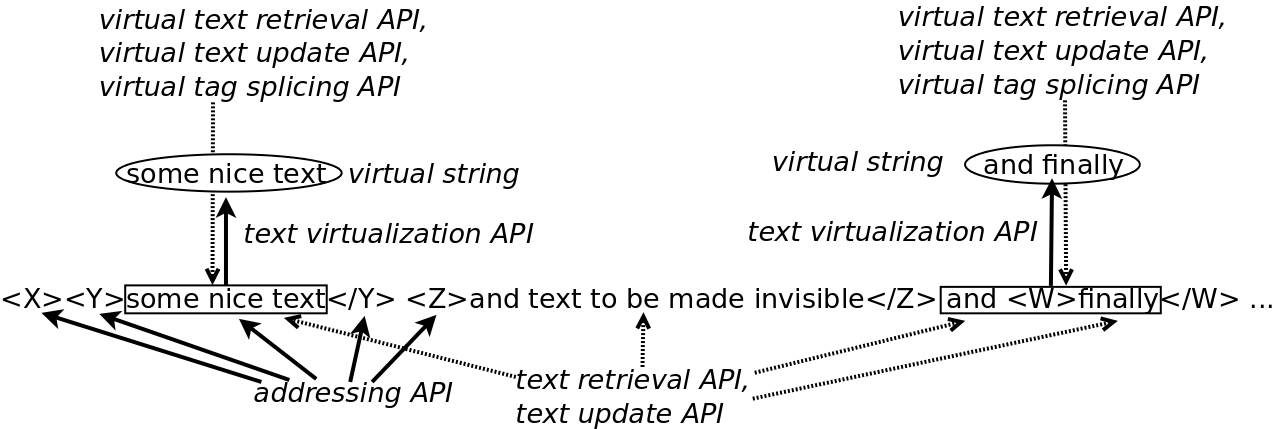
The key principle of our approach to the tag-aware retrieval and update problem is the virtualization of the text-oriented XML document. We propose a mechanism to allow one to easily construct, through an Application Programming Interface (API), a representation of selected sections of the XML document from which types of tags leading to ambiguities - as well as their contents, if required - have been removed. In practice, sections of the XML document are virtualized into multiple virtual strings, separated by so-called visible tags, according to dynamically-defined tag visibility rules. A definition of the virtual string data structure is provided in a further section; intuitively, a virtual string is the concatenation of adjacent text chunks, except those within elements that are configured to not be added to the virtual string.
For example, this section of XML document: <X><Y>some nice text</Y> <Z>and text to be made invisible</Z> and <W>finally</W> <Y>nice
text again</Y></X> is virtualized into these three virtual strings: (1) some nice text, (2) and finally and (3) nice text again, if using the following configuration: <X> and <Y> tags should stop the virtualization mechanism, <Z> tags as well as their contents (if considered as elements) should be made invisible,
and <W> tags (not their contents, if considered as elements) should be made invisible.
How do API users benefit from the virtualization? With ambiguity abstracted away through an appropriate configuration of what tags should be made invisible (with or without their contents, if considered as elements), the representation of the XML document as a sequence of virtual strings is more easily searchable, simplifying retrieval (keyword search, regexp matching, contextual tag sequence matching).
Importantly, each virtual string is backed by the underlying XML document. Updates to a virtual string are thus transparently propagated to the document. Therefore, this constructed representation is also easily updatable.
Our approach shares the intent of the Regular Fragmentations mechanism proposed by Simon St.Laurent [StLaurent2001a, RegFrag] and of the XML Fragments mechanism introduced by Carmel et al. [Carmel2003a], to the extent that we wish to devise a transparent mechanism that enables mixed-information (text/markup) retrieval in a text-oriented XML document. Our proposed virtualization mechanism may be viewed as a dynamic, more flexible and - importantly - updatable version of the Reading Context mechanism introduced by Xavier Tannier [Tannier2005a]. Mixed-information (text/markup) retrieval is provided by our proposed virtualization mechanism through the backing of virtual strings by the underlying XML document. The tag visibility model on which our proposed virtualization mechanism relies is an extended version (with slightly different semantics) of the tag visibility model initially introduced by Lini et al. [Lini2001a] and used by Tannier [Tannier2005a]. Our proposed API is comprised of exactly the operations that are required to digitize the FEW dictionary [ProjectFEW, Wartburg1922a], no more, no less. Nonetheless, we believe it is sufficiently general and extensible to be useful to other text-oriented XML document processing needs.
The rest of this paper is structured as follows. Typical use cases are first described in order to ground our work into real, concrete, albeit basic examples. Hypothetical use cases are also provided, in order to situate our work within a broader context. The proposed XML document retrieval and update API is then introduced. Related works are subsequently reviewed and their relationships with our work are explored. Finally, concluding remarks put the proposed API into perspective.
Typical Use Cases
Four typical use cases gathered here below illustrate how our proposed API can help design tagging algorithms [Renders2009a]. The use cases highlight two major classes of information retrieval issues encountered in semantically tagging the FEW dictionary (false positives, false negatives).
Use case 1: avoidance of false positives for regular expression matching
In this use case, the objective is to tag dates. To search for dates, a regular expression is applied to the full text version of the XML document.
Input (FEW 2, 982b, completus):
<geoling>Nfr.</geoling> <i>com-<lb merge="no"/> plètement</i> <def>„action de mettre au complet“</def> (seit 1750,<lb merge="no"/> text in <biblio>Fér 1787</biblio>).
