Robie, Jonathan. “XQuery, XSLT and JSON: Adapting the XML stack for a world of XML, HTML, JSON and JavaScript.” Presented at Balisage: The Markup Conference 2012, Montréal, Canada, August 7 - 10, 2012. In Proceedings of Balisage: The Markup Conference 2012. Balisage Series on Markup Technologies, vol. 8 (2012). https://doi.org/10.4242/BalisageVol8.Robie01.
Balisage: The Markup Conference 2012 August 7 - 10, 2012
Balisage Paper: XQuery, XSLT and JSON
Adapting the XML stack for a world of XML, HTML, JSON and JavaScript
XML and JSON have become the dominant formats for
exchanging data on the Internet, and applications frequently
need to send and receive data in many different JSON-based or
XML-based formats, consuming or producing data in JSON, XML, or
HTML. JSON has not yet developed an application stack as mature
as the XML application stack; for instance, there is still no
standard query language, transformation language, or schema
language.
And the XML application stack has not yet evolved to
easily process JSON.
There are several areas where the XML stack should evolve
to better support developers who work with JSON together with
XML, and the features needed to support JSON in XQuery and XSLT
also provide data structures that simplify writing queries and
transformations, and allow more efficient processing of
intermediate results when processing XML. As JSON becomes
increasingly common in databases, and is exchanged among
servers, these same kinds of tools may even become important in
environments that use only JSON.
This paper focuses on queries and transformations, looking
at JSON support in several NoSQL databases, the JSONiq proposal
(which adds JSON objects and arrays to XQuery), and the XSLT
maps proposal (which adds maps that can represent JSON objects
and arrays).
At the time of writing, the W3C XML Query Working Group and the
W3C XSL Working Group are considering several proposals for
supporting JSON.
The Working Groups expect to agree on a common solution that can
be used in both XSLT and XQuery.
In the early days of XML, many in the XML community saw it
as a universal format that would be used to represent most kinds
of data exchanged among programs, allowing many different kinds of
information to be processed in the same way.
XML provides a way to label information from diverse
data sources including structured and semi-structured
documents, relational databases, and object
repositories.
The Extensible Markup Language, XML, is having a
profoundly unifying effect on diverse forms of
information. For the first time, XML provides an information
interchange format that is editable, easily parsed, and
capable of representing nearly any kind of structured or
semi-structured information.
— "Quilt: An XML Query Language for Heterogeneous Data Sources", 2000.
But less than a decade after XML 1.0 became a W3C
Recommendation, some people were concluding that XML was not the
best way to exchange traditional program data on the
Internet.
Unfortunately, XML is not well suited to
data-interchange, much as a wrench is not well-suited to
driving nails. It carries a lot of baggage, and it doesn't
match the data model of most programming languages. When
most programmers saw XML for the first time, they were
shocked at how ugly and inefficient it was. It turns out
that that first reaction was the correct one. There is
another text notation that has all of the advantages of XML,
but is much better suited to data-interchange. That notation
is JavaScript Object Notation (JSON).
JSON is a better data exchange format. XML is a better
document exchange format. Use the right tool for the right
job.
— "JSON: The Fat-Free Alternative to XML", 2006.
In many environments, XML and HTML are used to represent
documents, and JSON is used for traditional data exchange. As more
and more data is exchanged, stored, and queried as JSON, XML tools
need to evolve to allow JSON and XML to be processed together.
And adding support for JSON is useful even for XML data, because
JSON's data structures are sorely missing in both XSLT and XQuery,
and can simplify many transformations and queries.
This paper explores how an XML stack can be adapted to support
a world of HTML5, JavaScript, and JSON, then explores two existing
proposals that provide support for JSON: (1) the XSLT 3.0 maps
proposal, which adds maps to XSLT and provides functions to convert
JSON to and from these maps, and (2) JSONiq, which extends XQuery to
add JSON objects and arrays. After that, a comparison of the two
proposals is given, along with some thoughts about the issues that
should be resolved as the W3C XSL Working Group and the W3C XML
Query Working Group seek to develop a common proposal.
This talk represents the views of the author, not those of
EMC Corporation, the W3C, or the XML Working Group. Most of these
views were formed in conversation with Dana Florescu, Michael Kay,
Ghislain Fourney, John Snelson, Mary Holstege, Matthias Brantner,
Till Westmann, Andrew Eisenberg, and others whose views continue
to inform me.
