Williams, Jorge Luis, and David Cramer. “Using XProc, XSLT 2.0, and XSD 1.1 to validate RESTful services.” Presented at Balisage: The Markup Conference 2012, Montréal, Canada, August 7 - 10, 2012. In Proceedings of Balisage: The Markup Conference 2012. Balisage Series on Markup Technologies, vol. 8 (2012). https://doi.org/10.4242/BalisageVol8.Williams01.
Balisage: The Markup Conference 2012 August 7 - 10, 2012
Balisage Paper: Using XProc, XSLT 2.0, and XSD 1.1 to validate RESTful services
Jorge Williams is a principal architect on the
Cloud Integration Team at Rackspace Hosting where
he develops tools and services to solve
integration problems. He has aided in the design
and development of the Repose HTTP proxy, the
Cloud Servers API, the OpenStack Compute and
Identity APIs, and the OpenStack extension
mechanism. He holds a PhD in computer science.
David Cramer is a Documentation Build Developer
on the Cloud Doc Tools team at Rackspace Hosting
where he helps maintain the XML-based tool chain
used to produce Rackspace and OpenStack API
documentation. He has also been involved with the
DocBook project for several years.
Documentation of RESTful services must be accurate and
detailed. As a REST service is being developed, the
documentation must be kept up to date and its accuracy
constantly validated. Once the REST service is
released the documentation becomes a contract; clients
may break if an implementation drifts from the
documented rules. Also, third-party implementations
must adhere to the rules in order for clients to
interact with multiple implementations without
issue. Ensuring conformance to the documentation is
complicated, tedious, and error prone. We use our
existing XML documentation pipeline to generate highly
efficient validators which can check a RESTful service
(and it's clients) for conformance to the
documentation at runtime. We validate all aspects of
the HTTP request including message content, URI
templates, query parameters, headers, etc. We describe
the transformation process and some of the
optimizations that enable real time optimization and
discuss challenges including testing the documentation
pipeline and the validators themselves.
REST is fast becoming the standard method by which
different software systems interact with one another. As
such, Rackspace produces a large number of RESTful
services both for both internal and public consumption.
Because these RESTful services act as integration points,
they must be documented accurately and at a very high
level of detail. As a REST service is being developed, the
documentation must be kept up to date, and the accuracy of
the documentation as it relates to the actual
implementation of the service must be constantly
validated. That said, once the REST service is released
the documentation becomes a fixed contract. At this time,
there exists the possibility that an implementation my
inadvertently drift from what is described in the
documentation and this may cause clients to break. Also,
when dealing with open source services, other
implementations of the same service may be developed by
third parties, and it's important for these implementation
to behave according to the rules specified by the
documentation as well in order for clients to interact
with multiple implementations without issue. The process
of ensuring conformance to the documentation is
complicated, tedious, and error prone.
To automate the process, we had the idea to use our
existing XML documentation pipeline based on XProc, XSLT
2.0, DocBook and WADL, which already produced HTML and PDF
documentation artifacts, to generate highly efficient
validators as well. These validators can be used to check
a RESTful service (and its clients) for conformance to the
documentation at runtime in a very efficient manner. The
validators are capable of using an XSD 1.1 implementation
(either Xerces or Saxon) to validate not just the content
of a request, but also to perform checks on URI templates
and query parameters. The process illustrates the power of
single sourcing, in that the same source that is used to
produce human readable artifacts is also used to produce
machine readable validation instructions. As a result,
from the same artifact, we are able to:
document APIs consistently and efficiently.
produce different documentation artifacts
such as user guides, specifications, and quick
reference web pages.
validate the accuracy of our API
implementations and their clients.
help describe the calls a particular user
is authorized to make in an API.
The purpose of this paper is to describe our REST
documentation pipeline and discuss how it was adapted to
produce REST validators. We give a detailed overview of
the transformation process, including a description of
some of the optimizations performed to achieve efficient
real time validation. We also describe some of the
challenges we've encountered -- including testing the
documentation pipeline.
Background
About REST
REST (REpresentational State Transfer) is an
"architectural style" described by Roy Fielding in his
PhD dissertation Fielding2000. REST
seeks to adapt the architecture of the Web, along with
its scalability, performance, and other advantages, as
a platform for any kind of application. In REST, as on
the Web, a resource is an item of
interest. Each resource has an address (URI) and one
or more representations (a file
with a given media type). A client can interact with a
resource through a URL and these interactions in turn
act as the engine of application state because the
representations provide hypermedia links offering
alternative directions the client can take to proceed
through the workflow. The RESTful ideal is that just
as you interact with a Web site and choose which step
to take next, without being frustrated that the layout
of the page and links offered have changed since the
last time you visited the site, so a client using a
RESTful API can pick its way through a workflow
without demanding a fixed, brittle contract. Likewise,
the Web's mature and well-understood caching
mechanisms can improve the performance and scalability
of your application, protecting the server from spikes
in traffic and the client from brief interruptions in
the server's availability.
While many APIs describe themselves as RESTful, some
RESTful APIs are more RESTful than others. At the most
rudimentary level, APIs may employ one or more URIs,
but still use only one method (GET, POST) to tunnel
their requests over HTTP and do not represent a
radical break from WS-* services. APIs that embrace
the RESTful architecture more fully offer a larger
number of resources, each with a URI, and map a
variety of HTTP verbs to the Create Read Update Delete
(CRUD) operations found in most applications. In these
services, parameters are passed in with requests
either as elements of the URI or as query parameters
appended to the URI. The Web's caching infrastructure
also comes into play. Finally, in an ideal more often
discussed than achieved, services that fully embrace
the idea of hypermedia as the engine of application
state (HATEOS), relying on the client to navigate
through the workflow in the same way an end-user at an
e-commerce site would, by inspecting the available
links and picking the appropriate one.