Expected output, one <date> tag inserted:
<geoling>Nfr.</geoling> <i>com-<lb merge="no"/> plètement</i> <def>„action de mettre au complet“</def> (seit <date>1750</date>,<lb merge="no"/> text in <biblio>Fér 1787</biblio>).
If all tags were removed prior to full text search, the string 1787
would be matched as a licit date. This would lead to a false positive as it has already
been tagged as part of a bibliographical reference.
Instead, <biblio> tags (as well as others, in practice) should be made totally invisible, their contents
included, prior to full text search. The full text to which the search operation is
applied thus becomes:
Nfr. complètement „action de mettre au complet“ (seit 1750, text in ).
Use case 2: avoidance of false positives for keyword search
In this use case, the objective is to tag grammatical categories. To search for grammatical
categories, a keyword search is applied to the full text version of the XML document.
In practice, the string f.
belongs to the keyword list of grammatical categories (it's an abbreviation standing
for: feminine substantive).
Input (FEW 2, 983a, completus):
<geoling>Nfr.</geoling> <i>fleur incomplète</i> <def>„f. dé-<lb merge="discard-hyphen"/> pourvue de quelque organe, notamment de corolle“</def><lb merge="no"/> (seit <biblio>Trév 1771</biblio>).
Expected output, no tag inserted:
<geoling>Nfr.</geoling> <i>fleur incomplète</i> <def>„f. dé-<lb merge="discard-hyphen"/> pourvue de quelque organe, notamment de corolle“</def><lb merge="no"/> (seit <biblio>Trév 1771</biblio>).
If all tags were removed prior to full text search, the string f.
would be matched as a licit grammatical category. This would lead to a false positive
as f.
is here an abbreviation of the word fleur
(i.e. flower) and has already been tagged as part of the definition of a lexeme.
Instead, <def> tags (as well as others, in practice and for the relevant algorithm) should be made
totally invisible, their contents included, prior to full text search. The full text
to which the search operation is applied thus becomes:
Nfr. fleur incomplète (seit Trév 1771).
Use case 3: avoidance of false negatives for regular expression matching
In this use case, the objective is to tag dates. To search for dates, a regular expression
is applied to the full text version of the XML document.
The –
character is not a hyphen, but an en dash. This character, as well as the spacing around it, is accounted for in the
regular expression used to match dates.
Input (FEW 25, 882a, augmentator):
<p>Emprunt de <geoling>lttard.</geoling> <geoling>mlt.</geoling> <i><etymon>augmentator</etymon></i> (4<e>e</e>–<lb merge="no"/> 6<e>e</e> s., <biblio>ThesLL</biblio> ;
Expected output, one <date> tag inserted:
<p>Emprunt de <geoling>lttard.</geoling> <geoling>mlt.</geoling> <i><etymon>augmentator</etymon></i> (<date>4<e>e</e>–<lb merge="no"/> 6<e>e</e> s.</date>, <biblio>ThesLL</biblio> ;
If <e> and <lb/> tags were not skipped, the date range 4e-6e s.
(i.e. 4th-6th century) would be split into six fragments. This would lead to a false
negative, i.e. the date would not be matched. By virtually removing the <e> and <lb/>
tags (as well as others, in practice), the date can be matched by a regular expression.
The full text to which the search operation is applied thus becomes:
Emprunt de lttard. mlt. augmentator (4e– 6e s., ThesLL ;
Use case 4: avoidance of false negatives for keyword search
In this use case, the objective is to tag affixes (i.e. prefixes and suffixes). To search for affixes, a keyword search is applied to the full text version of the XML document.
Input (FEW 8, 237a, perfectus):
<pref id="I 2 a">a</pref> mit dem suffix -<i>ivus</i>
Expected output, one <affix> tag inserted:
<pref id="I 2 a">a</pref> mit dem suffix <affix>-<i>ivus</i></affix>
If <i> tags were not skipped, the hyphen of the suffix -ivus
would be separated from the rest of the word. This would lead to a false negative,
i.e. the affix would not be matched. By virtually removing the <i> tags (as well as
others, in practice), the affix keyword can be matched.
The full text to which the search operation is applied thus becomes:
a mit dem suffix -ivus
Hypothetical Use Cases
In a general sense, our proposed virtualization mechanism enables to construct views of an XML document, dynamically at any time during its processing. The mechanism masks selected parts of an XML document and transparently applies updates - through the constructed document view - to the XML document. The mechanism operates on a representation of the XML document that does not rely on a DOM tree. The representation of the XML document exhibits very lightweight storage requirements if one desires to process only sections of the document at a time. Therefore, our proposed virtualization mechanism is well-suited to process streamed data.
An hypothetical use case of growing importance would be the semantic analysis of web documents intended to feed the ever-expanding index of a web search engine. Given that web search is predicted to evolve towards a better understanding of what web documents mean [Savage2010a], semantic analysis of a web document may well evolve to become a key problem in web search. The ability to easily mask selected tagged regions of a web document to try and derive different meanings would thus be an asset when engineering its semantic analysis.