The Web in 2012: HTML5, JavaScript, and JSON
The XML community has long argued that programs should
exchange both documents and program data using text-based data
formats that are readable, platform-neutral, based on open
standards, separate presentation from content, and are
optimized for data reuse and long-term storage of data. This
argument has largely been won. However, XML is only one of
several formats that are being used for this purpose.
In the early days of XML, many spoke of it as a
universal data format, or a universal
hub format, and some hoped that XHTML would finally
unify the Web, with XML as the foundation. But XHTML was not
well supported by some browsers, and was never widely accepted
as a replacement for HTML 4. Instead, the HTML community has
moved strongly in the direction of HTML5.
Even for data exchange, many JavaScript programmers decided
that XML was too difficult to use in JavaScript programs,
opting for JSON instead. While XML won the argument that data
should be exchanged using text-based formats with the
characteristics listed above, we now have three dominant
formats: HTML, XML, and JSON. They are frequently used
together. Few tools are designed to work equally well with all
three formats, but many developers are expected to.
In recent years, the Web has been moving strongly in the
direction of HTML5, JavaScript, and JSON
and a new generation of databases, designed for distributed
processing of massive amounts of data, uses JSON as the native
data model. Ironically, JSON is now widely used for the
very use cases highlighted in Jon Bosak's 1997 paper,
XML, Java, and the future of the Web, which was
written to promote XML. JSON was designed as a programming
language-independent representation of typical programming
language data structures, and in many languages, a simple
library call can convert JSON to programming language
structures, or programming language structures to JSON. For
this kind of data, JSON programming is dramatically simpler
than XML programming, except when you need queries,
transformations, or schema validation.
But JSON does not exist in a vacuum, and it frequently
needs to be used together with mixed content, typically
represented as HTML or XML. A single application may often use
several Web interfaces, some XML-based, others JSON-based, and
combine data from the two, creating results in various
formats. And even as XML becomes less common in Web
interfaces, it continues to be important for documents and for
managing and generating content on the server, to be combined
with other data and exchanged in other formats. XML tools are
particularly powerful for complex data integration tasks
involving heterogeneous data, and they can handle HTML well,
but they need to be extended to better support JSON. This will
benefit both the JSON and XML communities.
XML has a mature tool stack that does not yet exist for
JSON, including schema languages, XSLT, and XQuery. Many XML
developers find these tools sorely missing when they work with
JSON, but it's not clear that the JSON community feels a strong
need for most of these tools. Many query languages have been
developed for JSON, a few schema languages and transformation
languages have also been developed, but have not been widely
used.
Using schemas to enforce contracts is just as relevant for JSON as
it is for XML, but there is little enthusiasm in the JSON
community for schema languages, especially complex schema
languages. JSON Schema, perhaps the most widely used JSON schema
language, provided validation, and also added "formats", which
allow for validation of simple types such as
date-time, date, time,
etc. JSON Schema is supported by several tools, and was written up
as an IETF draft, but the draft expired in 2011.
As a result, there is no standard way to support schema validation
or validation of these data types in JSON. That makes it difficult
for JSON interfaces to support declarative contracts via schemas.
The JSON community generally believes that JSON frequently
needs to be transformed to and from other formats, especially HTML
and XML, but JSONT, a lightweight XSLT-like transformation
language designed in 2006, does not seem to have gained much
traction, nor have any of the alternatives that have emerged. This
may be partly because JavaScript and many scripting languages are
fairly powerful for many common simple transformations. A number
of libraries and other approaches have emerged for using XSLT to
transform JSON, and are popular in the XML community among those
who also work with JSON; it is too early to tell how widely they
will be adopted in the JSON community.
Because NoSQL databases that use JSON as their native data
model have gained significant traction in recent years, JSON query
languages have gained much more traction, but no standard JSON
query language has emerged. Standards are not as deeply embedded
in JSON culture as they are in XML culture, and it is more
difficult to gain agreement on a standard across the industry.
A variety of approaches to querying JSON are used, including
template-based queries (e.g. Mongo Query Language), SQL-like query
languages (e.g. UnQL, HiveQL, YQL), procedural data flow languages
(e.g. Pig Latin), functional data flow languages (e.g. Jaql), and
simply using MapReduce libraries from conventional programming
languages (e.g. Google BigTable).