About Rackspace and OpenStack Developer
Documentation
Rackspace is a hosting company that found
itself well positioned to play a significant role in
the sea change from traditional hosting to cloud
computing started by Amazon Web Services. The
Rackspace strategy involves creating an open source
alternative to the closed, proprietary world of vendor
lock-in that AWS represents. To that end, Rackspace
partnered with NASA to create a collection of open
source cloud software, called OpenStack. Since its launch in 2010,
OpenStack has enjoyed rapid growth as an open source
project with hundreds of companies and individuals
participating. Since much of the code that we develop
is contributed to OpenStack, we needed an approach to
documentation that facilitated interchange and
collaboration. DocBook and the XSLT stylesheets from
the DocBook Open Repository provide the basis
for our documentation tool chain.
Our documentation pipeline contains the typical
components: a schema, authoring environment, source
control system, build system, and hosted artifacts. In
particular, we use:
A variant of the DocBook 5.0 schema,
called RackBook.
A Java Web Start version of the oXygen XML editor with a
custom framework to support RackBook and
our specific needs. Contributors are free
to use any text editor, but the customized version of oXygen
provides many convenience features.
Customizations on top of the DocBook
XSLT stylesheets to produce pdf and HTML
output branded for Rackspace, OpenStack,
or other partners as necessary.
An extended version of the DocbkxMaven plugin to manage
build-time dependencies and perform the
build logic to generate artifacts. We've
extended Docbkx to incorporate Calabash so that we can
preprocess our source code with XProc
pipelines. Because OpenStack also relies
on this tool, we have open sourced our
version of the Maven plugin (clouddocs-maven-plugin).
We store our source code in a internal
git repositories and schedule builds using
Jenkins jobs.
Why WADL?
We evaluated frameworks that provide test consoles
and some level of documentation for RESTful APIs like
Apigee, Mashery,
and Swagger, but found each lacking one or
another important feature. We ultimately decided to
leverage our DocBook-based tool chain to create human
and machine readable descriptions of the APIs from the
same source. The human readable artifacts are the
documentation, and the machine readable WADL would
facilitate the run-time validation of API calls in the
via Open Repose, our open source RESTful proxy. There
are a number of reasons why we chose WADL over using
an existing alternative description languages or
designing our DSL:
The WADL vocabulary includes a number of
features that facilitate authoring and
content reuse.
Since WADL is XML, it fit easily into
our existing DocBook pipeline.
The format is extensible and thus it is
simple to add support for new features and
niche use-cases.
The format is grammar agnostic. This
means that a grammar can be specified in
XML Schema for XML media types and JSON
Schema for JSON media types.
Additionally, grammars can be used not
just to make assertions about the content
of HTTP payloads as a whole, but also to
make assertions about a particular subset
of it.
Grammars can also be used to make
assertions over all aspects of an HTTP
request or response: template parameters,
matrix parameters, query parameters and
headers.
WADL is specific to the HTTP protocol
and captures all of that protocol's
features. As such, it's a perfect markup
language for semantically describing
RESTful services.
We elaborate on some of the more
important features in detail in the following
sections.
Flexibility
One of the nice features of WADL is that it has
a very flexible schema especially when associating
URI paths to resources. For example, suppose we
have a very sparse API that allows a
GET and DELETE
operation to occur only at the URI
https://test.api.openstack.com/path/to/my/resource.
This can be represented in a WADL in the following
manner:
Note that each individual path segment in the
URI is represented by a
<resource> element. While
the approach would work well in cases where the
API has a complex structure with many resources,
it's overkill for this example. Instead, we can
represent the API like this:
Here, a <resource> element
covers multiple segments in the path all at once,
in this case path/to/my/resource.
Given the sparse API, this is far more convenient.
The WADL need not be entirely written in the form
illustrated in Example 1 (tree
form) or in the form in Example 2
(flat form). A WADL can contain resources that are
simultaneously in both forms (mixed form) as
illustrated here:
In Example 3 we have two
<resource> elements, one
for path/to/my and another for
resource. The ability to intermix
flat and tree forms, allows the WADL author the
flexibility to start with a simple API description
and expand on it as the API grows in complexity.
Content Reuse
WADL contains a number of features that
encourages content reuse. First,
<method>,
<representation>, and
<param> elements can be
specified separately from individual resources and
therefore can be shared between them. For example
suppose that you have two resources
widgets and gadgets
both of these resources contain a method to access
metadata. You can repeat the method definition in
both resources as illustrated in Example 4.
Repeating the method however can be error prone
and tedious. Instead, the method can be written
once and referenced from the individual resource
as illustrated in Example 5.
Example 5: Two resources with a common shared
method
Note that the method is referred to by its
id and the hash (#) is used to
denote the internal link. It's possible that
multiple related methods can be shared between
resources. One can express multiple methods
together, as in Example 6,
however this too can get tedious an error prone.
Example 6: Two resources with a common shared
methods
To alleviate this issue, WADL defines the
concept of a resource_type. A
resource_type contains common
behavior that can be shared between multiple
resources. This is illustrated in Example 7.
Example 7: Two resources with a common resource
type
Note that <method>,
<representation>,
<param>, and
<resource_type> elements
need not appear in the same WADL, they may be
linked in from an external WADL as illustrated
below.
Example 9: Two resources with a common external
resource type
All elements defined by the WADL specification
can be associated with inline documentation via
the <doc> element. A simple
illustration of this is shown in the example
below.
Example 11: Resource type with doc element
<resource_type id="BackupList">
<doc xml:lang="EN" title="Backup List">
<p xmlns="http://www.w3.org/1999/xhtml">
A list of backups. Each backup contains IDs, names, and
links -- other attributes are omitted.
</p>
</doc>
<method href="#listBackups"/>
</resource_type>
Note that Example 11 uses the XHTML
grammar for narrative text. This is not a
requirement, different narrative text grammars can
be used. Also note the used of the
xml:lang attribute, multiple
<doc> elements can be used
each in a different language to aid in the
internationalization of the WADL. The
title element can be used to give
an overview of the documentation text.
Grammar Agnostic Assertions
WADLs contain a <grammars>
element that allows the association of grammars
such as XML Schema with a REST API. Grammars may
be included by means of the
<include> element as
illustrated in Example 10 or they
may be written inline as shown in Example 12.