Document Retrieval and Update API
As most algorithms devised for the semantic tagging of types of information of the FEW dictionary operate based on different contextual assumptions, one should be able to flexibly and easily configure the retrieval and update operations for each algorithm. Why did we choose to expose this mechanism through an Application Programming Interface (API)? Firstly, tools that can apply only one transformation to an XML document, however powerful they are [StLaurent2001a, RegFrag, Tannier2005a, Tannier2006a, Tannier2006b], are not adapted because the semantic tagging of FEW requires each XML document to be processed multiple times. Secondly, domain-specific languages can serve their purposes well, but often lack in generality. Thirdly, embeddable domain-specific languages, like XQuery [XQuery] is intended to be, deserve attention but the depth of integration may (currently) sometimes be a limiting factor. Fourthly, an Application Programming Interface (API) offers great flexibility and by design can be easily integrated with user code. We have thus decided to expose our proposed virtualization mechanism through an Application Programming Interface (API). A Java implementation of this API was completed during the summer of 2009.
Our proposed document retrieval and update API is actually comprised of a set of six distinct APIs (see Figure 2 here below, based on the example illustrating the Our Approach section):
-
addressing API: provides a mechanism to locate target nodes;
-
text retrieval API: no specific document-level or node-level text retrieval API is provided, user code is expected to rely on standard Java facilities or user-provided custom packages;
-
text update API: provides a mechanism to update a single text node and insert tags into a single text node;
-
text virtualization API: provides a mechanism to construct a sequence of virtual strings over a section of the XML document potentially spanning many nodes, from which specified types of tags are virtually removed;
-
virtual text retrieval API: provides a mechanism to retrieve data within a virtual string, that also provides access to the underlying nodes of the XML document;
-
virtual text update API and virtual tag splicing API: provides a mechanism to update a virtual string and insert tag into a virtual string, and have the updates transparently propagated to the underlying nodes of the XML document.
retrieval-update-api
Document Retrieval and Update API
Before introducing each API, the in-memory representation of XML document on which they operate is first described.
In-memory Document Data Structure
An important design decision in XML document processing is the in-memory representation of its markup and content. A typical choice is the DOM tree representation [DOM]. However, as we are considering text-oriented XML documents only, there are at least two arguments against a tree representation.
-
Firstly, the structural information contained in the tree branches is practically useless to our purposes as the element hierarchy of the FEW dictionary is not always predictable (see Scope of the problem here above for the rationale). Therefore, the memory footprint of the document representation can be greatly reduced by discarding hierarchical relationships and storing only the list of leaves of the document.
-
Secondly, as the generated XML documents may not be well-formed (due to e.g. unexpected textual data that cannot be recognized by the tagging algorithms), a mechanism to deal with the lack of well-formedness, such as e.g. milestones [DeRose2004a], is required. A tree representation has thus little benefit.
We decide instead to represent an XML document as a list of nodes, with each node being either an XML tag or a text chunk. This in-memory representation matches the assumption of text-oriented XML documents. It allows straightforward access to contextual relationships (i.e. is-left-of, is-right-of) between nodes, without precluding to construct additional data structures on top of it in order to access parent/child relationships for specific sections of the document. In the rest of the paper, it will be referred to as a node list.
In practice, the node list can be easily constructed using a validating SAX parser that appends text nodes and tag nodes to the node list as they are loaded to memory. Tag attributes are not appended as nodes themselves, but instead are added as properties of tag nodes. Comments and processing instructions are currently discarded from the XML document (this is an implementation-specific limitation that can be removed through additional engineering hours).
The existing implementation of the API only considers UTF-8-encoded XML documents. Fragments of text of the XML document are normalized as they are inserted into the node list as text nodes. A character map enables the API user to configure all licit character, character entity references and numeric character references. Character sanity is enforced by checking all characters of the XML document against the character map. Character entity references and numeric character references are all resolved into one Unicode character each, possibly in a private use area. All spacing characters are converted to the space character (U+0020), then multiple spaces are compacted into one space only. Leading and trailing spaces within high-level structural tags (dictionary, article, paragraph) are removed. Break tags (e.g. end of line, end of column, end of page,...), despite being tags and not text, are also normalized, i.e. redundant break tags are removed.
Addressing API
The addressing API takes one node as input, and provides a node as output.
Addressing of XML elements, tags or text chunks, in the node list is always relative to a target node and always returns a single node (never a set of nodes). No mechanism of absolute addressing of XML elements in the XML document is currently provided because it was not a requirement for the tagging of the FEW dictionary. An absolute addressing mechanism featuring XPath [XPath] syntax might be supported but at the expense of a severe performance penalty, as the node list does not contain the hierarchical structure of a node tree (see In-memory Document Data Structure here above for the rationale).
Relative addressing of XML elements can be done in three ways: by neighbor access, by tag node search, by text node search.
-
The left and right neighbor of a target node are always immediately accessible, by construction of the node list.
-
Several tag node search operations are provided by the addressing API: search forwards/backwards for the next tag node matching a given set of tags and/or tag attributes, before the first occurrence of a stopper tag (if specified). It must be noted that forward search and backward search are not equivalent to descendant search or ancestor search [XPath] in a tree representation. Consider the following two examples. First example:
<X><Y>some text</Y><Z>some text</Z></X>. Second example:<X><Y>some text</Y></X> <Z>some text</Z>. A forward search (in our proposed node list representation), relative to the target node<X>, for a<Z>tag will find a match in both examples, whereas a similar descendant search (in a tree representation) would not find a match in the second example. -
Several text node search operations are provided by the addressing API: search forwards/backwards for the next text node, before the first occurrence of a stopper tag (if specified). Again, forward search and backward search are not equivalent to descendant search or ancestor search [XPath] in a tree representation.