To support queries, these languages often extend JSON with
additional data types, such as date, object id, binary data,
regular expression, or more specific numeric types such as int32,
int64, or double.
The following queries illustrate the range of query
languages that are used for querying JSON.[1]
Queries in JSON Query Languages
Mongo Query Language: a template-based language for search/retrieval[2]
// select * from things where x=3 and y="foo"
db.things.find( { x : 3, y : "foo" } );
// select * where j<> 3 and k>10
db.things.find({j: {$ne: 3}, k: {$gt: 10} });
// select * where a=1 or b=2
db.foo.find( { $or : [ { a : 1 } , { b : 2 } ] } )
// An UPSERT: Incrementing a counter on a webpage.
UPDATE abc SET abc.n=abc.n+1 WHERE abc.page=="/page/one"
ELSE INSERT {page:"/page/one", n: 1, create_time: 1234567};
SELECT FROM abc;
import myrecord;
countFields = fn(records) (
records
-> transform myrecord::names($)
-> expand
-> group by fName = $ as occurrences
into { name: fName, num: count(occurrences) }
);
read(hdfs("docs.dat"))
-> countFields()
-> write(hdfs("fields.dat"));
Maps and Arrays, a missing piece in XQuery and XSLT
Maps and arrays, under various names, are available in most
modern programming languages, but until recently, they were
absent from both XQuery and XSLT. This came from a basic design
decision: XML is the complex data structure in these languages,
and we felt that no other complex data structure was
needed. While this worked well for most things, it made some
kinds of queries and transformations needlessly complex for users
to write, and complicated the design of the languages.
Maps and arrays are simple data structures, much simpler
than XML, and adding them to XQuery and XSLT does not greatly
change the complexity of the two languages. And maps and arrays
add significant new features to both languages:
Lightweight data structures that do not have
the overhead associated with namespace processing, element
construction, order preservation, or whitespace processing
rules.
Data structures that can associate additional
data with an node, without losing the original identity of the
node. This is particularly helpful in function parameters and
returns. (Element construction in XQuery and XSLT loses the
original identity of the items used to construct the
element.)
Nested arrays that can represent multiple
sequences returned from a function, mathematical matrices,
sparse matrices, etc.
Data structures that can be used to describe
intermediate results of XQuery expressions, such as the tuple
stream in FLWOR expressions. (The notation used to describe the
tuple stream in the current XQuery specification could easily
be changed to maps.)
All of these things can be simulated with XML, but doing so
introduces conceptual overhead for those who write queries or
transformations, and system overhead that can affect the
efficiency of queries.
If producing modified copies of a map is easy and
efficient, maps add another useful feature: complex data
structures that can track information encountered during a query
or transformation. For instance, a reporting application can keep
running totals and summaries by creating new map instances to
reflect changing information.
The XSLT 3.0 Maps Proposal
The XSLT 3.0 maps proposal, which is new in the July 2012
Working Draft of XSLT, was motivated by streaming use cases,
which require complex data structures that can be used to
remember what has been seen in the document, and also provides
support for JSON. It extends the type system, data model, and
syntax of XPath 3.0 to support maps, which are represented as
function items in the data model.[7]
It does not provide explicit support for arrays, but supports
similar functionality using maps with integer-valued keys.
The XSLT proposal extends the syntax of XPath's
ItemType to allow support map types.
For instance, MapType can be used to specify the type of a function parameter. Here is the signature of
a function that uses a map to specify parsing options.
parse-json($json-text as xs:string,
$options as map(*)) as item()?
There is no way to declare the type of a map, and the type
of a map depends on its current contents. For instance,
map(xs:integer, element(employee)) matches a map if
all the keys in the map are integers and all the values are
employee elements. If a new entry with a different key type or
value type is added, the type of the map changes.
The maps proposal adds a new kind of primary expression to
XPath in order to construct a map.
In the XSLT 3.0 maps proposal, a map is a function from
keys to associated values, and is represented as a function
item. The function map:get($map, $key) returns the
value associated with a given key.
The function signature for a map is function($key as
xs:anyAtomicValue) as item()*, and calling a map function
returns the value for that key (thus, $map($key) is
a synonym for map:get($map, $key). If
$map is bound to the map shown above, the following
expressions are equivalent, they each evaluate to "Tuesday".
map:get($map,"Tu")
$map("Tu")
Maps have no identity; the contents of two maps can be
compared, but there is no way to distinguish two maps with the
same content.