The WADL specification does not encourage the
use of a specific schema grammar over another, but
allows the usage of multiple grammars within the
same WADL. This enables support for APIs where
resources are exposed via multiple mediatypes such
as XML and JSON.
Besides using grammars to make assertions about
a particular media types, they can also be used to
make assertions about other aspects of the HTTP
request and response. This is illustrated in Example 12.
A 36 character long string that
represents five groups of
hexadecimal digits separated by
hyphens.
We associate these simple types
with path elements in the URI by means of template
parameters. Thus, we are denoting that the URI
paths:
path/to/my/resource/3bba8e68-8af5-11e1-ac65-17a552dd2535
and path/to/98 are valid according to
the WADL, but URI paths such as
path/to/my/resource/xyz and
path/to/101 are not.
Finally, we can use grammars to make assertions
about individual sections of the mediatype by
means of plain parameters. This is
illustrated in method in Example 13.
Example 13: Method with a plain parameter and a
link
Here we define that the response to the
versionDetails method should
contain an XML payload that validates against the
element defined by the QName
common:version. Additionally, we
make an assertion that at the XPath
/common:version/atom:link[@rel='self']/@href
there should be a value that validates against the
type xsd:anyURI. Furthermore, this
URI should provide a link to a resource with a
resource_type of
VersionDetails.
Note that plain parameters can also be used by
mediatypes that are not XML based. Launchpad
uses JSONPath to make similar assertions on its JSON
based API. This is illustrated in Example 14.
Here we state that there should exist JSON
attributes at the JSONPaths given by
$['total_size'],
$['start'], and
$['entries']. Additionally the
fields at $['resource_type_link'],
$['next_collection_link'],
$['prev_collection_link'], and
$['entries'][*]['self_link']
should contain links to other resources.
Note that Launchpad uses plain parameters to
make assertions about various aspects of the JSON
representation without having to
rely directly on JSON schema.
This ability to reference elements from external
WADLs allows for common behavior to be shared
between different APIs and has the potential to
significantly accelerate the definition of APIs
with common attributes and behaviors.
Extensibility
The WADL specification defines a fairly standard
extensibility model of allowing elements and
attributes in foreign namespaces. The example
below illustrates a number of Apigee extensions,
including one which indicates that authentication
credentials are not required in this particular
method call.
Example 15: Method with Apigee Extensions
<method id="statusespublic_timeline" name="GET" xmlns:apigee="http://api.apigee.com/wadl/2010/07/">
<apigee:tags>
<apigee:tag primary="true">Timeline</apigee:tag>
<apigee:tag>Status</apigee:tag>
</apigee:tags>
<apigee:authentication required="false"/>
<apigee:example url="/statuses/public_timeline.{format}"/>
<doc title=""
apigee:url="http://dev.twitter.com/doc/get/statuses/public_timeline">Returns
the 20 most recent statuses, including retweets if they exist,
from non-protected users.</doc>
</method>
The ability to support extensions means that
niche capabilities can be inserted into the WADL
in a compatible manner.
Documentation from WADL
A WADL describes a RESTful API in a machine readable
format. There is often a need, however, for humans to
study and understand the available methods,
parameters, and representations the API offers. Rather
than manually reproducing that information in a
documentation format and trying to keep these
synchronized, clearly a literate programming approach
is called for.
In pursuing our literate program approach, we
considered extending DocBook with custom markup that
we could then use to generate WADL. This approach was
attractive in that it would allow us to make the
contract author's experience like writing
documentation. However, we worried that we would be
reinventing the wheel and would spend too much time
creating a content model that could be turned into
WADL. We also felt that we would need to support
round-tripping between our extended-DocBook and the
generated WADL. Ultimately, we decided to allow
authors to embed WADL markup directly in the DocBook.
To allow for this we:
Added support for certain elements from
the WADL namespace in our customization of
DocBook.
Added steps to our processing pipeline
to turn the WADL elements into
DocBook.
In writing the narrative description of
the API, you can include either pointers to an
external WADL or literal WADL. The following example
shows a fragment of our DocBook-variant with a pointer
to resource/method combination in an external WADL:
Example 16: DocBook With WADL Elements
<section>
<title>Volume Lists</title>
<para>
These operations provide a list of volumes associated
with a particular tenant. Volumes contain a status
attribute that can be used as an indication of the
current volume state. Volumes with an
<code>AVAILABLE</code> status are available for
use. A volume with an <code>ATTACHED</code> is
currently attached to a server. Other possible values
for the status attribute include:
<code>CREATING</code>,
<code>ATTACHING</code>,
<code>DETACHING</code>,
<code>DELETING</code>,
<code>DELETED</code>,
<code>UNKNOWN</code>, and
<code>ERROR</code>.
</para>
<para>
The list of volumes may be filtered by type, backup,
name, and status via the respective query parameters.
When retrieving a list of volumes via the
changes-since parameter, the list will contain volumes
that have been deleted since the changes-since time
(see Section 3.5, in the OpenStack Compute Dev Guide
for a description of Changes-Since).
</para>
<resources xmlns="http://wadl.dev.java.net/2009/02">
<resource href="os-block-storage-1.0.wadl#Volumes">
<method href="listVolumes"/>
</resource>
</resources>
</section>
The wadl:resources element
wraps one or more resources, as it would
in a normal wadl.
The wadl:resource element
wraps one or more methods and defines the
location of the wadl and the
id of the resource for
the methods.
The wadl:method element
points to a method defined in the WADL.
Each method becomes a section
in the resulting DocBook. All of the
methods with a common DocBook
section ancestor become
sections within that
section. Alternatively,
you can omit the wadl:method
and the system will create sections for
all of the methods that are children of
the resource in the target wadl.
To ease the burden on authors, we have created
schematron rule in a custom framework for the oXygen
editor to validate that the references to
the WADL point to ids in the WADL.
In addition to pointing to resource and method
combinations, it is also possible to point to a
resource and have all the methods within that resource
pulled into the document or to point to the WADL and
have all of the resources and methods from the WADL
pulled in.
Finally, instead of pointing to an external WADL,
the author can simply include the entire
wadl:resource and
wadl:method(s) in the DocBook
document directly.