Text Retrieval API
Neither a dedicated node-level retrieval API (i.e. within individual nodes only) nor a document-level text retrieval API are provided (i.e. within all individual nodes of the document, considered individually), for two reasons.
Firstly, the text chunk of a text node is a classic Java string. To achieve node-level text retrieval, it is thus straightforward for user code to rely on standard Java facilities such as the operations on Java strings (java.lang.String methods), the regular expression engine (java.util.regex package), or user-supplied packages. This also enables one to plug advanced search mechanisms such as collocate search, or search for inflected forms (e.g. mouse/mice). For instance, in the context of the FEW dictionary, several semantic tagging algorithms depend on a keyword search seeking to match a list of keywords that may each exhibit several nontrivial variations. The decoupling of node-level text retrieval operations (as well as virtual text retrieval over selected sections of the document, which constitutes the core of this paper, see below) from other core operations thus offers great flexibility to users.
Secondly, document-level retrieval can be achieved by using an additional retrieval mechanism on top of the node list representation, such as one of those discussed in the Related Work section of this article.
Text retrieval over sections of the document (i.e. of its node list representation), though, is made possible using the virtual text retrieval API (see below).
Text Update API
The text update API takes one text node and an update specification as input, and updates/inserts/deletes text nodes as output. In the existing implementation, the updates are not in-place, i.e. text nodes are actually substituted with an updated copy of themselves.
Three operations applicable to a target text chunk are provided by the node-level text update API:
-
Update (replacement) of a substring of the target text chunk with the specified string.
-
Tagging of a substring of target text chunk with a given tag, i.e. insertion of an opening and a closing tag at specified insertion indexes.
-
Insertion of a list of tags at specified insertion index of target text chunk. Typical use case: inserting an empty element.
Text Virtualization API
The text virtualization API takes one node and a virtualization specification as input, and provides a (possibly empty) sequence of virtual strings as output.
Just one operation is provided by the API: the construction of a sequence of virtual strings based on a specification of tag types visibility provided by the API user. The text virtualization API addresses the issue of virtually removing specified types of tag, as well as their contents (if specified), from a sequence of sections of a text-oriented XML document. We define a section as the sequence of nodes starting at a target node and extending immediately prior to (and excluding) the first tag node matching a specified stopper tag type (if any), or the end of the document (in the absence, after the target node, of any stopper tag matching the specified type). The construction of a sequence of virtual strings thus virtualizes a sequence of sections of the XML document.
We define a virtual string as the data structure:
-
based on a string resulting from the concatenation of adjacent text chunks (two text chunks are considered as adjacent if no visible tag occurs between them),
-
that is backed by the underlying text nodes of the XML document,
-
that includes all the information necessary for retrieval and dynamic updates (see Virtual Text Retrieval API and Virtual Text Update API in the following).
The construction of a sequence of virtual strings is controlled through the specification of a visibility partition of all types of tags that can appear in the XML document. It relies on a tag visibility model that is an extended version (with slightly different semantics) of the tag visibility model initially introduced by Lini et al. [Lini2001a] and used by Tannier [Tannier2005a].
Our tag visibility model is comprised of five classes:
-
skipped tags: should be virtually removed from the document section under consideration;
-
invisible tags: should be virtually removed, as well as all of their contents (including descendant tags), from the document section under consideration;
-
visible tags: signal the end of the document section under consideration;
-
terminal tags: signal the end of the document section under consideration, as well as of the sequence of sections under consideration; the availability of the visible tag class in addition to the terminal tag class enables to construct a sequence of virtual strings using one API call only (e.g. a visible tag could be </li> and a terminal tag could be </ul>);
-
unexpected tags: should not be found within those areas of the document section under consideration that are outside invisible tags.
A visibility partition is a partition of the set of all possible tag types that is comprised of five sets, each of which represents a visibility class. A partition is intrinsically comprehensive: all tag types must be included into exactly one visibility class each. At most four visibility classes can thus be empty. When defining a visibility partition, the API user has the option to specify explicitly only four visibility classes, with the remaining visibility class (whichever it is) implicitly considered as including all tag types not yet assigned to a visibility class. As will be illustrated through examples, this can be very handy in practice.
When invoked on a target node, the text virtualization API constructs a sequence of virtual strings, virtual string by virtual string. The text virtualization algorithm can be sketched as follows:
-
Each time a visible tag or terminal tag is encountered, a virtual string is produced and returned to the calling code (except when the visible tag is comprised between a pair of matching invisible tags, cf. below). Virtual strings keep getting produced until a terminal tag (or the end of the node list) is encountered, at which point the sequence of virtual strings is complete.
-
If an unexpected tag is encountered, an exception is raised.
-
If a skipped tag is encountered, it is skipped, as can be expected.
-
When an opening invisible tag is encountered, all[3] subsequent nodes (both text nodes and tag nodes) are skipped, until a matching closing invisible tag is encountered.
-
When a text node is encountered, its text is added to the virtual string under construction.
As an example, let us consider the following visibility partition over the tag set
{ <i>, <lb>, <s>, <t>, <u>, <v> }:
-
skipped tags = {
<s>,<lb>} -
invisible tags = {
<i>} -
visible tags = {
<v>} -
terminal tags = {
<t>} -
unexpected tags = {
<u>}
Once upon a time,), configured with the aforementioned visibility partition:
Once upon a time,<i /> there was a <s>sentence with an important</s> part,<lb merge="no" /> followed by an <i>irrelevant part</i>.<v />It was followed by<lb merge="no" /> a second sentence separated from the first by a visible tag.<lb merge="no" /> <v>A word near the end of the third sen-<lb merge="discard-hyphen" /> tence was split by a break tag.</v></t>A sequence of three virtual strings is returned to the calling code:
-
Once upon a time, there was a sentence with an important part, followed by an .