All values in XSLT are immutable, but functions are
provided to create new maps that differ from an existing map by
removing an entry, adding an entry, or changing the value of an
entry.
The following table provides a brief synopsis of the
functions provided for maps.
Table I
Map functions in the XSLT 3.0 maps
proposal
map:new
Creates a new map: either an empty
map, or a map that combines entries from a number of existing
maps. Allows a collation to be specified.
map:entry
Creates a map that contains a
single key/value pair. Useful for creating maps with
map:new
map:get
Returns the value associated with a key.
map:keys
Returns the keys found in a map.
map:contains
Tests whether a supplied map contains an entry for a given key.
map:remove
Constructs a new map by removing an entry from an existing map.
map:collation
Returns the URI of a given map's collation.
fn:deep-equal2
Determines whether two
sequences are deep-equal to each other; this function extends
fn:deep-equal to support sequences that contain
maps.
The map:new function is used to create new
maps from existing ones by specifying a sequence of maps. The
newly created map contains every key/value pair that occurs in
one of these maps; if a given key occurs in more than one map,
its value in the newly created map is taken from the last map
that contains a value for this key. The following examples show how map:new and map:remove are used to create modified versions of maps.
The following example, taken from the XSLT 3.0 Working Draft, uses maps and xsl:iterate to find the highest earning employee in each department, in a single streaming pass
of a document containing employee records.
The XSLT maps proposal also adds two functions,
parse-JSON and serialize-JSON, that
convert between serialized JSON and XSLT
maps. parse-JSON converts JSON arrays are converted
to maps with integer-valued keys.
let $m := parse-json('{"x":1, "y":[3,4,5]}') return $m("y")(2) returns 4e0.
JSONiq: Extending XQuery with Maps and Arrays
The JSONiq proposal extends XQuery to add support for
JSON. It was primarily motivated by the need for a JSON query
language, and the need for a single language that can query JSON,
XML, and HTML. JSONiq extends the type system, data model, and
syntax of XQuery to support JSON objects[9] and
arrays. JSONiq defines two profiles: one is a strict superset of
XQuery that adds support for JSON, the other is a pure JSON query
language with no XML constructs.
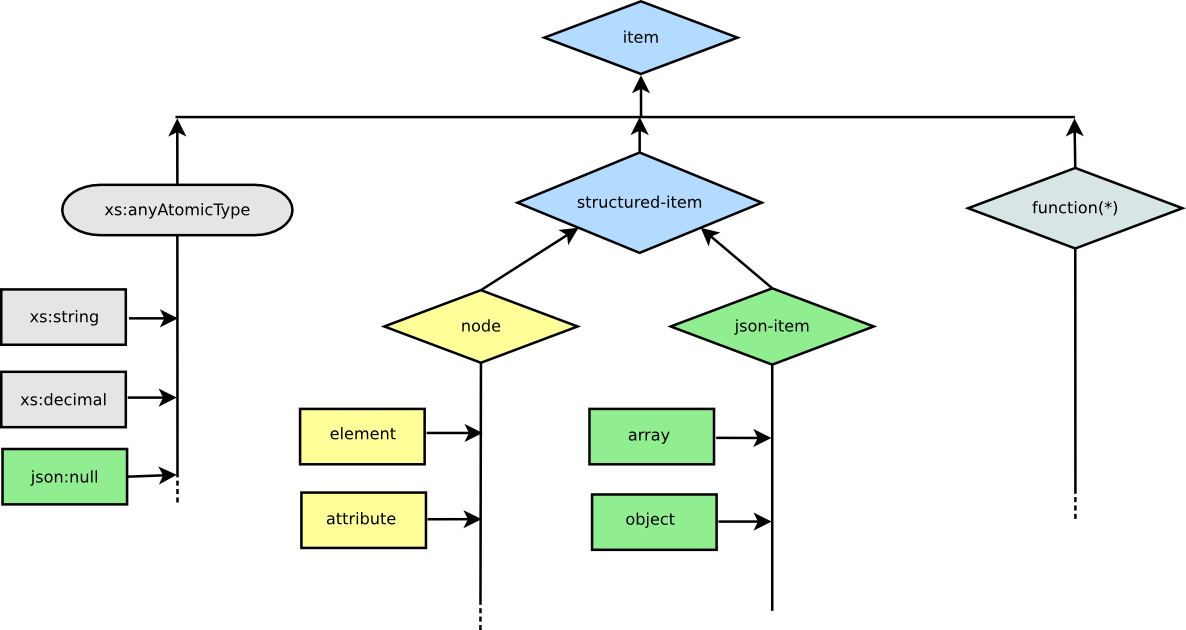
The following diagram shows JSONiq extensions to the data
model in green.