The following is an image of the section produced
in PDF result after processing [Example 16]:
Figure 17: Resulting WADL PDF Section
The following is the WADL method that is being
imported into the DocBook:
Note that while many of the attributes and elements
map directly from the WADL representation to the PDF
rendering, there exist some subtleties:
Query parameters are rendered in two
different ways: Inline with the URI and in the
Request Parameters table
Section, Table, and Example titles are
automatically generated based on context. For
example, the example title "List Volumes
Response: XML" is generated because there is a
representation example of mediaType
application/xml that is contained within
method called "List Volumes".
Parameter descriptions are also generated
based on context.
Other parameters such as the
tenantId parameter are
implied simply because of the URI the method
is associated with.
Note the use of the xsdxt:code
extension to associate an example document
with the API response.
WADL Normalization
As described in section “Content Reuse”, the
WADL format includes a number of features that
facilitate WADL authoring and content reuse. For
example, when creating a WADL, it is typical to put
all of the method
elements at the end of the document and refer to them
indirectly from the resources where they are used. You can
link to methods in a separate WADL. Likewise, you can
define resource_type
elements containing various methods and parameters.
Each resource can
then be declared to be of one or more resource types
to avoid repeated information. Finally, WADLs can
refer to XSD files to define data types used in the
WADL. The XSD files in turn often have a modular
design. While these features facilitate information
reuse and support "single point of truth" practices, a
side effect of the indirection is that WADLs can be
difficult to process. To address this issue, we
created a WADL normalizer which uses XSLT to flatten
out the WADL and associated XSDs. In the WADL, for
example, all references to methods and
resource_types are resolved. Further
processing is therefore greatly simplified. We have
made this tool available as open source software.
Use cases for the WADL normalizer include:
Preparing the WADL for use with tools
like SoapUI. Limitations and bugs
in SoapUI cause it to fail if certain
features of the WADL are used. For example
if you use resource_types or
refer to a method in an external WADL,
SoapUI cannot load the WADL and throws and
exception.
The WADL normalizer is implemented as
XSLT 2.0 stylesheets. In their current form, the
stylesheets use modes to take several passes at the
WADL, but they would benefit from being implemented as
an XProc
pipeline.
The WADL normalizer offers a number of options to
control the formatting of the normalized wadl file,
summarized by the usage
below:
dcramer@anatine ~/rax/wadl-tools/src/test/scala (scalaCLI)
$ normalizeWadl.sh -?
Usage: normalizeWadl.sh [-?fvx] -w wadlFile
OPTIONS:
-w wadlFile: The wadl file to normalize.
-f Wadl format. path or tree
path: Format resources in path format,
e.g. <resource path='foo/bar'/>
tree: Format resources in tree format,
e.g. <resource path='foo'><resource path='bar'>...
If you omit the -f switch, the script makes no
changes to the structure of the resources.
-v XSD Version (1.0 and 1.1 supported, 1.1 is the default)
-x true or false. Flatten xsds (true by default).
-r keep or omit. Omit resource_type elements (keep by default).
One of the most important options is the format of
the resource paths. By default, the normalizer leaves
the path attributes on the resource elements
unchanged. So if the source wadl contains a mixture of
hierarchical and flat path attribute values, these are
left untouched. In the following code listing, notice
that some of the resource elements are nested and
others have multiple items in the path
attribute:
The
rax:id attributes have been added to
preserve the original ids that could not be duplicated
in the normalized wadl without making the wadl
invalid. These are required for down-stream processing
when we generate documentation from the normalized
wadl.
You can also expand the flat paths into a fully
hierarchical tree format. The following example shows
the same wadl expanded into the tree
format:
In addition, the normalizer can optionally flatten
out XSDs by pulling in included XSDs and filtering
based on the vc:minVersion and
vc:maxVersion attributes.
Finally, you can optionally filter out
resource_type elements from the
normalized wadls. In some cases, it is useful to
preserve these element, but they can cause problems
for certain tools. Therefore a parameter is provided
filter out the resource_types.
The Validation Problem
As a REST service is being developed, the goal is to
ensure that the documentation accurately matches the
implementation. Once a REST service reaches a mature
state, or is released publicly, the documentation becomes
a contract; both clients and alternate implementations use
this contract to guide their development. Iteroperability
between all parties requires that both the documentation
and the implementation remain stable, even in the face of
bug fixes, upgrades, enhancements, and the introduction of
new features via extensions.
In the presence of these changes, there always exist the
possibility that either the implementation or its docs may
inadvertently drift from one another. This drift often
introduces incompatibilities that can cause clients to
fail. Thus, it's important to constantly test that the
implementation and its documentation conform to one
another. Unfortunately, our quality engineering teams are
often not focused on document conformance, or on the
intricate details of the REST/HTTP aspects of the
service. Instead, these teams are focused on the
functionality of the service itself. It's been our
experience that a number of incompatibilities often slip
through the cracks as a result. What's more, because this
focus on functional testing has little to no regard to
documentation of the service, we've found cases where both
the implementation and its tests drift away from the docs
simultaneously. Adding to the complexity is the fact that
service developers tend to allow their implementations to
be flexible and loose when accepting messages from clients
— this means that conformance and functional tests
themselves may inadvertently drift from the service
contract without notice.
One of our main goals is to better incorporate the
documentation in the testing process in an automated
way. The idea is to use the documentation pipeline to
generate validation rules that can be checked in a layer
between the function tests and the service itself. This is
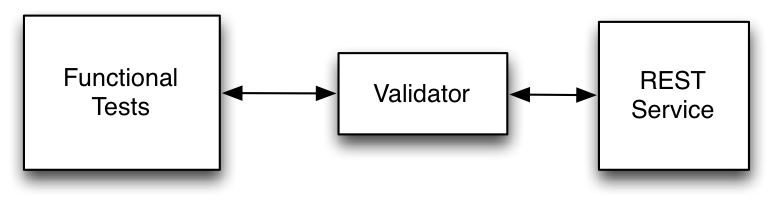
illustrated in Figure 19.
Figure 19: A REST validator
Here, the validator intercepts requests from the
functional tests before they reach the service and check
them for strict conformance to the documentation.