-
It was followed by a second sentence separated from the first by a visible tag.
-
A word near the end of the third sentence was split by a break tag.
</v> and </t>; indeed, empty virtual strings are never added to the returned sequence.
The construction of a sequence of virtual strings could be formalized as a generalized form of string projection [StringProjection] applied to a suitable representation of the selected sections of the XML document, based on classes of nodes of the node list. The projection alphabet would be comprised of one symbol only: text nodes that are not inside an invisible tag. The general alphabet would also include as individual symbols the nodes containing standalone tags (either opening, closing or empty) whose types match those included in the skipped, visible, terminal and unexpected tag visibility classes. The general alphabet would further include as individual symbols the sequences of nodes constituting complete elements (i.e. opening tag, matching closing tag and the sequence of nodes in-between) whose types match those included in the invisible tag visibility class.
Virtual Text Retrieval API
The virtual text retrieval API takes one virtual string and an information request as input, and provides either the text of the virtual string, a node, an offset or a stopper tag as output. Retrieval operations are independently performed by the API user on the text of the virtual string provided by the API.
The virtual text retrieval API implicitly allows tag-aware search by letting the API user perform full text search of a target virtual string. The virtual string exposes the string that was virtually constructed from a section of the XML document. This string is a normal, regular string that can be searched as any other string. In particular, the API user can apply her favorite regexp engine or pattern matching algorithm.
To obtain match points [Lini2001a] and otherwise access the nodes of the XML document backing the virtual string, all the API user needs to provide is the index of the character of interest (from 0 to N-1, if the length of the virtual string is N). Five operations are provided by the virtual text retrieval API:
-
Get the text of the virtual string.
-
Get the text node backing the character at target index in the virtual string.
-
Get the offset, i.e. start index within the virtual string, of the text node backing the character at target index in the virtual string.
-
Get the stopper tag (i.e. visible or terminal tag) delimiting (i.e. immediately following) the virtual string, if any. The stopper tag qualifier can also be obtained.
-
Check whether the character at target index in the virtual string is a virtual space or a regular character.
A virtual space is a space character found in a virtual string, that does not belong
to any node of the underlying XML document. Virtual spaces are inserted instead of
break tags. If a break tag is preceded by a hyphen and if it contains a specific attribute
(i.e. merge), the break tag can be processed differently based on the value of the attribute.
Three behaviors are defined:
-
insert a virtual space (default behavior in the absence of the specific attribute);
-
merge the word preceding the break tag and the word following the break tag, preserving the hyphen;
-
merge the word preceding the break tag and the word following the break tag, discarding the hyphen.
Virtual Text Update API and Virtual Tag Splicing API
The virtual text update API takes one virtual string and an update specification as input, and updates/inserts/deletes text nodes as output. The virtual tag splicing API takes one virtual string and a splicing specification as input, and inserts tag nodes as output.
The virtual text update API allows to modify the text of a virtual string. The virtual tag splicing API allows to splice (i.e. insert) tags into a virtual string. Both APIs allow to specify updates in a straightforward manner and have these updates transparently propagated to the underlying XML document. This may involve, in addition to the update of nodes, the insertion of nodes into the node list as well as the deletion of some of its nodes. To specify updates to a virtual string, all the API user needs to specify, besides the update description, is the index of the character (or indexes of the couple of characters) of interest (from 0 to N-1, if the length of the virtual string is N).
One operation is provided by the virtual text update API:
-
Updating a target substring of a virtual string: a couple of target indexes (i.e. start and end indexes) in the virtual string are specified, along with a replacement string. If the replacement string is shorter than the target substring, some of the rightmost backing text nodes might be completely deleted from the XML document.
Two operations are provided by the virtual tag splicing API:
-
Inserting a couple of opening and closing tags around a target substring of a virtual string, that is specified with a couple of target indexes (start and end indexes).
-
Inserting a single (opening, closing or empty) tag at a specified index into a virtual string.
Related Work
Query and Update Frameworks
Information Extraction
Information Extraction (IE) [IE] consists of extracting structured information from unstructured documents. Therefore, the semantic tagging of the FEW dictionary could theoretically be modelled as an IE problem (named entity recognition, coreference resolution, terminology extraction, relationship extraction). In practice, however, we hypothesize (but neither claim nor prove) that the quantity and complexity of the involved rules to identify fields of information in the FEW dictionary together make it intractable to use existing general-purpose IE software [GATE, IBMIE].
For instance, the General Architecture for Text Engineering (GATE) [GATE] makes it straightforward to define a large number of pattern matching and text processing rules, however with limited access to context. From our reading of the online documentation of GATE, we hypothesize that most rules for the semantic tagging of the FEW depend so much on context that they cannot be expressed within GATE.
Whether the stated hypothesis is proved or disproved, it will be very interesting to more deeply explore to what extent the semantic tagging of the FEW can be modelled as an IE problem.
Regular Fragmentations and XML Fragments
The Regular Fragmentations retrieval language and API [StLaurent2001a, RegFrag] allows full text search in XML-encoded corpora (keyword search at least, as well as regexp search). Regular Fragmentations does allow updates as it is a filter tool made available through either an XML configuration file or an API. Its internal representation is tree-based and can be modified based on an implied processing model. Matching on both markup and textual content is (currently?) not supported, which makes it unsuitable to the semantic tagging of the FEW dictionary.