Figure 1: JSONiq Data Model
object represents a JSON object, array represents a JSON array. Both are derived from json-item. structured-item is an abstract base class for both node and json-item.
json:null is an atomic data type that represents JSON nulls.
Like XDM 3.0 nodes, a JSON item has identity, and it can
be serialized. However, the identity of a JSON item is used only
to support updates. Like XSLT maps, the contents of JSON items
can be compared, but there is no way to distinguish two items
with the same content.
JSONiq extends the syntax of XPath's ItemType
to support the types of JSON items.
Both objects and arrays compose with existing XQuery expressions; for instance, the
following example uses an XQuery range expression to construct an array containing
five integers:
[ 1 to 5 ]
Here is the result of the above query:
[ 1, 2, 3, 4, 5 ]
The following example constructs an object from the values in a sequence:
{
for $d at $i in ("Sunday","Monday","Tuesday","Wednesday","Thursday","Friday","Saturday" )
return $d : $i
}
In JSONiq, an array contains a sequence of items, and an
array is itself an item. JSONiq also supports JSON nulls. In the
following array constructor, jn:null() creates a
null value.
Navigation in objects and arrays is done using "selectors",
which use function call syntax as in the XSLT 3.0 maps proposal.
An object selector has the function type function($key as
xs:string) as item()?. An object selector returns the
value associated with a given key, as in the following
example.
An array selector matches the function type
function(xs:integer) as item()?. An array selector
returns the value found at a given position, as in the following
example:
{ "store number" : 1, "state" : CA },
{ "store number" : 2, "state" : CA },
{ "store number" : 3, "state" : MA },
{ "store number" : 4, "state" : MA }
The following query groups by state, then by category, then lists individual products
and the sales associated with each.
{
for $store in collection("stores")
let $state := $store("state")
group by $state
return {
$state : {
for $product in collection("products")
let $category := $product("category")
group by $category
return {
$category : {
for $sales in collection("sales")
where $sales("store number") = $store("store number")
and $sales("product") = $product("name")
let $pname := $sales("product")
group by $pname
return $pname : sum( $sales("quantity") )
}
}
}
}
}
Beyond what has been discussed in this section, JSONiq adds functions for parsing
and serializing JSON, a syntax for JSON updates, a function library for managing objects
and arrays, and rules for combining XML and JSON. See JSONiq for further information.
Comparing the XSLT 3.0 Maps Proposal to JSONiq
The XSLT 3.0 Maps proposal and JSONiq have similar
functionality. They each extend the XPath 3.0 type system, data
model, and syntax, but they do it in incompatible ways. The XSL
Working Group and XML Query Working Group expect to agree on a
common solution that can be used in both XSLT and XQuery. This
section explores some of the similarities and differences between
the two proposals.
XSLT maps are extremely similar to JSONiq objects, but they
do differ in a variety of ways. The following list summarizes
these differences.
Maps
In the XSLT 3.0 maps proposal, maps are
functions. In JSONiq, they are structured items, similar to XML
nodes, with accessors defined in the data model. Both proposals
use function notation to find the value associated with a key;
in JSONiq this is done by overloading the function call syntax
for objects and arrays.
If maps are modeled as functions, the properties of maps
still need to be clearly described in the data model, much as
they are for elements and attributes, for the sake of
implementations. If maps are modeled as data, the language
description needs to explain the use of function call syntax,
or a different approach must be used to find the value
associated with a key.
In the XSLT 3.0 maps proposal, a map can be
passed as a parameter where a function is expected. In JSONiq,
a map must first be wrapped in an inline function, which can be
passed as a parameter where a function is
expected.
The XSLT 3.0 maps proposal makes it easy to
create a new copy of a map that is modified by adding an entry,
changing the value of an entry, or removing an entry. This is
not as easy in JSONiq. JSONiq provides operations to update the
contents of a map in place. This is not possible in XSLT (which
does not have updates).