Likewise, the validator intercepts the response for the REST
service and also validates them. There are several
advantages to taking this approach:
Because the validation rules are generated
directly from the documentation, we can ensure
that the validator is strictly accurate with
conformance to the docs.
Because the validator sits between the
functional tests and the service itself, it
can be used to check for drift by both parties
simultaneously.
The technique can be easily incorporated into
existing services — it does not require
changes to existing functional tests.
Validating REST with Automata
Given any possible HTTP message, the validator in Figure 19 needs to be able to tell the difference
between an HTTP message that meets all of the criteria
defined in the documentation, from an HTTP message that
does not. In other words, the validator must accept the
subset of all HTTP messages that are valid according to
the description in the source document. The validator also
needs to categorize those messages that are not valid
according to the error code that should be generated by
the underlying REST service, so that the error code that
the REST service produces can also be verified.
Accepting messages that meet some criteria is a common
problem in computer science. One technique for solving the
problem is to utilize an automaton. An automaton is a
state machine that transitions from an initial
start state to other states based on
the current input. If after the message is read the
machine is in an accept state, then
the message is accepted, otherwise the message does not
meet the required criteria.
The idea behind our validators is to translate
documentation in the form of a WADL (either stand-alone or
extracted from the contents of a RackBook document), into a
representation of an automaton that can be used to
validate messages as they are intercepted between
functional tests and the REST service.
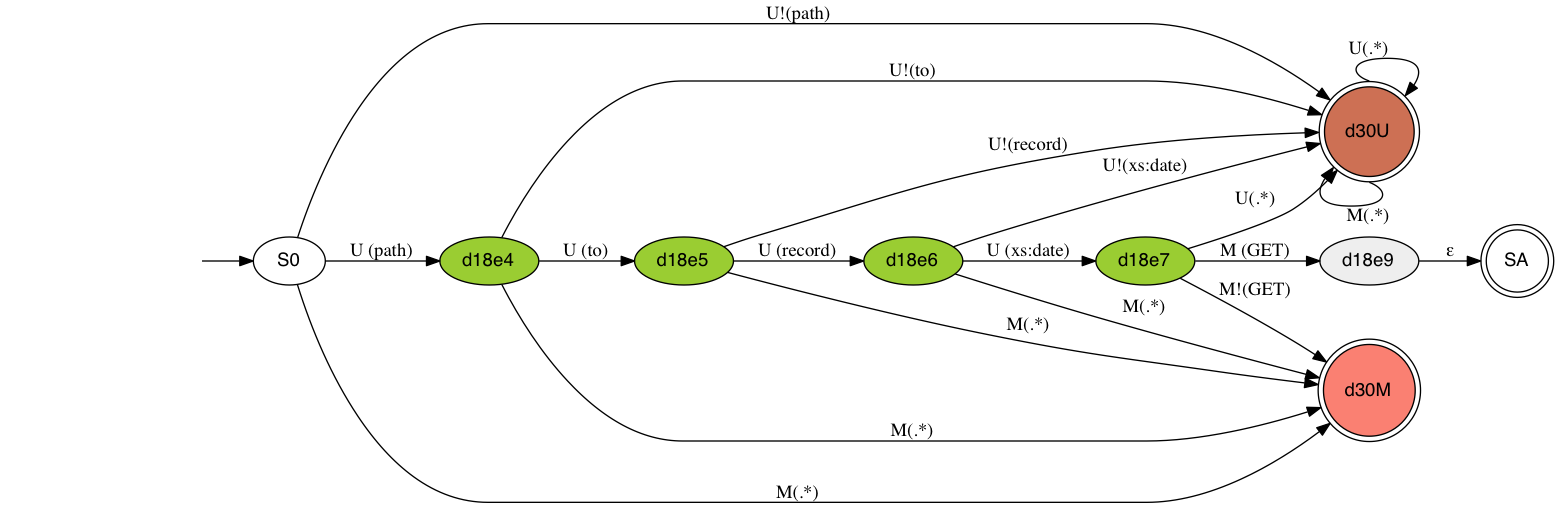
For simplicity, the automaton above is only checking for
conformance to the URL path and the HTTP method. In this
particular API, the only allowed operation is a GET on the
path /path/to/record/{date}, where {date} is an xs:date as
defined by W3C XML Schema W3CSchema2010. The start state is S0. There are
three accept states:
SA: accepts HTTP messages that follow the
constraints defined by the API.
d30U: accepts HTTP messages for which a 404
(Not Found) response should be expected from
the REST service.
d30M: accepts HTTP messages for which a 405
(Method Not Allowed) should be expected.
Starting at state S0, the process examines the URL path,
one path segment at a time. The HTTP method is not
accessible until the path has been completely parsed. The
transition from one state to another is based on input
matches, except in the case of an ε transition,
where a state is advanced without regard to the current
input. In the machine above, U(x) matches the current URL
path segment to x, where x may be a regular expression or
a QName representing an XML Schema simple type. U!(x),
matches an URL segment that is not
accepted by x. On a successful match the URL path is
advanced to the next path element. After the URL path is
completely read, the machine proceeds to read the HTTP
Method. Here, M(x) and M!(x), work the same as U(x) and
U!(x), except they match against the HTTP method instead
of the URL path segment. Because the automaton is only
checking for URL paths and Methods the process ends after
the HTTP method has been read.
Table I illustrates the states that are
transitioned based on an example set of inputs.
REST Automata are internally represented by an XML format,
which we call the checker format. An
instance document in this format is illustrated in Figure 21.
Figure 21: A representation of the automaton from Figure 20 in checker format.
This simple, terse, document type maps each state in the
state machine, along with the edges that it connects to,
into a single step element. All steps in the checker
format contain an id attribute of type xs:ID which
uniquely identifies the step in the machine and a type
attribute which indicates the type of check the step
performs. Note, that in Figure 21,
there are two types of URL checks: the steps that check a
path segment against a regular expression are of type URL,
and those that check the segment against a simple XML
Schema type are of type URLXSD. Connections between steps
are represented by a next attribute of type
xs:IDREFs. Additionally, most steps also contain a match
or notMatch attribute that provides the details of how the
a match is interpreted.