The XML fragments query mechanism [Carmel2003a] allows full text search (keyword search only, no regexp search) and structural search in XML-encoded corpora. It does not allow updates. It does support tag-aware search. Queries are described as exemplar fragments of the XML document, which allows tag-aware search, albeit with limited flexibility. Lack of support for join operations is noted to be a major limitation of [the] XML fragment model, and a major restriction of most IR systems as compared to DB systems [Carmel2003a]. This remark also highlights that the major strength of our proposed API is its flexibility: Full access to the underlying XML document is provided with the retrieved results, enabling arbitrary supplementary processing of the retrieved results, as well as arbitrary updates of the underlying XML document.
Reading Contexts
The XTReSy [Lini2001a] retrieval language allows full text search in XML-encoded corpora (keyword search, probably not regexp search). XTReSY does not allow updates. XTReSY supports tag-aware search and has the capability to return match points. Interestingly, text normalization can be flexibly defined and is part of the language. The construction of the in-memory representation of XML documents in our work also features text normalization, but as opposed to XTReSY, punctuation is preserved (as it can constitute useful hints to detect types of information) and case streamlining is left to the API user (see Virtual Text Retrieval API here above). XTReSY actually introduced the concept of tag-aware search (refereed to as tag-dependent search [Lini2001a]). XTReSy also introduced a tag visibility model that is extended by our proposed model (see above). The XTReSy [Lini2001a] tag visibility model is comprised of three classes:
-
soft tags: can be mapped to skipped tags in our tag visibility model;
-
jump tags: can be mapped to invisible tags in our tag visibility model;
-
hard tags: can be mapped to visible and terminal tags in our tag visibility model.
The XGTagger [Tannier2005a] retrieval tool allows full text search in XML-encoded corpora (keyword search, as well as regexp search). XGTagger supports tag-aware search but cannot return match points. XGTagger does not allow updates. Instead, an external tool can update (only once) the virtualized XML document. XGTagger relies on the XTReSy [Lini2001a] tag visibility model to virtualize XML documents. Our proposed concept of virtual string is conceptually close to Tannier's concept of reading context. Our virtualization mechanism is more flexible than XGTagger [Tannier2006a, Tannier2006b]. Firstly, our API allows to dynamically invoke an arbitrary number of virtualizations and updates to different sections of the XML document. Secondly, XGTagger cannot return match points. Thirdly, though reading contexts are backed by the underlying XML document, XGTagger does not expose the XML document to the external updating tool. Fourthly, our tag visibility model is an extended version of the XTReSy [Lini2001a] model on which XGTagger relies to virtualize XML documents; the distinction between visible and terminal tags in our model allows the API user to transparently obtain a scoped iterator over multiple virtual strings.
XQuery
The XQuery [XQuery] retrieval language allows, among many powerful features, full text search in XML-encoded
corpora (keyword search as well as, to a certain extent, regexp search). The Full
Text extension [XQueryXPathFullText, XQueryFullTextIntro, Imhof2008a] adds full-text search capabilities to XQuery. The Full Text extension is a very
recently (as of January 2010) stabilized W3C Candidate Recommendation. The Full Text
extension does support tag-aware search, to a certain extent. Tags can be configured
to be made invisible during search through the use of the FTIgnore option. It must be noted that constructing an intermediate full text representation
and searching this full text representations are tightly interwoven, in order to return
to user code the XML elements that include contents matching the full text search
query.
XQuery, through its Update Facility [XQueryUpdate, XQueryUpdateIntro], allows powerful forms of updates to the processed XML document. The Update Facility is a recently (as of June 2009) stabilized W3C Candidate Recommendation. Its internal representation is tree-based and XPath-addressable [XPath]. XQuery Full Text and XQuery Update Facility could thus be combined.
XQuery considered together with XQuery Full Text and the XQuery Update Facility is a very powerful and versatile technology. What then could make it unsuitable for the semantic tagging of the FEW dictionary? FEW algorithms often need to perform additional search operations in the textual context around full text search matches. Results returned to user code by XQuery, though, are XML elements. It is thus not straightforward to perform subsequent search operations on these results, or obtain match points for arbitrary characters in the context of the returned results.
We hypothesize that our proposed virtual text retrieval API might be implemented in XQuery on top of Full Text. However, we also hypothesize that offering the same expressiveness and flexibility would lead to a performance overhead. Indeed, XQuery returns XML elements instead of virtual strings, which means a partial loss of intermediate information (such as match points) that will have to be reconstructed over and over. It is possible, however, that such performance overhead could be addressed through good software engineering and extensions to the XQuery language.
Philosophically, the key feature of our proposed virtualization mechanism over XQuery is to offer linguists a way to think of the dictionary and express themselves in a familiar environment: text without tags.
Other relevant works
The lq-text [Quin2008a] retrieval tool allows full text search in XML-encoded corpora (both keyword search as well as regexp search). It does support a limited form of update, i.e. adding tags around keyword matches. It supports useful Natural Language Processing features such as punctuation-aware and plural-aware search. Its internal representation is not tree-based. It does not support tag-aware search (as considered in this paper), as far as we can tell.