Maps should support both models. Updates are needed for
conventional database operations, modified copies are needed
for XSLT and for XQuery implementatinos that do not provide
updates.
In the XSLT 3.0 maps proposal, maps have no
identity. In JSONiq, maps have identity, but it is used only to
support updates. (XSLT does not have updates, and does not need
this functionality). To reduce complexity and simplify query
optimization, neither proposal allows XPath operations that
expose the identity of maps, such as is,
<<=, >>,
union, intersect, and
except operators.
In the XSLT 3.0 maps proposal, the value of a
map entry is an arbitrary sequence. In JSONiq, the value of a
map entry is a single item; if the value is a sequence, it is
placed in an array, as it would be in JSON.
In the XSLT 3.0 maps proposal, a key can have
any atomic type, and the keys in a given map may have different
types, which need not be mutually comparable (e.g. one map may
have keys of type integer, string,
and boolean). The type of a map depends on the
types of its keys and values at any given time. In JSONiq, a
key is always a string, as it is in JSON.
In the XSLT 3.0 maps proposal, keys are
compared using the default collation, and a map can be given a
collation, so that keys considered equivalent in a given
language can be made equivalent. In JSONiq, all maps use the
Unicode codepoint collation to ensure that they are compared
the same way in all environments.
JSONiq maps use a constructor syntax that
closely resembles the syntax of JSON maps in the same way that
XQuery direct element constructors resemble XML elements. The
XSLT 3.0 maps proposal uses a syntax more like computed element
constructors, introducing a constructor with a keyword, and
uses := as a delimiter between name/value pairs,
instead of the : delimiter used by
JSON.
JSONiq has arrays, the XSLT 3.0 proposal does not. This is
perhaps the most significant difference between the two
proposals. The XSLT 3.0 proposal uses maps to represent JSON
arrays; for instance, the parse-json() function
converts the JSON text ["a", "b", null] to the map
map{1:="a", 2:="b", 3:=()}, and does not support
arrays in XPath per se. If a transformation creates a new copy of
the map, removing one of the entries, the positions of the other
entries are not adjusted; for example, consider the following
expression:
let $j := parse-json('["a", "b", null]')
return map:remove($j, 2)
This expression evaluates to a map with entries in position
1 and 3, but not in 2:
map{1:="a", 3:=()}
JSONiq does not have this problem; deleting an item from an
array moves all subsequent items one position to the left.
Beyond the differences mentioned above, the main
differences involve the functions associated with maps and arrays
in the two proposals.
Arrays and Sequences
In JSONiq, an array is a single item, which allows an array
to be a member of an array. In the XSLT 3.0 maps proposal, a map
is used to simulate an array. In either case, an array is an item
that can occur in a sequence, and items are retrieved using
function call syntax (e.g. $a(1)), not the subscript
operator (e.g. $a[1]). Functions, operators, and
expressions that operate on sequences all treat an array as a
single item. For instance, the following expression returns a
single item:
for $i in [1, 2, 3]
return $i
The result of the above query is the array [1, 2,
3], not the sequence 1, 2, 3. JSONiq provides
the members() function to convert an array to a
sequence:
for $i in members([1, 2, 3])
return $i
The result of the above expression is 1, 2,
3.
In the same way, the expression [1, 2][1] is
not equivalent to the expression [1, 2](1). The array
selector (1) returns the first member of the
sequence, which is 1. The positional predicate
[1] returns the first item of the sequence. In XPath,
an item is identical to a singleton sequence containing that item,
so [1, 2][1] is equivalent to ([1,
2])[1], which returns the first item in the sequence:
[1, 2].
Some people would like most functions, operators, and
expressions to treat arrays and sequences in the same
way. However, the semantics of sequences is fundamental to the
design of XQuery, XPath, and XSLT, and sequences have semantics
that are quite different from arrays. For instance, in these
languages a single item is indistinguishable from a sequence
containing a single item, most languages clearly distinguish an
array containing a single item from an item. Similarly, sequences
do not nest, and are automatically flattened. Arrays nest, and are
not flattened. Because sequences and arrays have significantly
different semantics, it is not clear whether it is possible to
make functions, operators, and expressions treat them the same way
without introducing inconsistencies. The two Working Groups should
explore this question.