Currently there exist steps to match against all aspects
of the HTTP request, including steps that match against
request media types, that check the well formness of XML
and JSON content, that validate XML via an W3C XML Schema
(XSD) 1.1 validator and that check for the presence of
required elements by means of XPath expressions. Note that
this is particularly important because a REST service may
define many different types of elements, the element
attribute in a representation binds an element to a
particular operation — and this is enforced via an
XPath expression step in the machine.
Another important checker step is the XSLT step, which
performs a transformation of the request message before it
is validated by the XSD step. It may seem odd to that an
XSLT transform may be required for validation, but the
requirement comes into play in cases where the type of the
request document needs to be restricted (or extended)
based on the operation being performed. Let's say, for
example, that a REST API dealing with Widgets allows a
Widget to have all attributes when performing a PUT
operation, but restricts the POST operation to Widget
documents containing only a subset of the available
attributes — this is a common pattern in REST
services. The restriction on POST is specified in the
WADL in Figure 22.
Figure 22: Widget WADL
<?xml version="1.0" encoding="UTF-8"?>
<application xmlns="http://wadl.dev.java.net/2009/02"
xmlns:widget="http://rackspace.com/sample/widget"
xmlns:xs="http://www.w3.org/2001/XMLSchema">
<grammars>
<include href="widget.xsd"></include>
</grammars>
<resources base="http://localhost/">
<resource path="widget">
<param style="template" type="xs:date" name="date"/>
<!-- The PUT operation allows all widgets as request
representation. -->
<method name="PUT">
<request>
<representation mediaType="application/xml" element="widget:widget"/>
</request>
<response>
<representation mediaType="applicaiton/xml" element="widget:widget"/>
</response>
</method>
<!-- The POST operation allows only widgets of the restricted type WidgetForCreate -->
<method name="POST">
<request>
<representation mediaType="application/xml" element="widget:widget">
<param style="plain" path="/widget:widget" type="widget:WidgetForCreate"/>
</representation>
</request>
<response>
<representation mediaType="applicaiton/xml" element="widget:widget"/>
</response>
</method>
</resource>
</resources>
</application>
Note that we use a WADL plain parameter (described in
section “Grammar Agnostic Assertions”) to connect a restricted
type (which prohibits a number of attributes) of the
Widget to the POST operation, by specifying the
WidgetForCreate type and an XPath of where the type should
apply. In the automaton, this is translated into an XSLT
step that modifies the request document by adding an
xsi:type parameter, thus informing the validator to
validate the contents of the Widget message as an instance
of the restricted type. In this case, the restriction is
made in the root document, but these types of restrictions
can be placed on any element in an XML document.
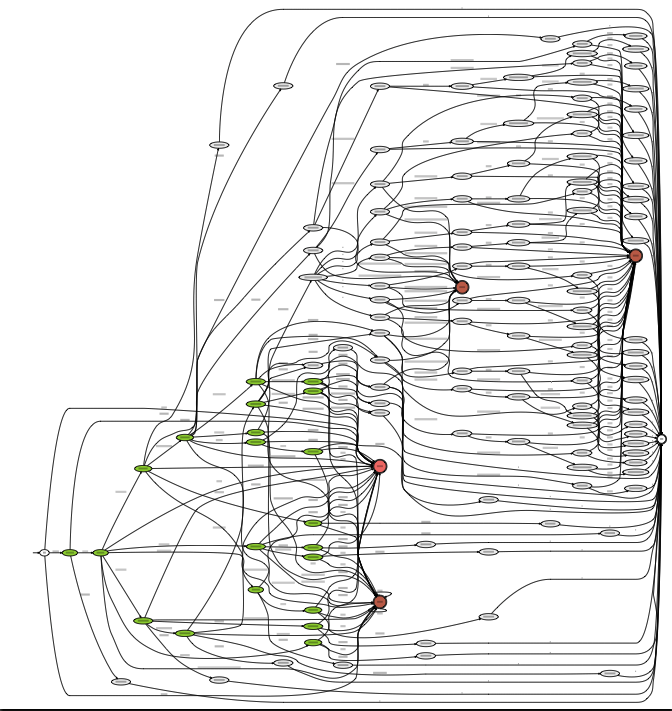
The automata created to validate REST services may be
quite complex, often involving many states and
connections. As an example, Figure 25
illustrates the automaton for validating the OpenStack
Compute API (excluding extensions).
Figure 25: OpenStack compute API Automaton
Optimization stages may be introduced into the
transformation process to try to reduce the number of
states in the automaton. Each optimization stage is simply
an XSLT that takes a checker document as input and creates
a checker document with less states as output.
Optimization stages can therefore be chained together.
With each stage, the checker document produced should
perform the exact same function as the original
unoptimized one.
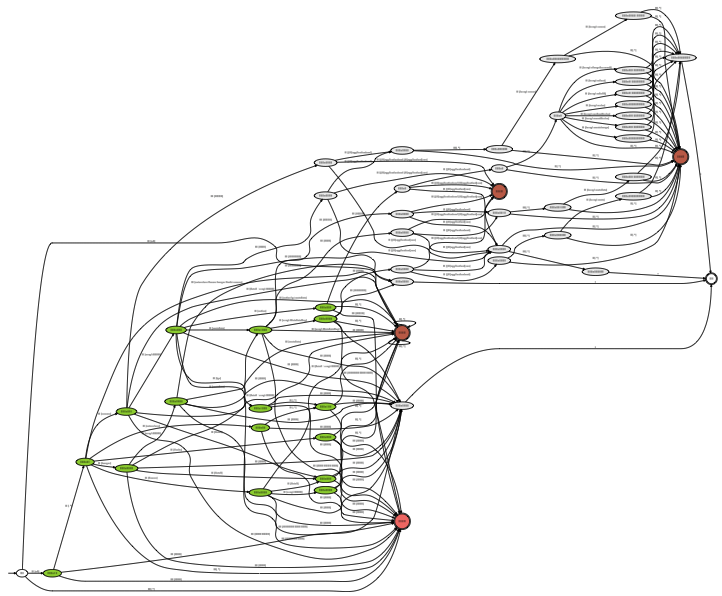
Currently, optimization stages work by compressing
redundant (or nondistinguishable) states into a single
state. Redundant states occur quite frequently because the
translation code that converts a WADL to a checker
document does so without regard to the number of states
produce in order to keep the translation code simple. Figure 26 illustrates the effect of
running these optimization stages on the compute API.