The Nexi [Kamps2006a] query language allows full text search in XML-encoded corpora (keyword search only). It does not allow updates. It does support tag-aware search based on several expressive query forms (it is claimed to be at least as expressive as XML Fragments [Carmel2003a], see above), but not to the extent required for the semantic tagging of the FEW dictionary (see [Kamps2006a], Section 6, p. 433).
Semantic Tagging of XML-Encoded Corpora
The semantic tagging of the Dictionary of Middle Dutch [Voort2005a] as well as of the TLFi dictionary [Dendien2003a, TLFi, TLFi04a] were partially automated. However, due to lack of support for virtualization of the XML document, there was little flexibility in the retrieval of the fields of information. Exceedingly complex and brittle regular expressions including hard-coded markup were used. In practice, this certainly limited any changes to the sequence in which fields of information were tagged, and also discouraged the use of attributes in the markup (because tags, attributes and attribute values all had to be hard-coded statically within the regular expressions).
Concluding Remarks
An API providing support for flexible tagging of text-oriented XML documents was introduced in this paper. It is based on the virtualization of selected sections of the XML document. It enables tag-aware full text search, obtaining match points and transparent updates to the underlying XML document. The API enabled successful, automated tagging [Renders2009a, Briquet2009a] of a test corpus (146 articles, about 0.75% of the total number of articles) of the digitized version of the FEW, which is one of the most complex paper dictionaries. Coverage, defined here as the percentage of the length of relevant sections of the XML document that are semantically tagged, consistently converges around 99.3%. Precision and recall are not yet available. These metrics are very difficult to measure in the context of the FEW: A highly-trained human operator would need several days to manually add semantic tagging to the average FEW article.
A Java implementation of the API was completed during the summer of 2009. The API itself is comprised of ~7500 lines of Java code, with additional dependencies on other parts of the code base (~69000 lines) of the FEW semantic tagging project, notably the node list data structure. It is clear that the current implementation, while 100% operational and used in production for a real-world project, can be optimized for speed (addressing, virtual text update and virtual tag splicing APIs) and for improved memory management (text virtualization API). One of the logical next steps will be to package (and optimize) the API implementation and the node list data structure into a library, so that other projects can benefit from them as well. External feedback on the syntax, semantics and expected performance of the operations provided by the API will be valuable.
To conclude, the take-home message could be stated as follows. Our proposed virtual text retrieval API might be implemented in XQuery on top of Full Text, although probably at the expense of a performance overhead. The key feature of our proposed virtualization mechanism is to offer linguists a way to think of the dictionary and express themselves in a familiar environment: text without tags. Its flexibility and expressiveness are derived from (unconsciously, though, at the time of mechanism design) blending prior ideas, i.e. reading contexts [Lini2001a, Tannier2006a, Tannier2006b] and regular fragmentations [StLaurent2001a], with a good dose of dynamicity. Given the scope and complexity of the FEW dictionary [Renders2007a, Wartburg1922a], an environment or data processing abstraction that is flexible and familiar to the API user might be more important than the power and breadth of features of successful, general-purpose technologies such as XQuery [XQuery]. Support for natural linguistic reasoning, i.e. tag-aware mixed-information (text/markup) retrieval and update, is the main contribution of our paper.
Acknowledgments
We would like to thank Xavier Dalem, Stéfan Sinclair and the anonymous reviewers for their helpful suggestions that greatly improved the quality of the paper. We also would like to thank Eva Buchi for her encouragement to prepare this paper, as well as for a particularly relevant bibliographical hint that greatly helped us identify related works.
Figure 1 includes icons from the Tango library, under Creative Commons Attribution Share-Alike license.
Finally, we would like to thank Chris Lilley for proofreading the final version of the paper; of course, all remaining typos and grammatical mistakes are ours.
References
[Briquet2009a] Cyril Briquet and Pascale Renders. «Une approche reposante (RESTful) des aspects opérationnels de la rétroconversion du Französisches Etymologisches Wörterbuch (FEW)». Proc. Liège Day in Processing of Gallo-Roman Sources (TraSoGal), May 2009.
[Buchi1996a] Éva Büchi. «Les Structures du /Französisches Etymologisches Wörterbuch/. Recherches métalexicographiques et métalexicologiques», Niemeyer, Tübingen, 1996.
[Carmel2003a] David Carmel, Yoelle S. Maarek, Matan Mandelbrod, Yosi Mass and Aya Soffer. «Searching XML documents via XML fragments». Proc. SIGIR, Toronto, ON, 2003.
[Dendien2003a] Jacques Dendien and Jean-Marie Pierrel. «Le Trésor de la Langue Française informatisé. Un exemple d’informatisation d’un dictionnaire de langue de référence». In Traitement Automatique des Langues 43 (2), 2003.
[DeRose2004a] Steven DeRose. «Markup Overlap: A Review and a Horse». In Proc. Extreme Markup Languages, Montréal, Québec, August 2004.
[DOM] Document Object Model (DOM). [online] [cited April 15, 2010] http://www.w3.org/DOM/
[GATE] General Architecture for Text Engineering. [online] [cited June 25, 2010] http://gate.ac.uk/
[IE] Information Extraction. [online] [cited June 25, 2010] http://en.wikipedia.org/wiki/Information_extraction
[IBMIE] IBM Trainable Information Extraction Systems. [online] [cited June 25, 2010] http://www.research.ibm.com/IE/
[Imhof2008a] Julia Imhof. «Evaluation Strategies for XQuery Full-Text». M.S. Thesis, ETH Zurich, September 2008.