Moving Forward
If support for JSON is added to both XSLT and XQuery,
developers can query or transform XML, HTML, and JSON to produce
XML, HTML, or JSON. The XSLT 3.0 Maps proposal and JSONiq are more
similar than different, and should be combined, retaining the best
features of each. The XSL and XML Query Working Groups have
started this effort. This paper has attempted to sketch the
differences between the two proposals, and suggest some ways that
they can be combined. This will be helpful to XML developers who
also need to process JSON, but also to XML developers who need
simple, lightweight data structures that preserve identity, and to
the Working Groups as we design extensions to our
languages.
It is too early to say how interesting this work will become
to the JSON community. As JSON moves beyond the browser into
databases and enterprise data exchange, the lack of a mature
application stack like the XML application stack becomes more
painful, but the JSON community is extremely reluctant to embrace
the complexity of XML Schema and other aspects of the XML
application stack. At this point, the strongest interest seems to
be in query languages. For the JSON-only community, JSONiq has a
profile that removes support for XML, resulting in a much smaller,
simpler language that supports only JSON. Standard support for a
broader set of datatypes would also be extremely helpful for JSON
developers, who routinely work with dates, URLs, and other
datatypes that are not directly supported in JSON, as would a
simple schema language. Because of the strong desire for
simplicity in the JSON community, it is unlikely that they will
simply adopt the XML application stack without modification, but
the JSON community may benefit by learning from the work that has
already been done by their XML cousins.
[XQuery 3.0] Jonathan Robie, Don Chamberlin, Michael Dyck, John Snelson.
XQuery 3.0: An XML Query Language.
W3C Working Draft 13 December 2011. [online].
http://www.w3.org/TR/xquery-30/.
[XPath 3.0] Jonathan Robie, Don Chamberlin, Michael Dyck, John Snelson.
XML Path Language (XPath) 3.0.
W3C Working Draft 13 December 2011. [online].
http://www.w3.org/TR/xpath-30/.
[XDM 3.0] Norman Walsh, Anders Berglund, John Snelson.
XQuery and XPath Data Model 3.0
W3C Working Draft 13 December 2011. [online].
http://www.w3.org/TR/xpath-datamodel-30/.
[Jaql] Kevin S. Beyer, Mohamed Eltabakh, Vuk Ercegovac, Rainer Gemulla, Carl-Christian Kanne,
Fatma Ozcan, Andrey Balmin, Eugene J. Shekita.Jaql: A Scripting Language for Large Scale Semistructured Data
Analysis.
[online]
http://www.mpi-inf.mpg.de/~rgemulla/publications/beyer11jaql.pdf
[cosql] Erik Meijer, Gavin Bierman. A co-Relational Model of Data for Large Shared Data Banks. ACM Queue, March 2011, volume 9, number 3. http://queue.acm.org/detail.cfm?id=1961297
[1] A
detailed comparison of these languages is beyond the scope of
this paper.
[7] Because XPath 3.0 is jointly owned with the XML Query
Working Group, the two Working Groups have committed to work
together to create a joint proposal, but this is not yet
reflected in any public document.
[9] JSON
calls maps objects, as does JavaScript. In this paper, the term
object always refers to a map, rather than the objects used in
the object oriented paradigm.
Jonathan Robie, Don Chamberlin, Michael Dyck, John Snelson.
XQuery 3.0: An XML Query Language.
W3C Working Draft 13 December 2011. [online].
http://www.w3.org/TR/xquery-30/.
Jonathan Robie, Don Chamberlin, Michael Dyck, John Snelson.
XML Path Language (XPath) 3.0.
W3C Working Draft 13 December 2011. [online].
http://www.w3.org/TR/xpath-30/.
Norman Walsh, Anders Berglund, John Snelson.
XQuery and XPath Data Model 3.0
W3C Working Draft 13 December 2011. [online].
http://www.w3.org/TR/xpath-datamodel-30/.
Kevin S. Beyer, Mohamed Eltabakh, Vuk Ercegovac, Rainer Gemulla, Carl-Christian Kanne,
Fatma Ozcan, Andrey Balmin, Eugene J. Shekita.Jaql: A Scripting Language for Large Scale Semistructured Data
Analysis.
[online]
http://www.mpi-inf.mpg.de/~rgemulla/publications/beyer11jaql.pdf
Erik Meijer, Gavin Bierman. A co-Relational Model of Data for Large Shared Data Banks. ACM Queue, March 2011, volume 9, number 3. http://queue.acm.org/detail.cfm?id=1961297