Note that the number of states is reduced dramatically.
Figure 26: OpenStack compute API Automaton (Optimized)
Other optimization techniques are possible. For example
an optimization stage may:
Convert the simple type checks in URLXSD steps
into regular expression URL steps.
Compress multiple regular extension checks
into a single check.
Compress multiple boolean XPath expressions
into a single expression.
Compress XPath expressions, XSLT
transformations, and XSD schema validation
into a single schema aware XSLT transform
step.
The Validation Pipeline
The validation pipeline is responsible for producing REST
automata from WADLs. The pipeline is illustrated in
Figure 27.
Figure 27: Validation Pipeline
The first three parts of the pipeline are shared with our
general documentation pipeline. The stages utilize XProc,
XSLT2, and XSD 1.1 to generate the final checker document.
The final stage, creates an immutable data structure from
this document that is used by the Repose WADL proxy
component to process and validate API requests within the
Repose HTTP proxy. This stage is implemented by means of a
specialized SAX
handler. The data structure the handler produces is
essentially a model of the automaton that can be executed
by the Repose component when validating request. The
process for validating HTTP request with the data
structure avoids the use of global state, meaning that
most context is passed via the call stack. Because of
this, and because the internal data structure is
immutable, the entire process is thread safe, meaning that
it can validate multiple HTTP request simultaneously in
different threads of execution.
It's important to note that the validation pipeline above
is a prepossessing step. Once the immutable data
structure is create it can be used to handle many HTTP
request simultaneously, at run-time, and in an efficient
manner.
Another note is that the stages in the validation pipeline
are configurable. There are configuration options that
dictate:
The strictness of the validation — which
itself is determined by which validation steps
should be added to the final checker.
Specialized options for each individual
steps. For example, should an XPath version 2
implementation be used in an XPath step?
Should Saxon EE or Xerces be used for XSD 1.1
validation in the XSD step?
The optimization stages to use.
Other Use Cases
The initial goal for creating validators from REST
documentation is described in section “The Validation Problem”, however, once an implementation of the validation
pipeline was created, it became evident that the pipeline
can be used to solve other problems. Some of these
additional use cases are described below.
Filtering and Error Reporting
REST services receive many millions of HTTP requests a
day. Many of these requests are malformed — the
result of user errors. Because a validator can detect
malformed requests, it can filter these from the
underlying REST implementation. What's more, the
validator has enough context to respond with an
appropriate error message. For example, rather than
responding with simply a 404 (Not Found), the
validator can respond with:
404 /path/to/widget not found, expecting "server |
image" instead of "widget".
Our implementation has added support to this
capability and it has proved useful.
Authorization
Often different sets of users can access different
parts of the API. For example, administrators may have
the capability to reboot a server, but regular users
may not. The idea here is to build on the filtering
capabilities in the previous section and assign
different sets of users different validators, so that
administrators have a validator that accepts the
reboot operation, and regular users have a validator
that does not. The interesting thing about this
use case is that the WADL becomes an authorization
policy file.
API Coverage
Validators are capable of logging what the stages in
the automaton have been visited. This information can
be used to compute test coverage. If there are states
in the automaton that are not visited by functional
tests, then the functional tests are obviously missing
something. Also, in production, the information can be
used to gain insight into what parts of an API are
frequently accessed by users.
Conclusions
In this paper, we described the process by which we used
an existing documentation pipeline for documenting REST
APIs and extend it to support the creation of validators
that can help confirm that the documentation accurately
reflects reality or that an implementation does not drift
from what's stated in the docs.
We took an intermediary approach for performing validation,
where messages are intercepted between client and server
applications and an automata-based programming approach
that enabled the efficient validation of messages at
run-time. The technique opened up other use cases such as
filtering, accurate error reporting, authorization, and
API coverage. We feel that a main key to the success of
the project was in choosing a tag set that semantically
described all aspects of a RESTful service and contained
author friendly features.
In the next sections we describe some of the challenges we
encountered while developing the validation pipeline and
discuss some possible future extensions to the pipeline.
Challenges
XSD 1.1, early adoption
Because OpenStack APIs are extensible, describing the
XML media types with XSD 1.0 was not an option, we
need the new open content features that are now
offered by the XSD 1.1 standard. Since OpenStack is an
open and free platform, we have the goal of ensuring
that everything that we develop remains open and
accessible to the community, while still remaining
friendly to enterprise customers. To that end we
decided that our validators should support both the
Xerces (open source) and the Saxon EE (proprietary)
XSD 1.1 implementations.
We've had great success in ensuring that our
validators interoperate with both implementations
seamlessly, however, during the development of the
pipeline we have encountered a number of errors with
the Xerces implementation. In fairness, the Xerces
implementation is still labeled BETA, and the Xerces
team has done a great job of resolving most of the
issues we've discovered thus far. The major challenge,
for us however, is we've come to rely on XSD 1.1
features when there is yet a full, production ready,
and free open source XSD 1.1 implementation.
Parsing XPaths in XSLT 2
WADL makes references to XPaths when describing plain
parameters. These XPaths need to be successfully
copied as they proceed along the validation
pipeline. Ensuring that the XPaths remain in tact
under all circumstances has proved difficult given
that there may be conflicts with namespace prefixes,
or worst, contention for the default namespace.
Our implementation makes a best effort to keep XPath
valid, but there are still some edge cases that trip
it up. We are debating whether to create an XSLT
extension that will enable us to leverage an XPath 2
parser, or to write our own XPath 2 parser in XSLT to
resolve the issue.