[Kamps2006a] Jaap Kamps, Maarten Marx, Maarten de Rijke and Börkur Sigurbjörnsson. «Articulating Information Needs in XML Query Languages». In ACM Transactions on Information Systems 24 (4), October 2006. doi:https://doi.org/10.1145/1185877.1185879
[Lini2001a] Luca Lini, Daniella Lombardini, Michele Paoli, Dario Colazzo and Carlo Sartiani. «XTReSy: A Text Retrieval System for XML documents». In D. Buzzetti, H. Short, and G. Pancalddella, editors, Augmenting Comprehension: Digital Tools for the History of Ideas. Office for Humanities Communication Publications, King's College, London, 2001.
[OED] Oxford English Dictionary. [online] [cited June 25, 2010] http://www.oed.com/
[OED] Oxford English Dictionary. [online] [cited June 25, 2010] http://en.wikipedia.org/wiki/Oxford_English_Dictionary
[ProjectFEW] Französisches Etymologisches Wörterbuch. [online] [cited April 15, 2010] http://www.atilf.fr/few
[Pugh1990a] William Pugh. «Skip lists: a probabilistic alternative to balanced trees». Communications of the ACM 33 (6), June 1990. doi:https://doi.org/10.1145/78973.78977
[Quin2008a] Liam R. E. Quin. «Text Retrieval for XML-Encoded Corpora: A Lexical Approach». Proc. Balisage, August 2008. doi:https://doi.org/10.4242/BalisageVol1.Quin01
[Renders2007a] Pascale Renders. «L’informatisation du Französisches Etymologisches Wörterbuch : quels objectifs, quelles possibilités ?». Proc. Congrès International de Linguistique et de Philologie Romanes, Innsbruck, Austria, September 2007.
[Renders2009a] Pascale Renders and Cyril Briquet. «Conception d’algorithmes de rétroconversion». Proc. Liège Day in Processing of Gallo-Roman Sources (TraSoGal), May 2009.
[RegFrag] Regular Fragmentations [online] [cited April 15, 2010] http://www.simonstl.com/projects/fragment/
[Savage2010a] Neil Savage. «New Search Challenges and Opportunities». Communications of the ACM 53 (1), January 2010. doi:https://doi.org/10.1145/1629175.1629183
[StLaurent2001a] Simon St.Laurent. «Treating Complex Textual Content as Markup». Proc. Extreme Markup Languages, Montréal, Québec, 2001.
[StringProjection] String Projection [online] [cited April 15, 2010] http://en.wikipedia.org/wiki/String_projection
[TLFi04a] «Trésor de la Langue Française informatisé» (TLFi) CD-ROM, CNRS Editions, Paris, 2004.
[TLFi] Trésor de la Langue Française informatisé [online] [cited April 14, 2010] http://atilf.atilf.fr/tlf.htm
[Tannier2005a] Xavier Tannier, Jean-Jacques Girardot and Mihaela Mathieu. «Classifying XML Tags through Reading Contexts
». Proc. ACM Symposium on Document Engineering, Bristol, UK, 2005. doi:https://doi.org/10.1145/1096601.1096638
[Tannier2006a] Xavier Tannier. «Traiter les documents XML avec les contextes de lecture
». Traitement Automatique des Langues 47 (1), 2006.
[Tannier2006b] Xavier Tannier. «Extraction et recherche d'information en langage naturel dans les documents semi-structurés». PhD Dissertation, Ecole Nationale Supérieure des Mines, Saint-Etienne, September 2006.
[Voort2005a] John van der Voort van der Kleij. «Reverse Lemmatizing of the Dictionary of Middle Dutch (1885-1929) Using Pattern Matching». Proc. Conf. Computational Lexicography and Text Research, Budapest, Hungary, 2005.
[Wartburg1922a] Walther von Wartburg et al. «Französisches Etymologisches Wörterbuch. Eine darstellung des galloromanischen sprachschatzes», 25 volumes, Bonn/Heidelberg/Leipzig-Berlin/Bâle, Klopp/Winter/Teubner/Zbinden, 1922-2002.
[XPath] XPath [online] [cited April 15, 2010] http://en.wikipedia.org/wiki/XPath
[XQuery] XQuery [online] [cited April 15, 2010] http://en.wikipedia.org/wiki/XQuery
[XQueryXPathFullText] XQuery and XPath Full Text 1.0 [online] [cited June 25, 2010] http://www.w3.org/TR/xpath-full-text-10/
[XQueryFullTextIntro] Xavier Franc. XQuery Full-Text for the impatient [online] [cited June 25, 2010] http://www.xmlmind.com/_tutorials/XQueryFullText/index.html
[XQueryUpdateIntro] Xavier Franc. XQuery Update for the impatient: A quick introduction to the XQuery Update Facility [online] [cited April 15, 2010] http://www.xmlmind.com/_tutorials/XQueryUpdate/index.html
[XQueryUpdate] XQuery Update Facility 1.0 [online] [cited April 15, 2010] http://www.w3.org/TR/xquery-update-10/
[1] The research reported in this paper was supported by grant ANR-06-CORP-007-03.
[2] The majority of the research reported here was conducted while Cyril Briquet was at CNRS in 2008-2009.
[3] After the encounter with an invisible tag, the encounter (immediately or a few nodes further) with a terminal tag, as well as the encounter with the end of the node list, triggers a virtual string to be returned to the calling code. This is not the case when a visible tag is encountered. As invisible tags have precedence over visible tags, the latter ones are also skipped until a matching closing invisible tag is encountered.