Testing The Validation Pipeline
An early challenge that we encountered was that we
needed to develop a method of testing the
validation pipeline. Because validation and our
documentation pipeline both rely on the WADL
normalizer, it is important to ensure that the
output of the normalizer accurately reflects the
intent of the original WADL author. To avoid
regressions as we add new features, we implemented
a functional testing framework that takes
advantage of the xml features of Scala to perform
transformations on simple WADLs and WADL+XSD
combinations and compare those with the expected
result. The following code sample shows one of
these tests.
Figure 28: A WADL normalizer test
scenario ("The original WADL is in mixed path/tree format"){
given("a WADL with resources in mixed path/tree format")
val inWADL =
<application xmlns="http://wadl.dev.java.net/2009/02"
xmlns:xsd="http://www.w3.org/2001/XMLSchema">
<resources base="https://test.api.openstack.com">
<resource path="a/b">
<resource path="c">
<method href="#foo"/>
</resource>
</resource>
<resource path="d">
<resource path="e/f"/>
</resource>
<resource path="g"/>
<resource path="h/i/{j}/k">
<param name="j" style="template" type="xsd:string" required="true"/>
<method href="#foo"/>
</resource>
<resource path="h/i/{j}/k/l">
<method href="#foo"/>
</resource>
</resources>
<method id="foo"/>
</application>
val treeWADL =
<application xmlns="http://wadl.dev.java.net/2009/02"
xmlns:xsd="http://www.w3.org/2001/XMLSchema">
<resources base="https://test.api.openstack.com">
<resource queryType="application/x-www-form-urlencoded" path="a">
<resource queryType="application/x-www-form-urlencoded" path="b">
<resource queryType="application/x-www-form-urlencoded" path="c">
<method xmlns:rax="http://docs.rackspace.com/api" rax:id="foo"/>
</resource>
</resource>
</resource>
<resource queryType="application/x-www-form-urlencoded" path="d">
<resource queryType="application/x-www-form-urlencoded" path="e">
<resource queryType="application/x-www-form-urlencoded" path="f"/>
</resource>
</resource>
<resource queryType="application/x-www-form-urlencoded" path="g"/>
<resource queryType="application/x-www-form-urlencoded" path="h">
<resource queryType="application/x-www-form-urlencoded" path="i">
<resource queryType="application/x-www-form-urlencoded" path="{j}">
<param name="j" style="template" type="xsd:string" required="true"
repeating="false"/>
<resource queryType="application/x-www-form-urlencoded" path="k">
<method xmlns:rax="http://docs.rackspace.com/api" rax:id="foo"/>
<resource queryType="application/x-www-form-urlencoded" path="l">
<method xmlns:rax="http://docs.rackspace.com/api" rax:id="foo"/>
</resource>
</resource>
</resource>
</resource>
</resource>
</resources>
<method id="foo"/>
</application>
when("the WADL is normalized")
val normWADL = wadl.normalize(inWADL, TREE)
then("the resources should now be in tree format")
canon(treeWADL) should equal (canon(normWADL))
}
Notice that the test infrastructure supports the
scenario/given/when/then format of behavioral driven
development.
Future Work
The goal described in section “The Validation Problem” is
not entirely complete because we are still missing
considerable checks on the HTTP response generated by
the REST service. We plan on extending the automata to
account for this. Additionally, we plan on adding
JSONPath and JSON Schema stages as only JSON
well formness is currently tested. We also plan on
adding support for other validation languages in XML
such as RelaxNG and Schematron. Finally, we plan to
pursue some of the extended use cases we discussed in
section “Other Use Cases” such as authorization and
API coverage.
[hREST2008]
Kopecky, J., Gomadam, K., Vitvar, T.: hRESTS: an HTML Microformat for Describing RESTful Web Services. In: The 2008 IEEE/WIC/ACM International Conference on Web Intelligence (WI2008),
Sydney, Australia, IEEE CS Press
(November 2008)
[Jaxrs2009]
M. Hadley and P. Sandoz, JAX-RS:
Java API for RESTful Web Services, Java
Specification Request (JSR), vol. 311, 2009. http://jcp.org/en/jsr/detail?id=311.
[O2007]
L. Richardson and S. Ruby. RESTful Web Services. O’Reilly Media, Inc., May 2007.
[O2010]
Allamaraju, S., and Amudsen, M. RESTful Web Services
Cookbook. O’Reilly. 2010.
[O2011]
Webber, J., Parastatidis, S., Robinson, I.: REST in Practice: Hypermedia and
Systems Architecture. O’Reilly & Associates, Sebastopol (2010).
[Maleshkova2009]
Maria Maleshkova, Jacek Kopecky, and Carlos Pedrinaci. Adapting SAWSDL for Semantic Annotations of RESTful Services. In Workshop: Beyond SAWSDL at OnTheMove Federated Conferences & Workshops, 2009.
[Takase2008]
T. Takase, S. Makino, S. Kawanaka, K. Ueno, C. Ferris, and A. Ryman, Definition Languages for RESTful Web Services: WADL vs. WSDL 2.0, IBM Reasearch, 2008
[WSDL2007]
Chinnici R., Moreau J., Ryan A., and Weerawarana S. Web
Services Description Language (WSDL) Version 2.0. June
2007. http://www.w3.org/TR/wsdl20/
Kopecky, J., Gomadam, K., Vitvar, T.: hRESTS: an HTML Microformat for Describing RESTful Web Services. In: The 2008 IEEE/WIC/ACM International Conference on Web Intelligence (WI2008),
Sydney, Australia, IEEE CS Press
(November 2008)
M. Hadley and P. Sandoz, JAX-RS:
Java API for RESTful Web Services, Java
Specification Request (JSR), vol. 311, 2009. http://jcp.org/en/jsr/detail?id=311.
Maria Maleshkova, Jacek Kopecky, and Carlos Pedrinaci. Adapting SAWSDL for Semantic Annotations of RESTful Services. In Workshop: Beyond SAWSDL at OnTheMove Federated Conferences & Workshops, 2009.
T. Takase, S. Makino, S. Kawanaka, K. Ueno, C. Ferris, and A. Ryman, Definition Languages for RESTful Web Services: WADL vs. WSDL 2.0, IBM Reasearch, 2008